

We try very hard to fill DeepCrawl (now Lumar) with useful features. And it’s very rewarding when we occasionally hear our customers go ‘oooh’ on demos.
So, it was only right that we dedicate a post to 10 of the best things you can do with our time-saving, hard-working, no-messing tool. We hope you’ll like them as much as our existing clients do.
1. Run many crawls simultaneously
Crawl several websites or run several crawl types at once… without crashing your computer. Because DeepCrawl is cloud-based, you can run up to 20 crawls concurrently. And if you need more, just ask.
2. Collaborate with shared reports and tickets
Delreegation is the key to stress-free, time-saving projects. If you’re lucky enough to have a crack team of SEOs at your disposal, then DeepCrawl will allow you to share reports with them via a read-only link, assign actionable tickets (called Issues) to your colleagues, then mark when an action is complete.
To create an issue from any report, click the blue Issues link on the right hand side of the screen.
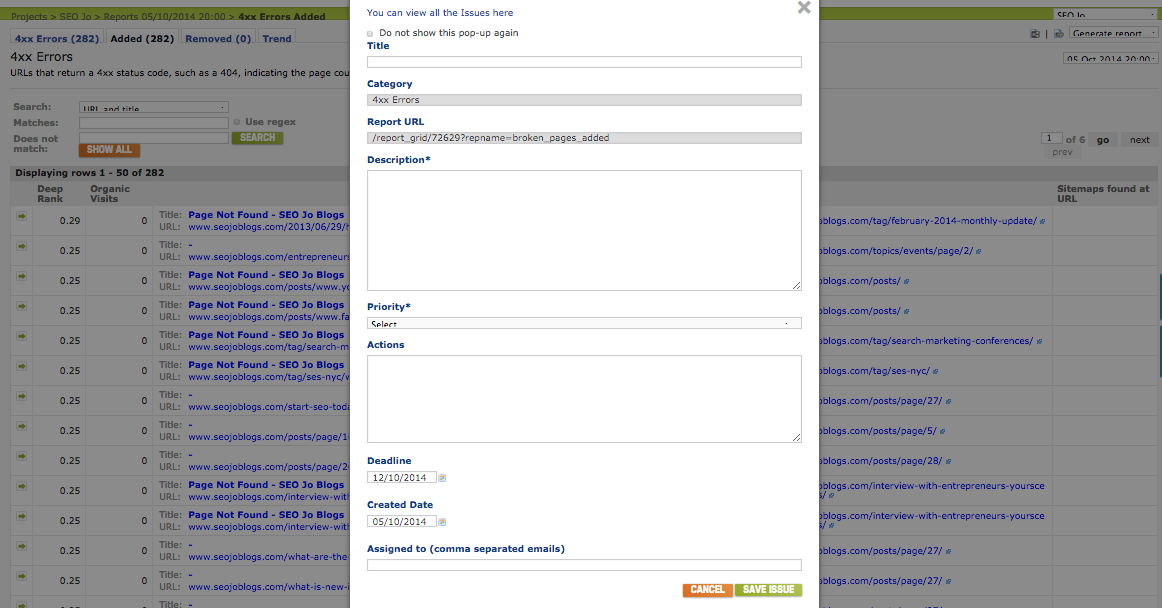
Suddenly that nightmare audit doesn’t seem so horrifying…
3. Monitor trends between crawls
No crawl works in isolation. Compare each crawl with its predecessor(s) to track how your site is performing over a longer period of time – not just how it’s performing at the moment of the crawl.
This functionality applies to all of our crawl types – including universal, list and backlinks.
The standard mini-trend graphs only show the last 30 data points, but you can see the full history if you expand to the full trend:

4. Customize your reports with branding/white-labelling
Your brand is integral to your business, which is why DeepCrawl’s interface and reports can be customized with your own logo and color scheme. You can even set your own domain name to be included in shared report links.
5. View granular data for any URL on your site
Isn’t it frustrating when you have a little bit of information, but not the whole picture? Wouldn’t it make your life so much easier if you had all the information you needed in one place, for any URL in your website, at the click of a button?
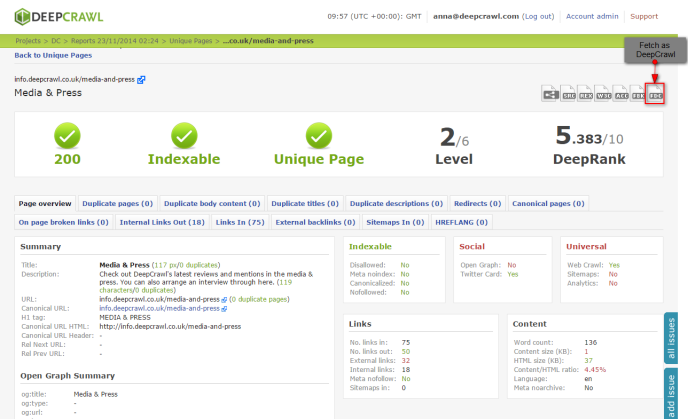
Well, click any URL in a DeepCrawl report and you can see full details for that page – we call it our page detail view.
If it’s hreflang information you need, then click on any URL to see what international configuration is set for that page, and whether there are any gaps, within seconds:

Looking for backlink data? DeepCrawl will show you source URLs, anchor text and follow/nofollow status of backlinks to individual pages:
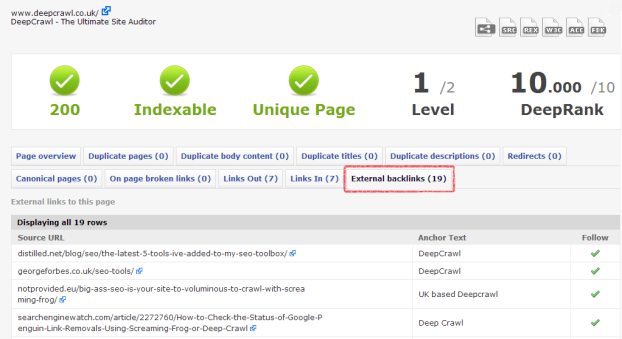
You can replicate this level of detail for every type of DeepCrawl report you can think of.
6. Fetch as DeepCrawl
Test individual URLs, write custom extractions, and test rewrites.
Want to extract number of products across hundreds of 1000s results pages? Now you can pre-validate the REGEX using Fetch as DeepCrawl just so you don’t waste credits.
Moreover you can now test inclusions/exclusions, validate response from multiple country IP addresses or pretest your rewrite rules or basic authentication. Fetch as DeepCrawl let’s you see what can’t be seen with the naked eye.
Find Fetch as DeepCrawl linked from the top-right-hand corner of any page details view.
7. Spot patterns sooner, solve issues faster
As SEOs, it’s our job to spot patterns and act on them. With our Site Explorer tool, spotting those patterns becomes easier than ever before.
Browse all your report data, summarised by folder paths, and use the modes drop down to spot patterns for different types of problems. This is particularly useful if the site you’re working on includes multiple sub-domains.
8. Identify broken Linked-NON-HTML files
DeepCrawl enables you to check HTTP response codes of the non-HTML (e.g. PDF, images, mp3s, etc). Simply check the ‘Crawl non-html file types’ option in Advanced Settings.

9. Crawl faster, get more done
We know you’re busy. And we know you want your SEO tools to be as fast, efficient and powerful as they can be. Which is why, if you have robust web hosting, you can set DeepCrawl to crawl a site much faster than the default five URLs per second.
Try changing the Crawl Rate to a higher value, or removing completely to find how fast you can go.

10. Seize control with customized reports
Off-the-shelf tools often have a lot of limitations. Why be limited to someone else’s opinion of what you need? With DeepCrawl’s precision settings, you can customize reports to run with your own values, including the precision of our duplication detection system:
Fancy seeing all of this in action? We’d be happy to give you a demo – give us a call on +44 (0) 203 478 8652 or email them at info@deepcrawl.com.
If you don’t yet have a DeepCrawl account, you can request a live demo here on a site you’re working on, or log in now to get started.



