

JavaScript and SEO have been arch enemies for a very long time. It is not news to any SEO that Google does and always has struggled to index JavaScript content. Usually the JavaScript would only be a small part of the page or a widget and therefore we could ignore it, as Googlebot would understand the content surrounding the JS and could index the page and understand its meaning anyway.

What happens if the whole page or a large chunk of the content we want indexing is rendered in JS? Even if it looks great and runs fast and smoothly, although it is slowly getting better, Google still won’t be able to crawl your content. Up until 2014 people were suggesting all sorts of fall-back methods, trying to serve up an HTML version to the search engines that retained some of the functionality of the JS version being offered to users.
The way I would sum up this ongoing debate up is as follows:
- Historically Google could not read JavaScript/AJAX.
- Google now claims it can.
- SEO’s still find issues with it.
- There is evidence to suggest Google has dramatically improved rendering JS.
Now we have Angular JS, this is a framework for building dynamic web apps that use HTML as a base language. Put simply, Angular, injects HTML into an already loaded page, meaning that clicking on a link doesn’t reload the page, it simply uses the framework to inject a new set of HTML to serve to the user. This means the page doesn’t have to reload and the website is significantly faster and saves the developer time as considerably less code has to be written.
Again however, as it is a JavaScript framework, it is something that SEOs are struggling to use. A lot of examples around the web see entire Angular JS websites with just the homepage indexed or not indexed at all, even though Angular JS is a framework that is actually developed by Google. Well, we built one here at TransferWise that is indexed.
If we look at this historically (Angular was launched in 2009), we see a similar timeline to that of JavaScript and SEO:
- Google releases Angular, web devs rejoice!
- SEO people despair.
- Micro-industry arises around pre-rendering (companies like io and Brombone) to help SEOs with Angular JS indexation problems.
- Google announces its spiders will support Angular JS and SEOs celebrate.
Search Console even shows you how Googlebot sees the page, and compares it to how users might see it in a browser:
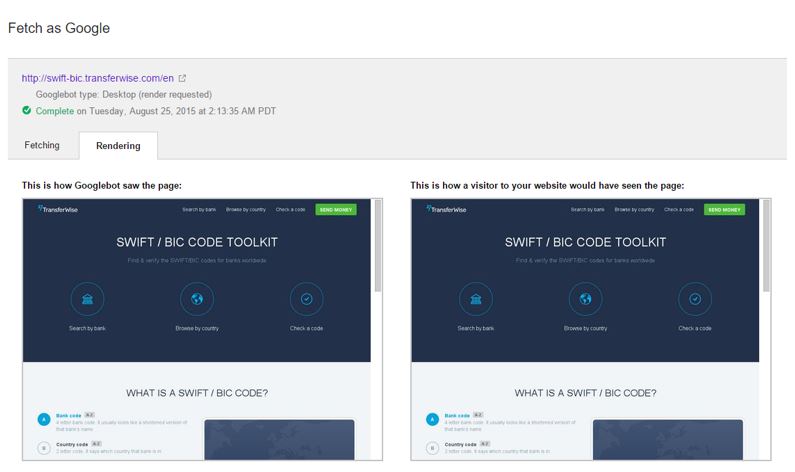
Evidently there is no problem.
Although this appears to be the case, it isn’t. Because it is really hard to find an indexed site that is built with Angular, and there are a lot of people seeking help on the matter. Here is how we did it.
First things first
First, we worked on removing the forced hashes that Angular has set as default.
For example, from an SEO as well as UX point of view, we would recommend a TLD to lead into category pages and then follow into product/content pages. The URL structure should match the most common path that the user follows to reach a page:
- com/
- com/category/
- com/category/page/
By default, however, Angular sets your pages up as such:
- com
- com/#/category
- com/#/page
My understanding is that the hash bang allows Angular to know which HTML elements to inject with JS. Here is quite a good guide on how to fix this issue: https://scotch.io/quick-tips/pretty-urls-in-angularjs-removing-the-hashtag.
We also had some issues with relative URL’s:
Writing these as “<a href=”en/countries/united-kingdom”>…</a>”, when they should have been <a href=”/en/countries/united-kingdom”>…</a>. Although everything was seemingly fine for the user, when crawling this with a bot, the strings in the links were appending to whatever the URL already was. So, for example, the homepage link in the main navigation would append an extra “/en” to the URL, rather than just pointing to itself. This meant that crawling the site gave you an infinite list of URLs with more and more subfolders. (Just adding this as a side note as it is something you might want to test for).
Last but not least
Lastly, there was still the biggest problem to tackle: he fact that Google struggles with Angular. Initially we built the website, made the URLs nice and neat and then waited. Any SEO will tell you how fast Google can crawl a website: if it takes longer than a couple of days once you have submitted the site to Search Console, there is a problem.
We tried submitting a comprehensive sitemap and submitting individual sitemap style pages to Search Console in the hope that this would help. And although Google managed to find around 200 of the ~25,000 pages, it struggled to do any more than that, even with repeated submissions.
What did we do?
We pre-rendered. Luckily we had the expertise in-house to do this and used phantom JS to do so. What this enabled us to do was pre-render the Angular server-side and direct Google to that version of the page, whilst sending the user directly to the Angular version.
If your server can’t handle the crawlers’ requests, this can result in an increase in server errors seen by the search engine. One solution to this is to pre-render in advance server-side, so that when crawlers reach the server, the page is already rendered. We didn’t worry with this, however, as our loading servers managed the load.
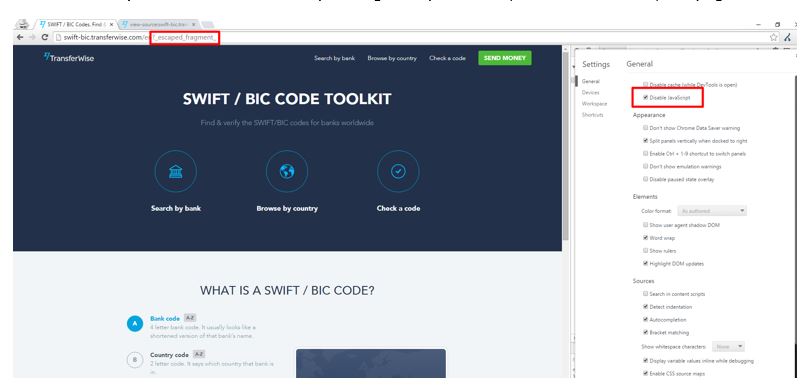
An alternative method is to add the fragment Meta tag to your pages. When this is present, Google passes a URL string parameter that looks like: ?_escaped_fragment_. What this does is redirect Googlebot to the server in order to fetch a pre-rendered version. Although this isn’t how we decided to solve the problem, we actually have this enabled and the really cool thing is thing is that you can see it in action.
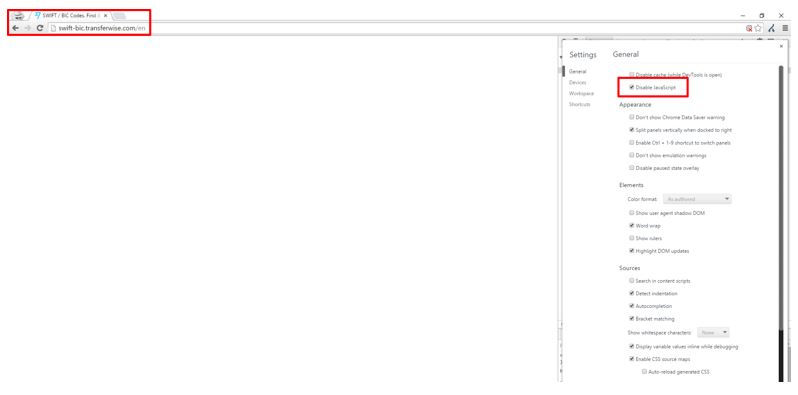
If through chrome we turn JavaScript off and try and load the page, this is what we get:
If we do exactly the same with the escaped fragment parameter, mentioned above, the page loads:
This is something you can try for yourself at home on any URL from our website.
In summary, you can use Angular JS if you are an SEO, you just need to know what to look out for to make the website crawlable. However, a note of caution: Google have said they will not support this at some point in the future, however it doesn’t matter if you pre-render as all Google will see is static HTML.
As far as testing is concerned, just make sure you crawl as Googlebot, otherwise you usually get stuck on the homepage. (Alternatively you can make your server treat DeepCrawl bot like it would Googlebot). In this way, pre-rendered HTML is passed to the bot and all the links are crawlable.
Everything is now working fine from a traffic perspective, Organic visits are slowly rising, the website is fully indexed and we are such strong believers in Angular that we are going to start using it more and more in our ongoing projects.
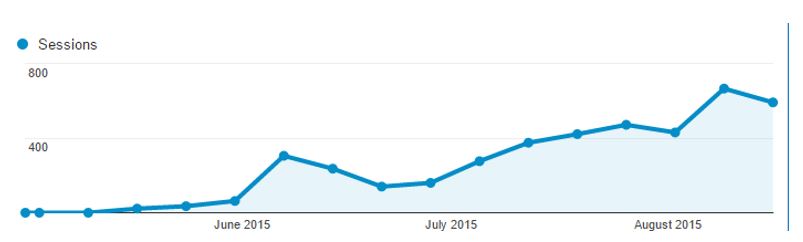
If you are as big a fan of DeepCrawl as I am, you can crawl this type of setup, as you can set DeepCrawl to act as GoogleBot. Here you can see a snap before pre-rendering was enabled.
Before we fixed the internal linking:
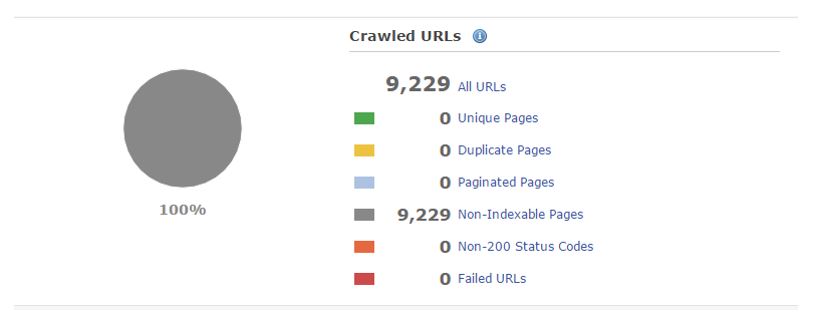
Before pre-rendering was enabled:
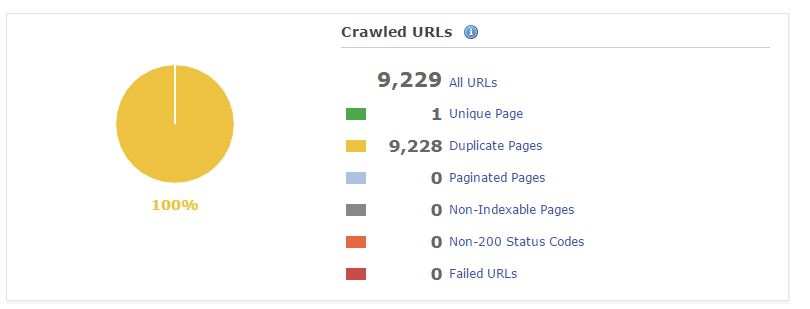
Now, once everything has been fixed and pre-rendered (almost anything):
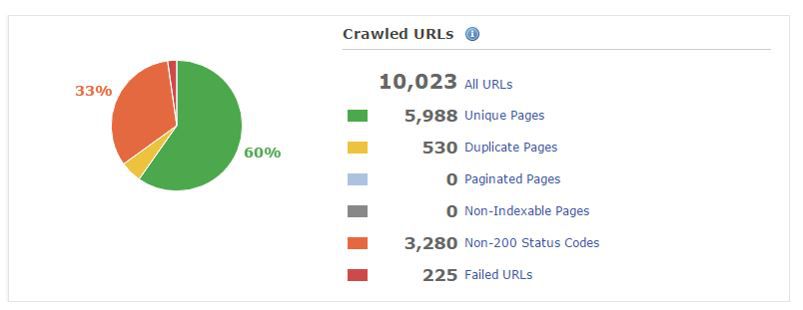
If you want to try this at home, set your user agent to Googlebot, when setting up a new crawl.
Want More Like This?
We hope that you’ve found this post useful in learning more Angular JS.
You can read more about this topic in our guide on How to Crawl AJAX Escaped Fragment Websites.
Additionally, if you’re interested in keeping up with Google’s latest updates and best practice recommendations then why not loop yourself into our emails?



