

So you know about canonical tags. And you know you should be using them. But, with so much information out there, so much riding on your search traffic and so many risks associated with using canonicals incorrectly, how can you be sure you’re following every rule?
Easy: by using our quick checklist of what to do, and what not to do…

Do
Do include a canonical tag on every page, without exception
All pages (including the canonical page) should contain a canonical tag to prevent any possible duplication.
Even if there are no other versions of a page, then that page should still include a canonical tag that links to itself.
Do canonicalize mobile pages to desktop
Use a canonical tag and a rel=”alternate” tag to signal that a mobile version and a desktop version of the same page should be treated as one entity in search results. Google explains more about this in the Google Developers Mobile Guide.
Do canonicalize paginated pages to consolidate weight
There are two options here. Which option you choose depends on how you want your content to be indexed.
- Canonicalize all pages in a paginated series to a view-all version that includes all of your content (only the view-all version will be indexed). This is the method that Google recommends.
- Canonicalize pages two and above to page one in the series, using a combination of canonical tags and rel next/prev (only page one in the series will be indexed). Google does not explicitly recommend this option (the option above is their recommended option), although John Mueller has discussed it in a recent Webmaster Hangout and said it’s fine to use if it’s the relevant method for how you want your content to be indexed.
We’ve detailed the pros and cons for each pagination option, plus one other incorrect option, in our post on pagination for SEO.
Do canonicalize tracking parameters
Use the Search Console URL Parameter tool to specify how Google should handle parameters and exclude those that don’t return unique content. Strip all the same parameters from your canonical URLs.
Do canonicalize from http to https (if you can’t redirect)
Hosting on both HTTP and HTTPS and canonicalizing to HTTPS means you will maintain your HTTP URLs, but Google will index and direct traffic to your HTTPS pages. You’ll essentially be running one domain on HTTP and another on HTTPS, but Google will only index the HTTPS version.
However, this option means:
- Your canonical tags have to be exactly correct to avoid duplicate content issues.
- You’ll still need to migrate all your URLs in Google’s index to HTTPS versions.
- Users coming from any source other than search engines won’t get the benefits of a HTTPS site.
For more detail on the best HTTPS option for your site, read our Zen Guide to HTTPS Configuration and this Google support post.
Do canonicalize alias domains (if you can’t redirect)
While using a 301 redirect to direct Google and users from your alias domain to your primary one is the best option, if you can’t do this for any reason (for example, if you don’t want to redirect users as well) then canonicalizing is imperative.
Do canonicalize print versions of the same page
Having separate web and print versions of the same content can cause duplicate content issues, but a 301 redirect isn’t appropriate as you still want users to be able to stay on the print version. So a canonical tag to show Google which version of the content should be indexed is perfect for this situation.
Do be consistent
Be consistent in whether you use a slash or no slash at the end of the URL, and don’t mix your cases: use upper case characters consistently, or don’t use them at all. Similarly, use character codes (ampersands etc) consistently, or don’t use them at all.
Do use absolute URLs
Using relative URLs in canonical tags can mean that Google will ignore them. As Google explain in their 5 common mistakes with rel=canonical post, using a relative URL in a canonical tag – for example example.com/cupcake.html – implies that the page you want to be indexed in search results is https://example.com/example.com/cupcake.html, which doesn’t make sense.
Do pick the correct HTTP/HTTPS and www/non-www variant
Remember that Google sees the HTTP/HTTPS and www/non-www version of a URL as a separate page.
Do put canonical tags on the page or in the header
They can be in both if they are the same, but if there is more than one and they are different, both will be ignored. See our guide to canonical tags for more information on how to implement them.
Do use canonical URLs in hreflang tags
Canonicalizing your international content to one primary version might mean that all users in all regions and using all languages will be shown the same version in search results, no matter what their browser settings are. Canonicalizing a page with hreflang may mean the page cannot be indexed and will not be returned in search results.
This subject came up in a 2014 Google Webmaster Hangout: watch it here for more information.
Don’t
Don’t canonicalize paginated pages if the details pages are important and need links
John Mueller discussed this in a recent Google Webmaster Hangout:
“[For example,] if you have an ecommerce site where you have one page that lists all of your items and from there it links to all your individual product pages, then if we don’t have any other form of navigation to those product pages, and we’re only focusing on the first page of that paginated set, then we might miss links to those individual product pages.
“On the other hand, if you have a normal navigation on the website and you have this long paginated set and you’re only indexing the first page then we’ll still find those individual product pages anyway through the normal navigation. So it kind of depends on your website what you want to achieve.”
Don’t include canonicalized URLs in normal Sitemaps, unless for recrawling purposes
Only include canonical URLs in your main Sitemaps. If you want newly-canonicalized URLs to be recrawled so that Google picks up the change quicker, then it’s worth including them in the Sitemap in the short-term (perhaps in a separate Sitemap). However, it’s recommended that you remove them when the change has been indexed to avoid any misreporting of your index counts.
Don’t canonicalize expired pages – 404 them, or 301 instead
Canonicalizing expired pages isn’t the best option, no matter how you do it. For example:
- Canonicalizing old pages back to even older versions of the same page (even if they are duplicate) means you’re consolidating ranking signals to a page that isn’t of use anymore either, and probably isn’t linked anywhere in the site.
- Canonicalizing to a separate unrelated page (such as the category page or homepage) is incorrect use of a canonical tag. Google specify that: “A large portion of the duplicate page’s content should be present on the canonical version.”
Don’t canonicalize to a target that is noindexed, or returns a non-200 status
If the canonical URL returns anything other than a 200 status then Google will probably just ignore the canonical tag. This also reduces crawl efficiency because Google has to follow canonical tags for no reason, wasting crawl time.
Don’t canonicalize to a canonicalized page
There should only ever be one canonical version of the same content. If you canonicalize one page to another canonicalized page, your tags will probably be ignored completely.
Don’t canonicalize pages that are significantly different from each other
The purpose of a canonical tag is to avoid duplicate content issues by indicating when two pages have the same content on URLs that Google sees as separate pages. Google specify that: “A large portion of the duplicate page’s content should be present on the canonical version,” so the canonical page and the canonicalized pages should include the same content.
If the content on the canonical page is significantly different from the content on the canonicalized page, Google might ignore your canonical tags completely.
Keep track of your canonical tags with Lumar
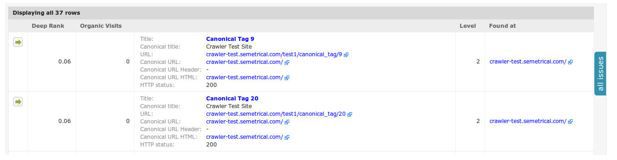
1. Find canonicalized pages
This report will find all pages with URLs that are different to the canonical URL specified in the canonical tag, in either the HTML or HTTP header.
Go to: Indexation > Canonicalized pages.
You will then see a list of all your canonicalized pages, plus their location and the canonical URL:
2. Identify pages without a canonical tag
Go to Validation > Pages without Canonical Tag
This view will show an at-a-glance view all of your pages that are missing a canonical tag.

3. Find unlinked canonical pages
Go to Validation > Unlinked Canonical Pages
Here you will find a list of all pages found in canonical tags that are not linked:

Lumar will always follow any canonical URL, so if any of these are broken then you can find them in the other error reports.



