

Generally, web servers keep a log of every single request received in a log file.
The web server log files contain a record of each file served to a web client, including pages served to Googlebot, and reveal unique insights about the way search engines crawl a website.
However, the log files are often difficult to access and process. Using Google Analytics to track Googlebot is an alternative technique for anyone seeking to analyze a search engine crawl, without the ongoing hassle of dealing with log files.
An Intro to Web Server Log Files
Each time a file is requested from a web server (when a user visits a page through a browser, or a search engine crawls a URL), a text entry is added to a log file.
The text entry details the time and date the request was made, the request IP address, the URL/content requested, and the user agent from the browser:
188.65.114.122 –[30/Sep/2013:08:07:05 -0400] “GET /resources/whitepapers/ retail-whitepaper/ HTTP/1.1” 200 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)“
Typically, a new log file is created every day with a new filename.
How Log Files Are Used
By combining requests from the same IP and user agent, it is possible to piece together an individual visitor’s activity. Software is available to process the information from the log files, and can produce reports on activity down to the individual page view. Before the invention of third-party analytics packages, this type of data was the primary source of information for web analytics.
In addition to user activity, log file analysis provides unique, page-level, insights into crawler activity.
Since crawlers generally don’t run JavaScript, pageviews are not recorded with normal analytics software. The log files provide URL-level search engine crawl data unavailable elsewhere – useful when optimizing your site architecture for the most efficient and effective crawling possible.
Log file analysis is also handy when identifying low-value, high-activity, crawlers, allowing you to block them and reduce server costs. Reverse DNS lookup on the IP addresses is required to validate that the bots are genuine, as the user agent field can be spoofed.
While often useful, a number of challenges surround log file analysis.
Challenges of Log File Analysis
- Size: Log Files are proportional to activity, and can reach many gigabytes, making them slow to download and difficult to store.
- Access: Requires FTP access to be set up to the server – reducing the overall security of the system.
- Formats: Variable formats can be difficult to work with, and every web server uses a different format.
- CDNs: Third party caching services generally don’t provide log files, and can’t easily merge into a single set.
- Validation: Because the user agent can be spoofed, search engine crawlers must be validated using “Reverse DNS Lookup.”
Google Analytics Server Side Hack
This Universal Analytics hack uses Measurement Protocol to store the log file information in a Google Analytics account, which can be accessed in real-time.
Once implemented, the hack completely eliminates the need to deal with log files again. However, it does require you to develop and run a simple custom script on your web server and monitor each request.
Most people lack the necessary skills to develop and install the web server script – you can reach out to the server administrator for implementation help.
If the user agent is Googlebot, the script can generate an HTTP request to the Google Analytics server, storing the same information that would normally go into the log file by encoding it in the request URL:
https://www.google-analytics.com/collect?uip=127.0.0.1&cs=page+title&tid=
UA-1234567810&dp=%2Ftest&dt=127.0.0.1+%28Mozilla%2F5.0+%28Macintosh
%3B+Intel+Mac+OS+X+10_9_5%29+AppleWebKit%2F537.36+%28KHTML%2C+
like+Gecko%29+Chrome%2F44.0.2403.157+Safari%2F537.36%29&dh=
example.com&cid=316c4790-2eaf-0133-6785-2de9d37163a1&
t=pageview&v=1
This will log the information in Google Analytics as a page view.
More detail on Measurement Protocol is available at the Google Developers’ site.
You should store the information in a separate Google Analytics account from the main user activity account.
From the page view, track the level of activity and drill down to page level detail:
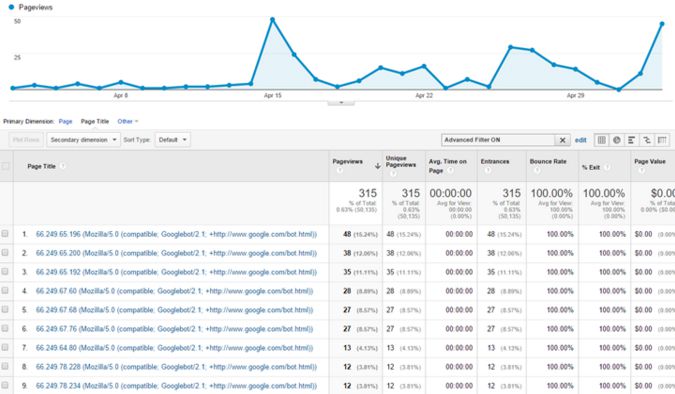
Google Analytics real-time limits the fields that can be displayed and filtered. For real-time data on crawling, include the user agent information in the title field.
Including the IP address of the request is also useful, as this can easily be filtered to genuine Googlebot activity – starting with 66.249.
Include other information in custom dimensions, such as the time of the request, as well.
Using Google Analytics to track Googlebot, allows for a more efficient method when analyzing a search engine crawl; as it eliminates the need to sift through the log files.
To learn more about Log File Analysis, check out BuiltVisible’s Log File Analysis: The Ultimate Guide.
You can also crawl your site with DeepCrawl to discover how Googlebot sees your website, and plug in your Google Analytics account to easily compare data. Get crawling here.



