As an SEO consultant, I’m pretty packed with a lot of projects and an overwhelming amount of data. Therefore, I favour tools which help me combine large volumes of data and make these large datasets actionable. All of this applies to Lumar (formerly Deepcrawl), so I’m happy to talk a little bit about my current favourite features. Here we go.
The Deepcrawl dashboard: an overview of the crucial information
Since Deepcrawl entered the market, its dashboard has been an essential feature for me. Even today, it’s still a real game changer. Whenever a crawl report is opened, it’s possible to observe critical information immediately. This is incredibly beneficial as it encourages me to delve more deeply into the reports. Let’s look at the following examples to prove the case in point:
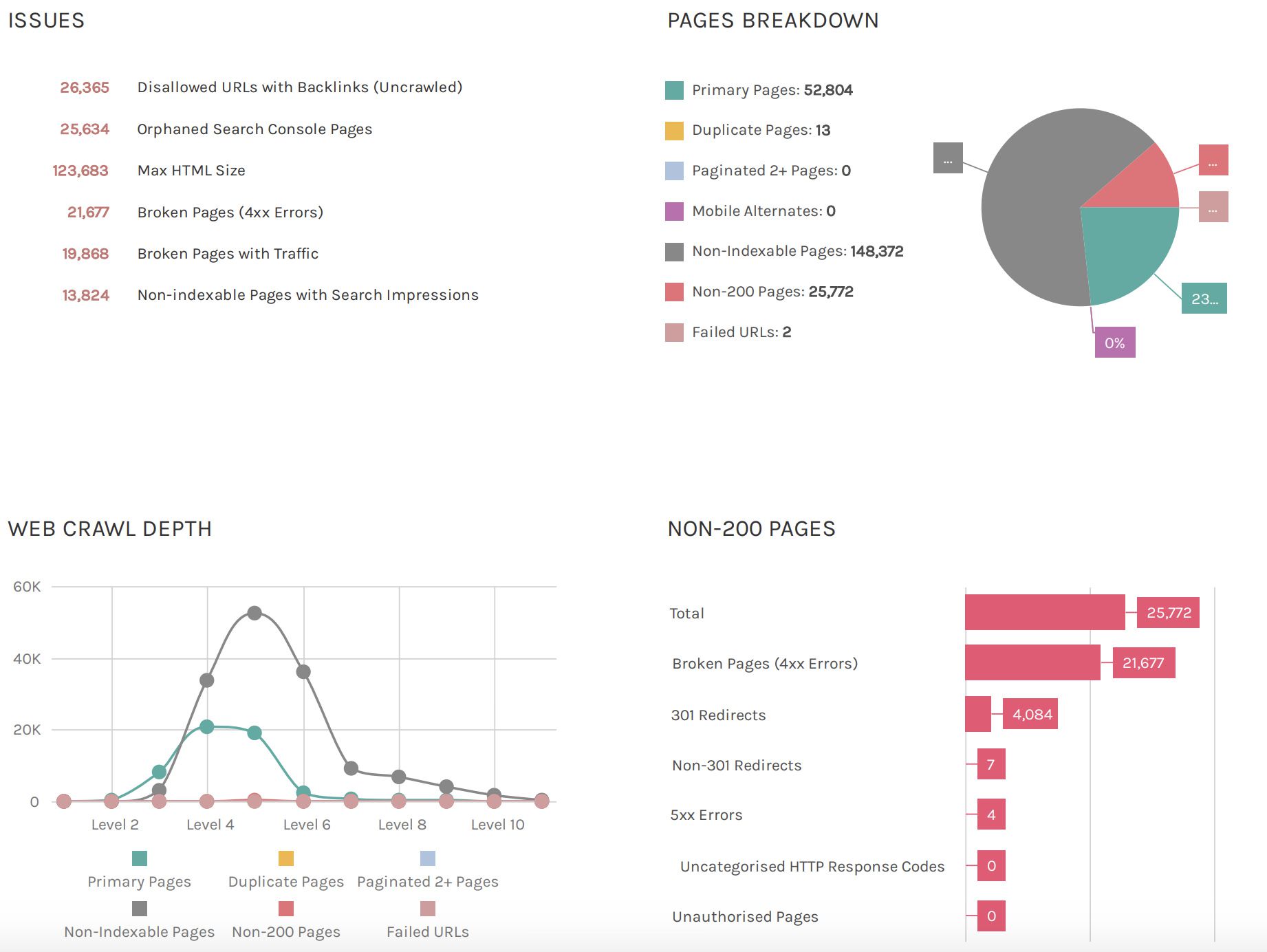
By providing an instant overview of the main issues at hand, it is possible to assess the condition of a domain very quickly. For me, this is particularly useful because it equips me with a lot of inspiration as to where to go next and fast. This is what a dashboard should do!
For both clients and for use in a meeting, the dashboard overview is pretty straight forward. In fact, I usually find that opening the crawl simultaneously results in less disagreements because, as they say, “the facts don’t lie.”
Mobile reports – prepare your website for mobile-first indexing
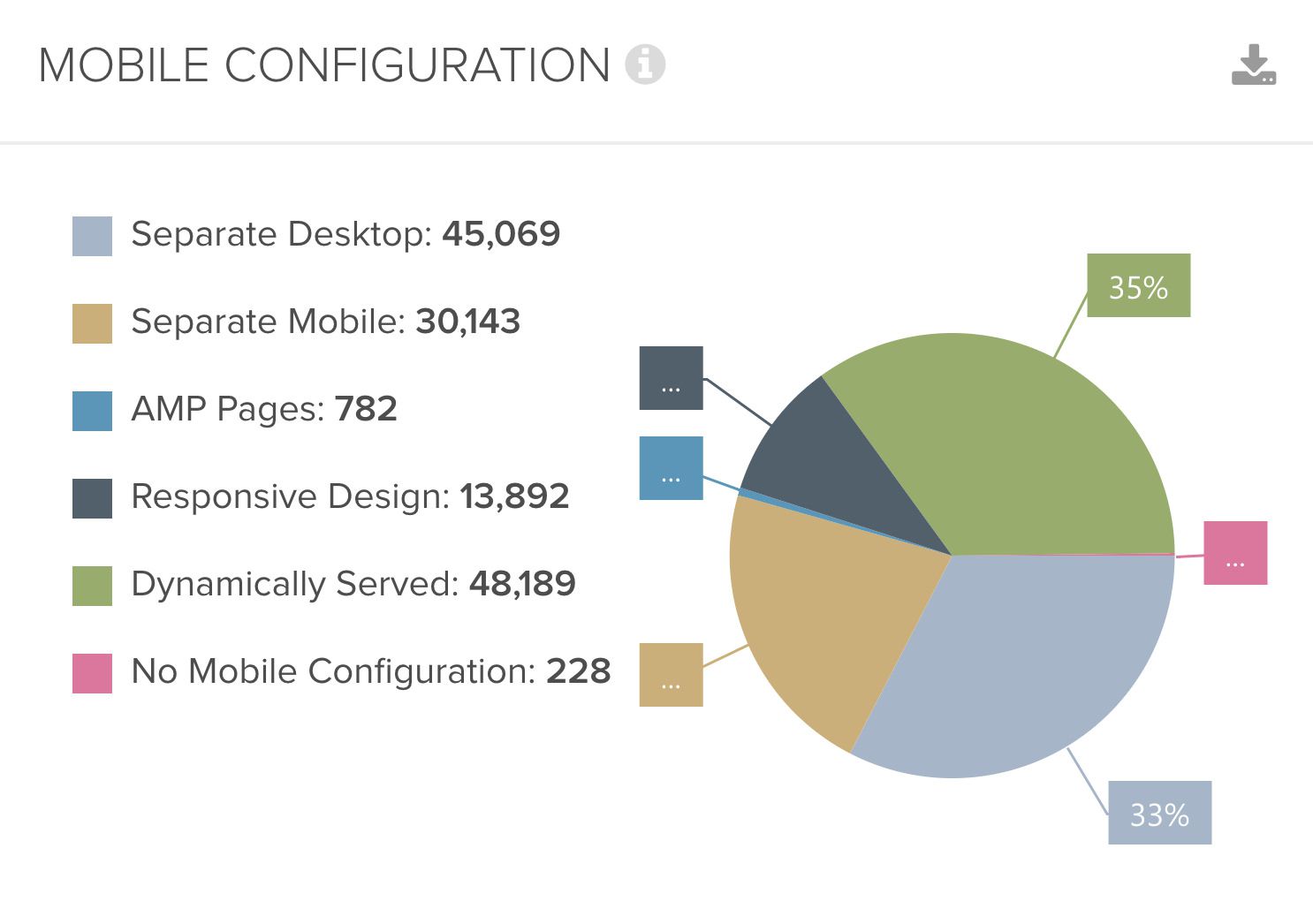
One function I really like is the desktop – mobile comparison. As we all know, Google is continually transforming its indexing procedure from desktop to mobile and this provides a challenge for both Google and website owners alike. In SEO, we subsequently often emphasise the critical importance of content parity. It’s essential that the metadata, content, structured data and internal linking etc. is the same, regardless of the user agent bot that Google is using. To ensure this is the case, Deepcrawl has a function that detects and reveals any differences. It starts by categorising the utilised mobile setup, e.g. responsive or dynamic serving:
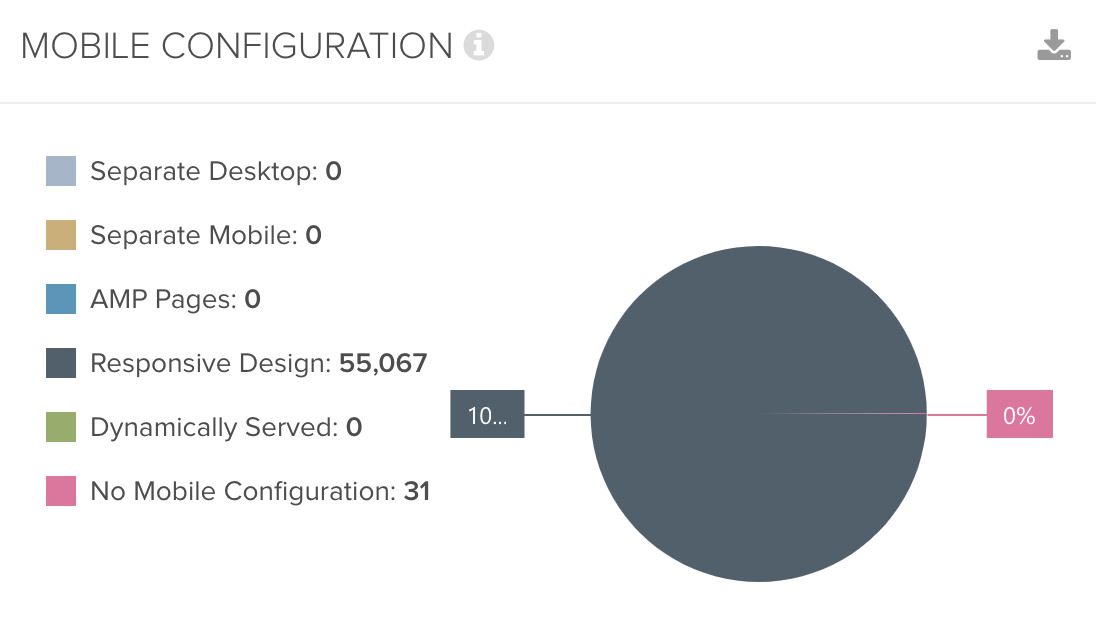
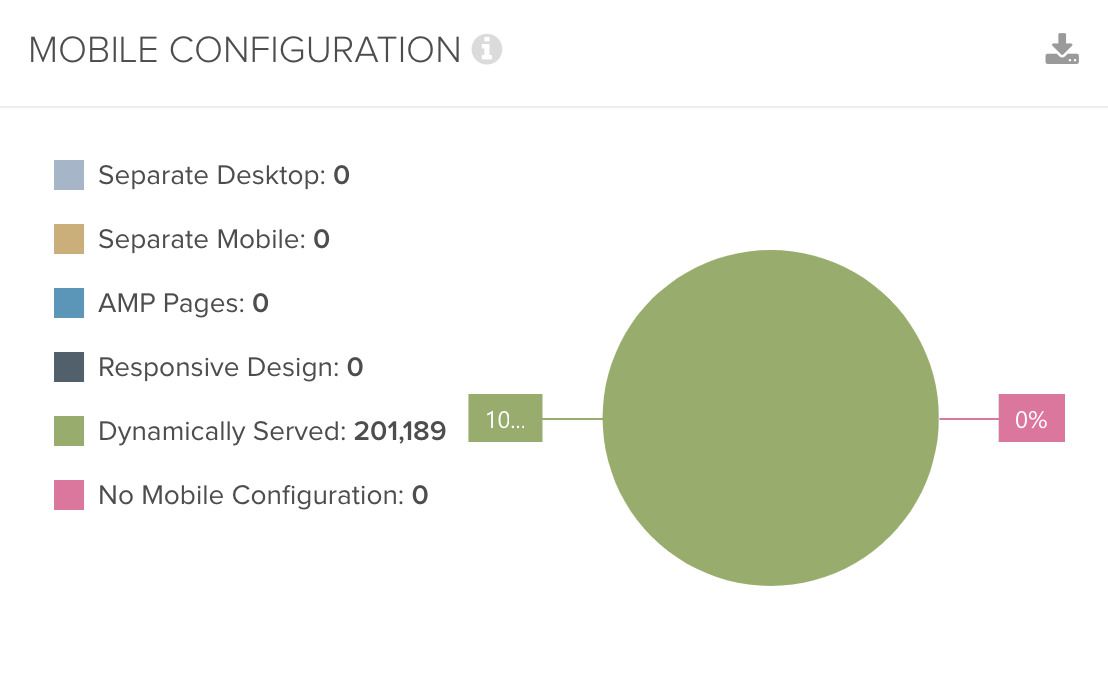
But even if the setup is a bit more complex, Deepcrawl will still be able to handle it superbly.
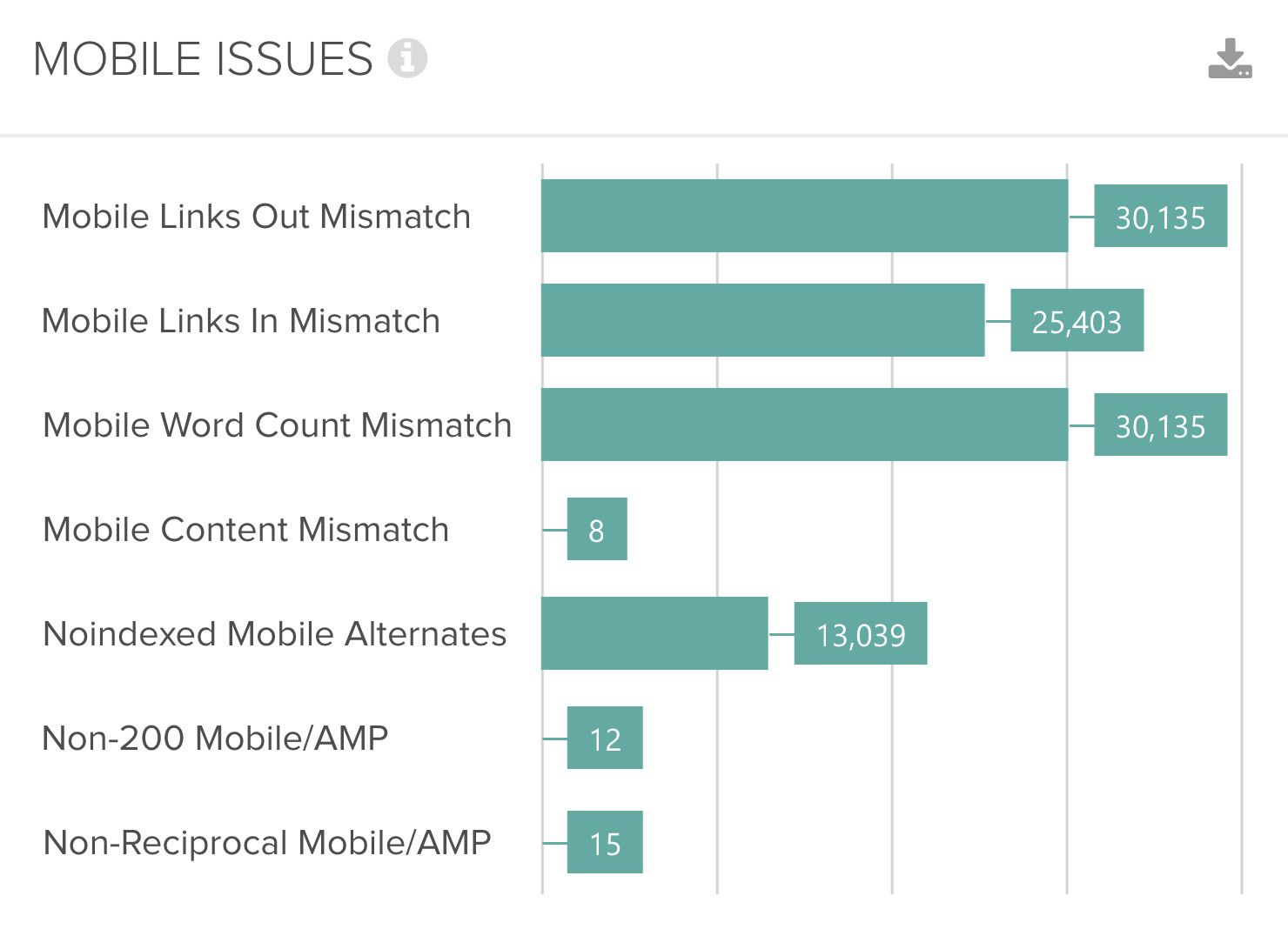
However, as this alone is of course not enough, Deepcrawl also displays the crucial differences between the different versions, as previously discussed. This is extremely helpful in implementing a road map of what needs to be done next, as depicted in the following chart.
Crawl source report – observe the differences
One aspect which is key in the field of SEO, is making available data visible. Therefore, I welcome every additional form of data integration. As Deepcrawl allows you to combine data from the web crawl with Google Search Console, Analytics, Backlinks (like Majestic data), additional lists, sitemaps and log files, this is an essential feature and I highly recommend that everyone utilises these functionalities.
After setting up a crawl which has a lot of different data sources, Deepcrawl can reveal crawl source gaps through its analysis. This is awesome as you can observe where differences present themselves. Take a look at the following chart:
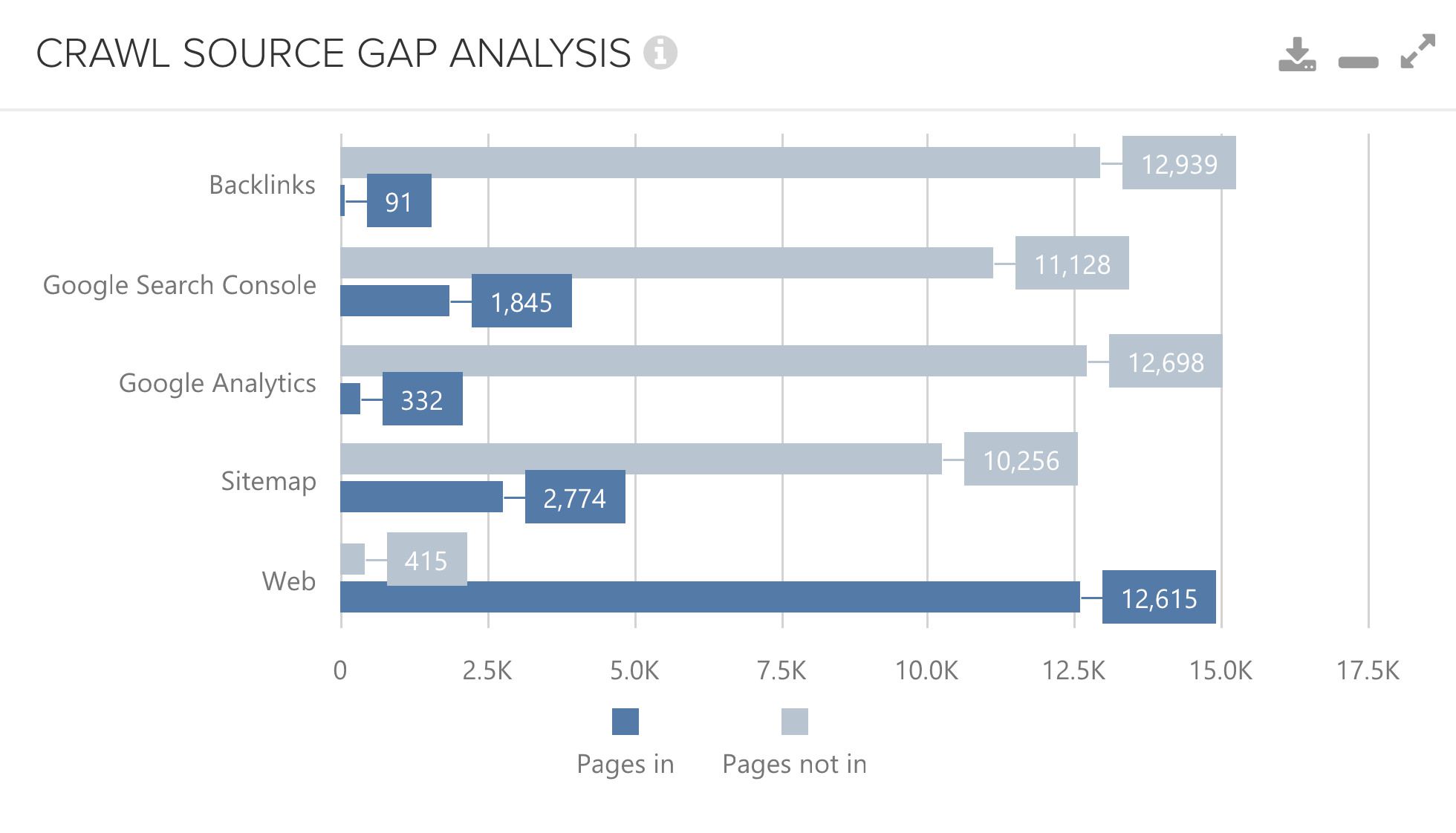
Thanks to this information, you can dive even further and analyse why these differences exist and what you may now need to do to improve your site structure.
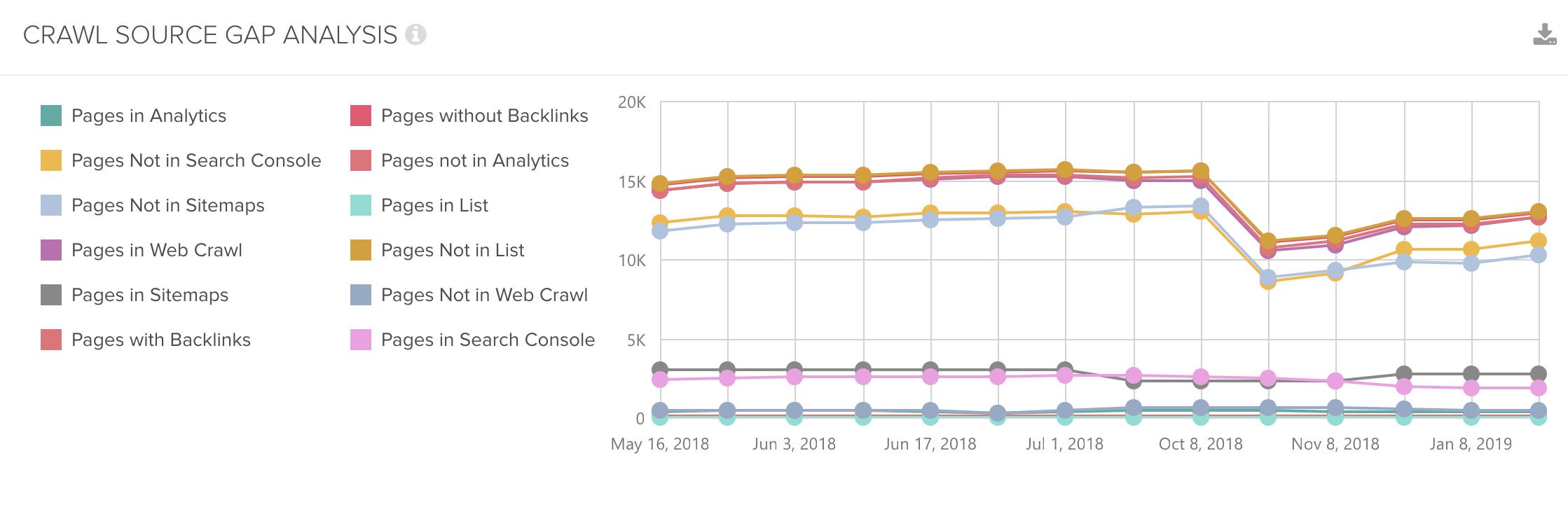
A further excellent feature is that you can observe this overview over time. Consequently, you can monitor changes, discover unexpected alterations and act if needed. Here is one example:
Orphan pages – recover unlinked URLs
Corresponding to the previous paragraph, there’s another useful overview I always keep an eye on: orphan pages.
As this overview demonstrates, if your internal linking is in place, it’s worth taking a good look at it. But please don’t confuse yourself. Deepcrawl’s orphan pages refer to pages that are not linked from any other page, which have at least one connection to the home page, but of course, this can be linked from another orphan page. The source gap overview combines the data set and compares which URLs are, or are not, included in a certain data set.
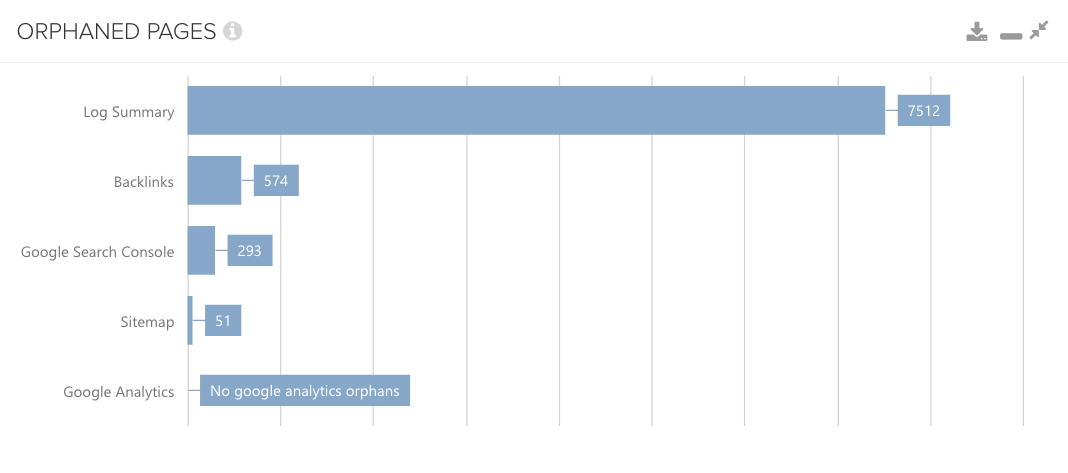
Therefore, if you notice orphan pages within your crawl, analyse which URLs are included. If you find important pages amongst them, improve your internal linking and ensure that they are firmly linked back into the informational architecture.
Search clicks by device – where do the clicks come from?
If you merge your web crawl and Google Search Console data, this overview is your friend. It’s small, but always worth looking at it. It combines information concerning indexability and the clicks from each device: desktop, mobile and tablet.
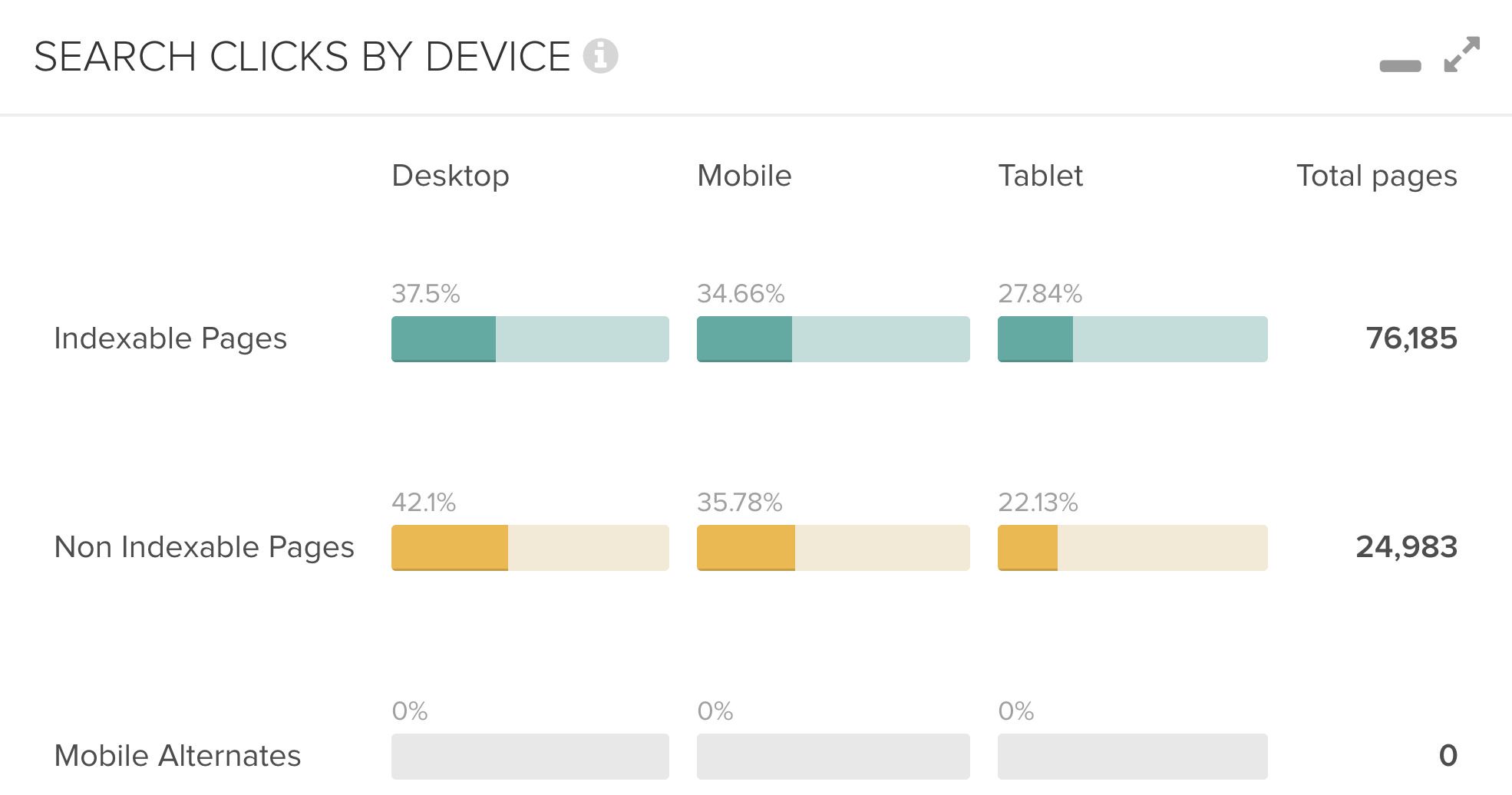
Subsequently, you have an instant overview of where the clicks come from, whether they are going to the right index status or whether there is an unnatural proportion of clicked but non-indexable pages (maybe due to an erroneous release).
Zapier integration – make your workflows smarter
As we are having to work with increasing amounts of data in SEO, smart data processing is essential. Therefore, you should always check which of your time-consuming, routine tasks can be automated. The aim is not to work less, but to work more efficiently as a consultant and to invest the time saved more effectively. This is where Zapier comes into play.
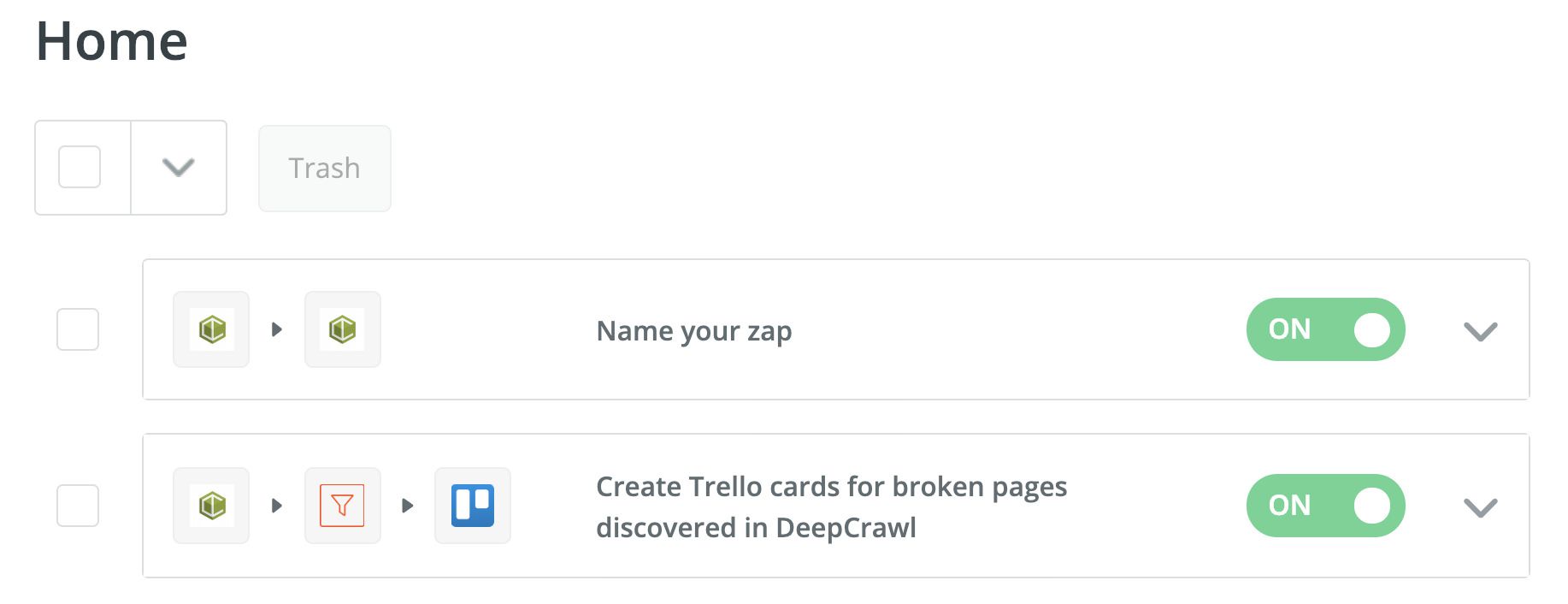
Zapier’s support of Deepcrawl is advantageous because, for example, certain crawl results can be automatically transferred into a JIRA or Trello board, which can then be processed by the responsible IT department or another SEO manager.
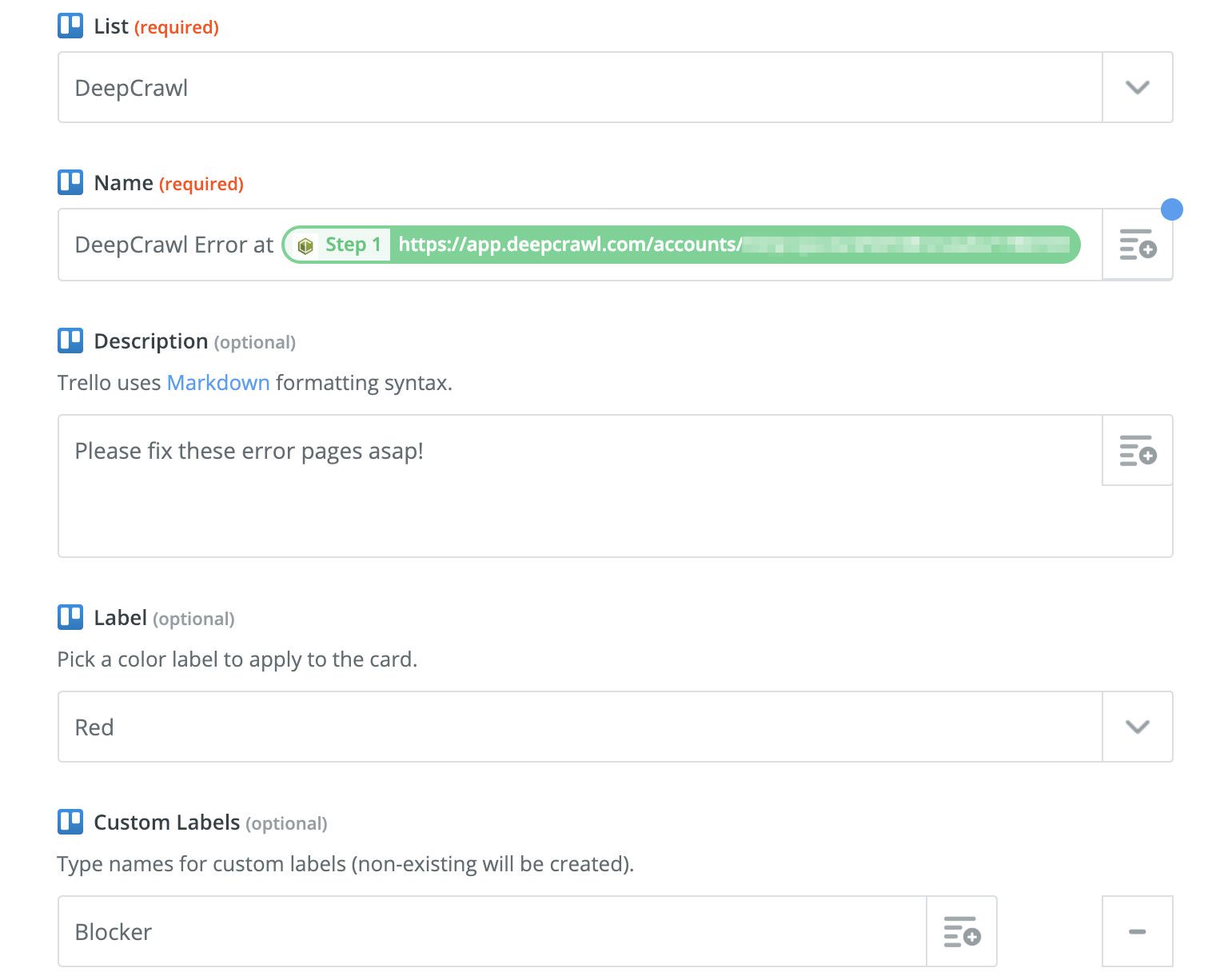
While implementation of this extensive filter setup will take some time, it’s well worth the effort.
Customisation possibilities are extensive and thus you can adapt each setup to match each individual customer’s needs.
Sharing reports – a small, but essential feature
This should really be classed as an “evergreen” function, as Deepcrawl has offered it since the beginning. This feature allows users to share their results with others by providing links for their data-view pages. This is tremendously useful, especially for consultants and agencies, as you don’t need to export large files and send them via mail, instead you just need to send a link, optimising your workflow to perfection.
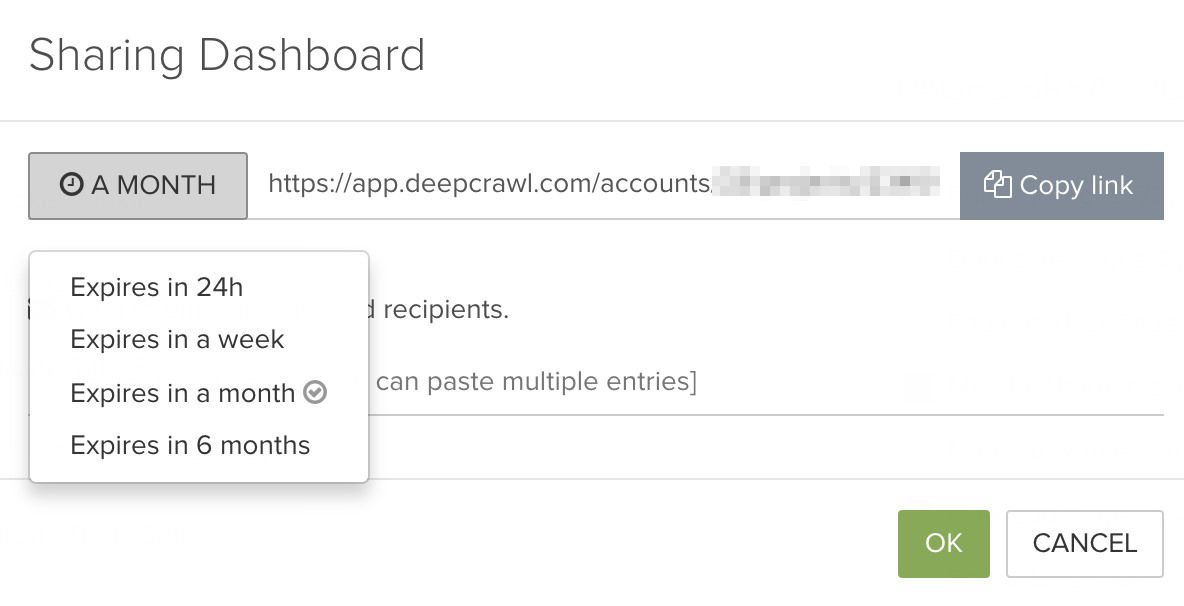
It is especially convenient to be able to add several recipients as well as to limit the lifetime of the link. As reading access can be restricted to between 24 hours and 6 months, its useful for both short term audits, as well as longer projects.
User roles – different needs, different rights
If you work in a team or with customers, it can make sense to utilise different user roles with regards to tools. Deepcrawl offers this function, creating a distinction between three user roles: admin, editor and viewer.
It is important to note that all the user roles are able to see the reports, so it does not limit viewing rights, but rather restricts the usage rights instead.
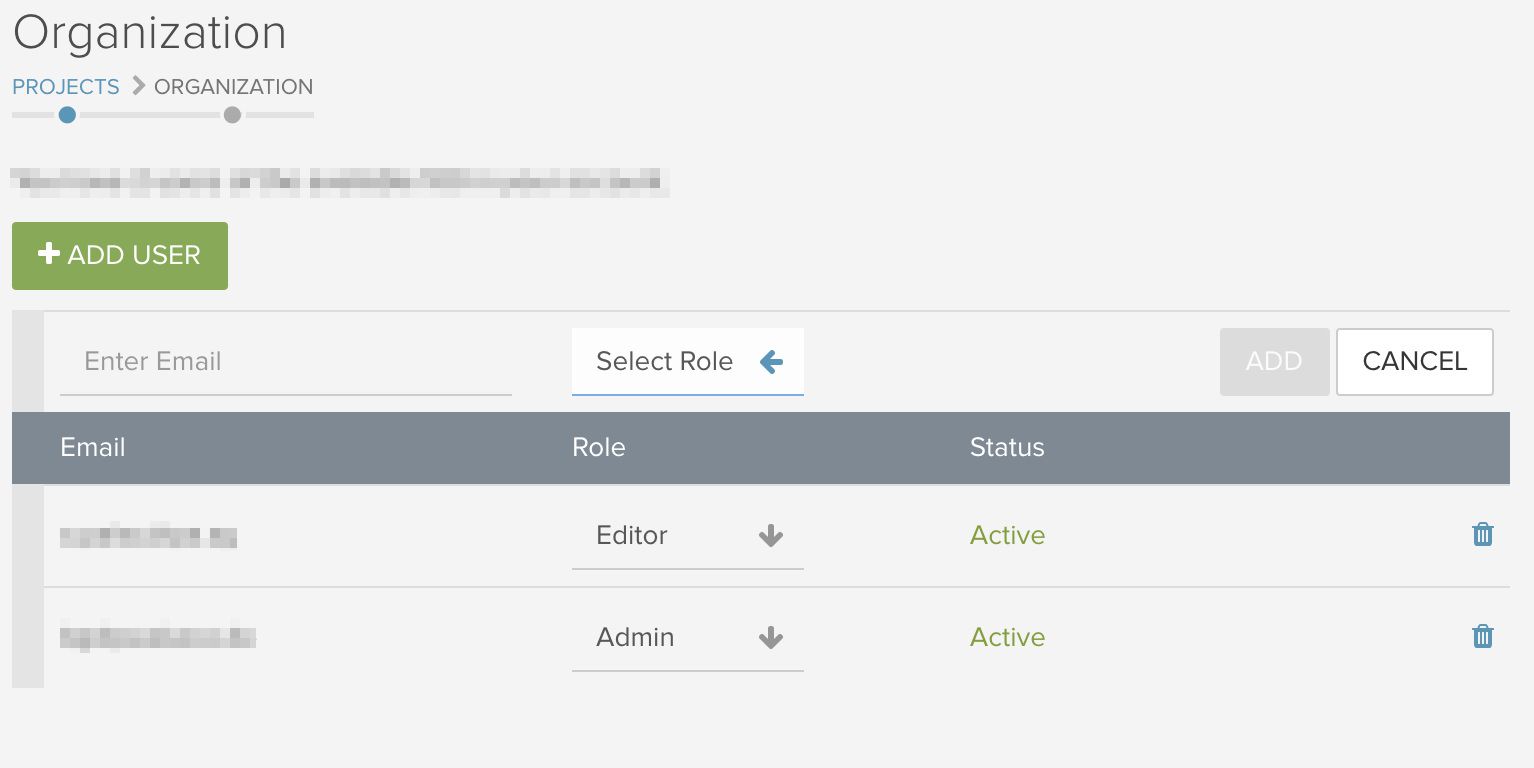
Both the editor and the admin can create crawls and share reports with a sharing link, but only the admin can create any account settings. The viewer on the other hand, has read-only rights. They cannot create crawls or generate a sharing link, but they can download data in the form of CSV files.
Therefore, the use of user roles makes sense when, for example, new employees need to be introduced to the tool but are not given immediate access to additional functions, or when departments within a company need access (IT) but aren’t given the ability to create their own crawls.
Site Explorer
Although this isn’t rocket science, I’m always amazed by how helpful it can be to switch perspectives. By diving deep into the crawl via the site explorer view, you are able to get a much better understanding of the current website structure regarding URL management. Additionally, as the examples show, you can immediately observe whether different protocols are still in use and which folder is the biggest etc.
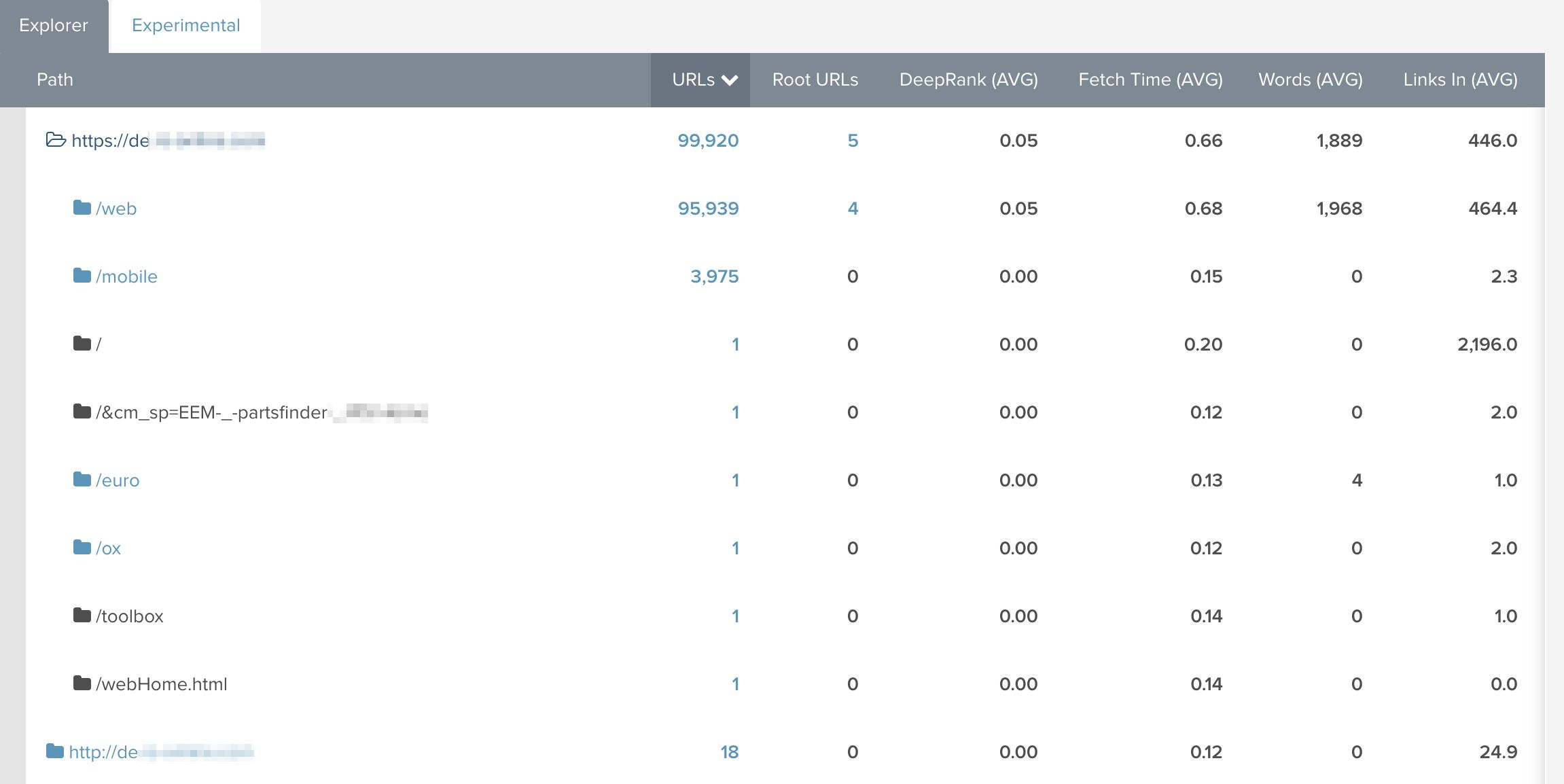
Especially when auditing a website for the first time, it’s worth assessing this overview to understand where most of the assets are located.
Schedule crawls – there will be hectic times
I always point this out, even if it is a “no-brainer.”
Automate functions such as crawls as you will thank yourself in the future for having done so. Our agency’s working days are incredibly dynamic and challenging. This is especially practical for long-term customers and projects.
Whether you set daily, weekly, monthly or interval crawls, just make sure you always have access to a continual stream of fresh data. Clients can spontaneously appear, releases can go live without being communicated beforehand and Google updates are always to be expected – so, just do it!
Find Out How Deepcrawl Can Help You
If you’re interested in exploring any of the features mentioned by Andor, why not try them out for yourself? You can get started with Deepcrawl by signing up for one of our flexible packages that give you access to our technical SEO reports. Alternatively, you can drop us a message if you have questions about our pricing and packages. Happy crawling!