

In the Google Webmaster Hangout on 6th October, John Mueller focussed on duplicate content, including a short presentation in which he covered what is (and is not) considered duplicate content, penalties and affiliate/syndicate content, among other useful reminders.
He then opened the discussion up for questions, in which he clarified some of the concerns about original published work being copied by bigger, more authoritative sites.
Here are our highlights, with notes and times. We’ve included the question where we think it could be useful for context.
What does Google deem to be duplicate content?
01:45: John started his presentation by clarifying which duplication Google treats as duplicate content:
Exact same page, or same content (or piece of content)
www / non-www / http / https / index.html / ?utm=…
Separate mobile-friendly URLs, printer-friendly URLs, CDN hosts
Tag pages (same blog post on multiple tags), press releases, syndicated content, same descriptions etc
Not duplicate content:
03:25: Google does not treat any of the below as duplication:
Different versions of the same content, translated into different languages.
Different pages with same title and description.
Content in apps.
Localized content.
Side note: while the above are not treated as duplicate content, it’s still a good idea to use hreflang (for international content) to help Google identify which version to show to which users and canonical tags to aggregate authority signals to a primary version if relevant.
Google attempts to filter duplicates at three different points
04:38: Next John went through some technical explanation about where duplicate content can be picked up and the implications for that.
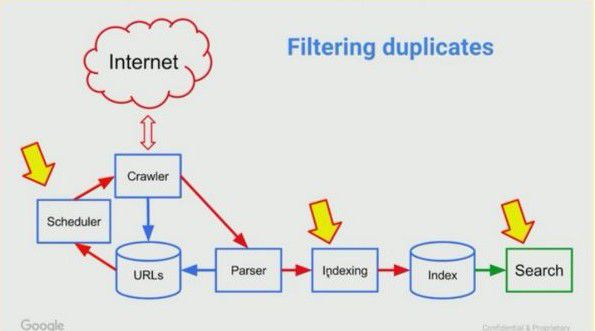
Crawling
The problem: duplicate content found during crawling wastes server resources, “crawl budget” and time. New/changed content takes longer to be picked up.
Solutions:
Use the URL parameter tool to help filter duplicates caused by parameters.
Google recommends not using robots.txt to disallow duplicate content.
Google has smart systems that can pick up duplicate content caused by URL parameters and paths that have caused duplicates.
There is no duplicate content penalty when duplicates are picked up like this.
Indexing
The problem: duplicates are a waste of storage and resources.
Solution:
If a whole page is a duplicate, Google just keeps one copy. At this point Google might have trouble deciding whether to filter duplicates that have been edited for different regions. Google tries to take into account other signals to decide whether to index one or both of these versions (even for different regions that use the same language: UK / US / AUS for example).
Again, there is no penalty for the above.
Search results
The problem: duplicate are confusing to users, so Google will just show one of them.
This could apply to pages that are unique overall but that have specific elements that are duplicated. For example, a range of product listings could be considered unique by themselves but they could share descriptions.
Solution:
Duplicates that have been filtered in search results will usually show as “…we have omitted some entries very similar…”
But there is no penalty here either.
Problems occurring from duplicate content (that don’t cause penalties)
07:32: Duplication means Google has to crawl lots of pages unnecessarily: this can mean a lot of load for the website and also means Google might not pick up new content as quickly as it should do.
Lots of duplicates also make it harder to track metrics, especially if you’re not sure which version is showing in the search results.
Finally, Google might pick the wrong URL to show in search results.
Problems that CAN cause duplicate content penalties
All of the below will cause a manual or algorithmic penalty. Sites that use these methods are penalized for being spammy, NOT for using duplicate content:
Scraper sites
Content spinning based on other sites (aggregation, automatic translations, rewriting etc)
Doorway pages / sites
How to recognize duplicate content
Check whether Google is showing the “other” URL in search.
Use the Search Console HTML suggestions feature to check whether titles and descriptions are duplicated (which could indicate duplicated pages).
Check how many pages Google is crawling: if this number is much larger than the number of pages on your site, then Google is probably finding a lot of duplicates.
Affiliate / shared or syndicated content
12:19: In regards to affiliate, shared or syndicated content, John recommended making pages stand on their own: provide a unique value-add that the other sites sharing the same content do not add.
If this is not possible, consider noindexing unresolvable duplicate content. However, some kinds of duplication can’t be avoided: that’s normal so Google will just try to filter on its own.
Bad practices for duplicate content
Don’t use robots.txt to block duplicate content (Google can’t tell it’s the same, so will just treat it separately). Only use robots.txt to block duplicates if you have a severe server issue that means Google’s crawls will cause problems for your users.
Don’t artificially rewrite content (that’s spam) or use the same content and just tweak it to try and make it look unique.
Don’t use URL removal tools (they just temporarily hide the URLs in search).
Good practices for duplicate content
Be consistent: “Consistency is the mother of all good SEO.” Use a single URL per content, everywhere (including your Sitemap, canonical, hreflang and internal links).
Avoid unnecessary URL variations.
Use 301 redirects where possible. Use canonical, use hreflang and point them all at the same URL variation.
Use Search Console settings (preferred domain, URL parameter handling tool)
Use geotargeting and hreflang, where relevant to indicate the same content that is used for different purposes.
Highlights from the questions:
Google considers more than the original publisher when filtering duplicate content on different sites
22:00: Two versions of the same content on different sites will both be indexed because they have unique value on their own. Google will then try to consider which version has more value to the users when deciding which version to prioritize, not matter who published the content first:
“We would obviously index both of these versions [because] they have unique value on their own, and we try to figure out, depending on what people are searching for, which one of these versions is the best one to show in the search results. It might even happen that we show both of these versions in the search results at the same time.”
If, for example, a smaller site publishes a piece of content in Italian and the same content is picked up and published by a much bigger US site with English commentary, then the bigger site might be shown to users in the US who are searching for that content in English, because that version of the content offers more value to that audience.
Similarly, if lots of eCommerce sites use the same description for the same product, a site that is based in a specific country might be shown to all users in that country, because it is more relevant to that audience.
John added more to this answer in response to a later question at the 59:35 mark: see below for the notes.
Percentage of duplicate content on the same site does not matter (mostly)
24:11: Except in cases where the whole of a site is duplicated from other sites (which would probably indicate a spam scraper site) Google does not pay much attention to the percentage of duplicated content across the same site. For example, 20% duplicate content is no better than 40% duplicate content. This is because duplicate content is a technical issue, and it doesn’t necessarily mean that the quality of the content is worse.
Use the same titles and meta descriptions on all pages in a paginated set
32:00: Using the same titles and descriptions will help Google confirm that these pages belong in a paginated set, even if you use rel next/prev as well. Writing different titles and descriptions for each page might mean that your markup is ignored, because the pages won’t look like they belong in a set.
Very similar content can still be treated as unique (depending on the user’s search query)
36:26: “You have a site that has many pages, 1 page for each baseball player. Each page displays stats and has mostly the same text. The content would only differ on the stats displayed. Eg: Batting avg. (same) = 0.66 (difers). How is this treated?”
In response to this question, John said that the effect would differ based on the user’s search query, because even though the text is the same on each page, the stats are different so the content can be treated as unique. If the user is searching for the batting average of a specific baseball player, then they will find the specific page for that player more useful, so Google will try and show that in the search result.
For a user searching for batting averages in general, it might be more difficult to filter out which duplicate should be shown, but the homepage or another general page might be better for a general query like that anyway.
More detail on original publishers vs re-publishing on bigger sites
59:35: The issue of whether bigger (more authoritative) sites will get ranked higher if they re-publish content from smaller sites came up again when Mihai Aperghis asked whether the original publisher will be identified as the original source of the content, or get any “credit”. John clarified:
“We use a number of different ways to figure out which one to show . It’s not just a case that we say ‘This is a bigger website, and they copied the other guy’s content therefore we’ll show it for everything.’ We do try to take a number of different things into account for that. It’s not quite trivial but it’s not something that we fold into something really basic.
“It’s hard to define what you mean with ‘value’ and ‘credit’ but we do try to recognize that they were the first ones or the original source of this content [and] we do try to treat that appropriately. A lot of times there will be a lot of indirect result there too, [for example] if the Huffington Post writes about something that you put on your personal blog then obviously lots of people are going to visit your blog as well.
“But it’s a tricky problem to figure out what is more relevant for the user at that point when they’re searching. Are they looking for something mainstream or are they looking for the original source? Are they looking for a PDF or are they looking for a web page that is describing the same content? It’s hard to find that balance.
“It’s usually not as trivial as saying ‘Well this content is on this unknown website and it’s also available on this really big website and it’s exactly the same content: which one do you choose. Usually there are a lot of other factors involved there too.”
John ended by saying that “sometimes” this can be picked up with linking, if the bigger website links back to the original source.
FIND AND AVOID DUPLICATE CONTENT ISSUES WITH DEEPCRAWL
IDENTIFY DOMAIN DUPLICATION
DeepCrawl provides a report that includes all domain duplication variations and will identify any full site duplication.
Our other tool, Robotto, can detect whether a preferred www or non-www option has been configured correctly.
FIND DUPLICATE PAGES ON SEPARATE URLS
The Indexation > Duplicate pages report highlights very similar pages across the site.
FIND SIMILAR CONTENT ON SEPARATE PAGES
The Content > Duplicate Body Content report looks at the body content only, to find pages which have different titles and HTML but very similar body text.
FIND DUPLICATE TITLES AND DESCRIPTIONS
Content > Duplicate Titles and Content > Duplicate Descriptions highlight the pages which have unique body content but where either the titles or descriptions are identical with another page.
DUPLICATE INTERNAL LINKS
Indexation > Unique Pages > [Page] > Links In shows you all internal links to a page so you can easily see the level of uniqueness across the links.
Run a backlinks crawl to see all the external backlinks to a page and identify a potentially large number of duplicate links which might be unnatural and could result in a penalty.



