Don’t let the version numbers confuse you. DeepCrawl 2.0 was a complete rebuild from the ground up, without a single line of code shared with the previous version.
This has meant there are lots of changes to the system, which you might want to understand to explain some of the differences in reporting.
If you’d like more detailed explanations about anything, please get in touch via support@deepcrawl.com.
Interface
- Projects in the main project view are not grouped alphabetically by domain. You can change the order to domain A-Z to get the equivalent view.

- Accounts packages now include an ‘active project’ limit, shown in the view called Active.

- The ‘Running’ view now shows crawls which are currently running.

- User defined ‘Issues’ has been changed to Tasks to avoid confusion with the list of reports that have a negative sign.

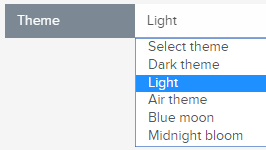
- Alternative interface themes can be selected in the Account admin screen.
- A System Status screen has been added so you can check if our systems are operating correctly.

- Crawl sources which have been added to a project are visible to help identify a specific project.

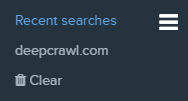
- Recent project searches are shown in the left hand navigation.
- The interface is now on HTTPS.
- Crawl limits can be updated during a crawl without pausing.
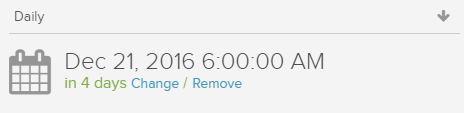
- Crawls can be scheduled before being run at least once.
- The URL encoding improved. Everything is shown as unencoded in the interface and downloads to improve usability.
- Graphs on the dashboard can be downloaded in various formats, and some of the graph types can be changed.
- A report search has been added so you can quickly find the report you want.

- A URL search features has been added to dashboard so you can quickly navigate directly to a specific URL.
- Advanced report filters have been added to reports, including multiple filters and more matching methods

- Downloads are all generated dynamically instead of being pre-generated.
- Read/Unread crawls are no longer highlighted in the projects view.
- Custom domains for sharing reports are no longer available.
Setup
- HTTP/HTTPS & WWW/Non-WWW domain variations are checked when adding a new site to help you pick the best one to start your crawl.
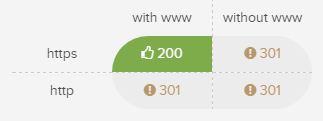
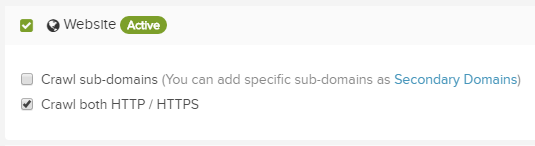
- Crawling both HTTP & HTTPS versions of a domain is no longer the default anymore. It has to be specifically selected to avoid wasting credits.
- Page Grouping restrictions have been changed to % of matching URLs instead of absolute limits.

- The default crawl speed reduced from 5 to 3 URLs per second for new projects.

- The maximum crawl speed has been increased to 50 pages per second.

- Projects can be changed to include other crawl sources at any point in time.
- The automatic crawl mode which finalised at the last full level before the crawl limits has been removed.
- Custom analytics data can be uploaded from any web analytics source via a manual CSV upload, in addition to Google Analytics API.

- Settings can be copied from one project to another.

- The backlink crawl has changed to accept a list of linked URLs which are added to the crawl queue, and backlink metrics which are visible in reports. The external URLs with backlinks are not crawled to check the links.
- The default Sitemap.xml URL is not automatically checked and added to a Sitemap crawl, unless linked in robots.txt.
- We have removed the option to ‘Include non-indexable pages in all reports’.
- The Included/Excluded URL restriction settings now use regex only, not the robots.txt matching syntax.
- Uploading List Crawl URLs now requires a file upload and can no longer be pasted manually.
- The file upload is limited to 100MB per file for each crawl source.
- Dynamic IP addresses are located in the US instead of Europe.
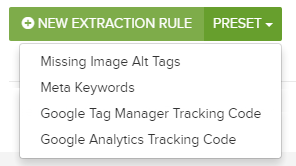
- Custom Extraction presets in the Advanced Settings > Custom Extraction are available for some common extraction requirements. Let us know if you have any more suggestions.
Crawling
- There is no processing between levels, speeding up the crawls.
- The max links per page restriction of 1000 has been removed.
- The URL download lists available during a crawl have been removed.
- Static IPs can crawl HTTPS.
- The maximum content-body size limit we analyse is 4 MB (e.g. HTML page including <head> and <body> sections), and the maximum header size limit is 8 KB. If a page exceeds this, it will be abandoned.
- If a URL times-out or has a proxy failure, the crawler will retry crawling once more before continuing.
- The crawler is sensitive to performance issues and will reduce the crawl rate if it encounters many 500 status codes.
- Redirect chains are combined when discovered at different points in the chain.
- A crawl settings comparison feature has been added so you can quickly see any changes to settings made between crawls.
Reports
- We have created a full list of every report available in DeepCrawl 2, including a description of how it is generated, and how it can be used.
https://www.deepcrawl.com/knowledge/guides/reports-metrics/ - Every morning (around 3am) the 3rd crawl and below in all projects are archived, after 3 months the first 2 crawls are also archived.
- Report metrics have been removed from Site Explorer which used to show the number of items in each report for every page path.
- All Links Out report has been removed from the page view, as we only store unique links across the site, not every link from every page.
- Removed Reports
- Valid Open Graph Tags
- Inconsistent Open Graph URLs
- Max Twitter Card Description Length
- Internal Broken Links
- Inconsistent Character Encoding
- Changed Reports
- We separated duplicate reports into two types:
- Clusters (sets of duplicates)
- Duplicate Clusters
- Duplicate Titles
- Duplicate Descriptions
- Pages (individual pages that have at least one element duplicated with at least one other page)
- Pages with Duplicate Titles
- Pages with Duplicate Descriptions
- Pages with Duplicate Body
- Duplicate Pages (pages with all 3 elements duplicated: title, description, body)
- Clusters (sets of duplicates)
- Duplicate Pages are not excluded from the other reports so a Duplicate Page will appear in the following reports as well:
- Pages with Duplicate Titles
- Pages with Duplicate Descriptions
- Pages with Duplicate Body
As well as - Duplicate Titles
- Duplicate Descriptions
- Missing Titles, Missing Descriptions, Empty Pages, Thin Pages, Max Content Size, Missing H1 Tags, Multiple H1 Tags, Valid Twitter Cards, No Descriptions & No Snippets, Short Descriptions, Short Titles & Max Title Length now don’t included non-200 and non-indexable pages.
- We separated duplicate reports into two types:
- New reports
- Duplicate Clusters (Was previously the ‘Compact’ version of the Duplicate Page report)
- 200 Pages
- 2xx Pages (excl. 200)
- Unauthorised Pages
- Javascript Files
- CSS Files
- Meta Refresh Redirect
- Meta Refresh to Itself
- Empty Pages
- Broken JS/CSS
- Disallowed JS/CSS
- Non-indexable pages driving traffic
- Unique Internal Links
- Mobile
- Desktop Mobile Configured
- Mobile/Desktop (Dynamic)
- Mobile/Desktop (Responsive)
- Discouraged Viewport Types
- HTTPS
- HTTP scripts on HTTPs pages
- Pages with HSTS
- HTTP Pages with HSTS
- HREFLANG sets/combinations
- Unsupported hreflang Links
- Missing Image Link alt tags
- Non-HTML Pages
- Renamed reports
- Valid Open Graph Tags >>> Page with Open Graph Tags
- Non-HTML >>> Linked Non-HTML Files
- Min Content Size >>> Thin Pages
- Inconsistent OG Graph & Canonical URLs >>> OG:URL Canonical Mismatch
- All URLs renamed to All Pages
Data & Metrics
- Instead of storing all links on a site, we are storing unique links, which have a distinct target URL, anchor text and link type.
- Changed metrics
- DeepRank is calculated more accurately.
- Custom extractions and H1s are now stored as an array, to better accommodate multiple matches per extraction.
- New metrics (the main pages table increased from 36 to 186 metrics)
- Response header
- Crawl Datetime
- H2 & H3 tags
API
- The base route of the API has changed from: https://tools.deepcrawl.co.uk/api/v1.9/ to: https://api.deepcrawl.com.
- The API for 2.0 is much more comprehensive, everything in the 2.0 UI is done via the same API available to all clients.
- The URL structure of the 2.0 API is the same as in 1.9 e.g. /accounts/{account_id}/projects/{project_id}/crawls
- Our authentication has changed and now requires a first request to generate a token which is used to authenticate all further requests.
- The crawl route now returns all crawls including if the latest crawl is running, whereas in 1.9 only finished crawls were returned.
- There are many new routes and new properties available in the API. A good example is the new latest_crawl_href property that easily allows you to consume the latest crawl in a project without doing making many different calls.
- Reports are dynamic and cannot be reached via a specific URL anymore. Instead, the list of reports needs to be filtered down via the ‘code’ property of reports which are listed here: https://www.deepcrawl.com/reports.