Formed in 2006, The Next Web is an established technology news site offering up opinionated perspectives on tech news. As well as news, The Next Web also run Europe’s leading tech festival the TNW Conference, which last year won the award for Best European Business Conference.
At DeepCrawl (now Lumar), we are proud to provide The Next Web with the tools they need to improve their organic performance.
Find out how The Next Web’s very own SEO Specialist, Julian Aijal, has used DeepCrawl to: increase crawl budget efficiency, overcome redirect loops and integrate our tool as a key part of their ongoing SEO monitoring efforts.
SEO as a Publisher
Being a publisher brings different types of SEO issues. For over 10 years we’ve been writing articles about tech on a daily basis, so luckily duplicate content is unusual.
We do write with SEO in mind, but we don’t try to steer editors based on different subsets of keywords just for the sake of high search volumes. Organic traffic is one thing, but unique quality content will always be the most important in terms of news coverage.
So what do we do with SEO?
We try our best to be at the forefront of every possible feature that can affect search visibility. AMP is one of these things – which we now monitor through DeepCrawl’s AMP reports – together with an extensive structured data implementation on different types of pages.
For a website of our size we require a cloud-based solution, so this made it fairly easy to give DeepCrawl a try.
Here are some of the awesome features that stood out for us.
Fixing Crawl Budget Issues
Google doesn’t crawl all of our pages with the same frequency; as we know they’re limited by a crawl budget. We make a distinction between news and evergreen articles (those which still get a stable amount of traffic over time), so we need to be sure the bots are able to crawl our website in the most efficient way.
After running a crawl with DeepCrawl, we found out that our crawl budget wasn’t being used efficiently. Our CMS created a duplicate URL whenever at least one link wasn’t filled in correctly.
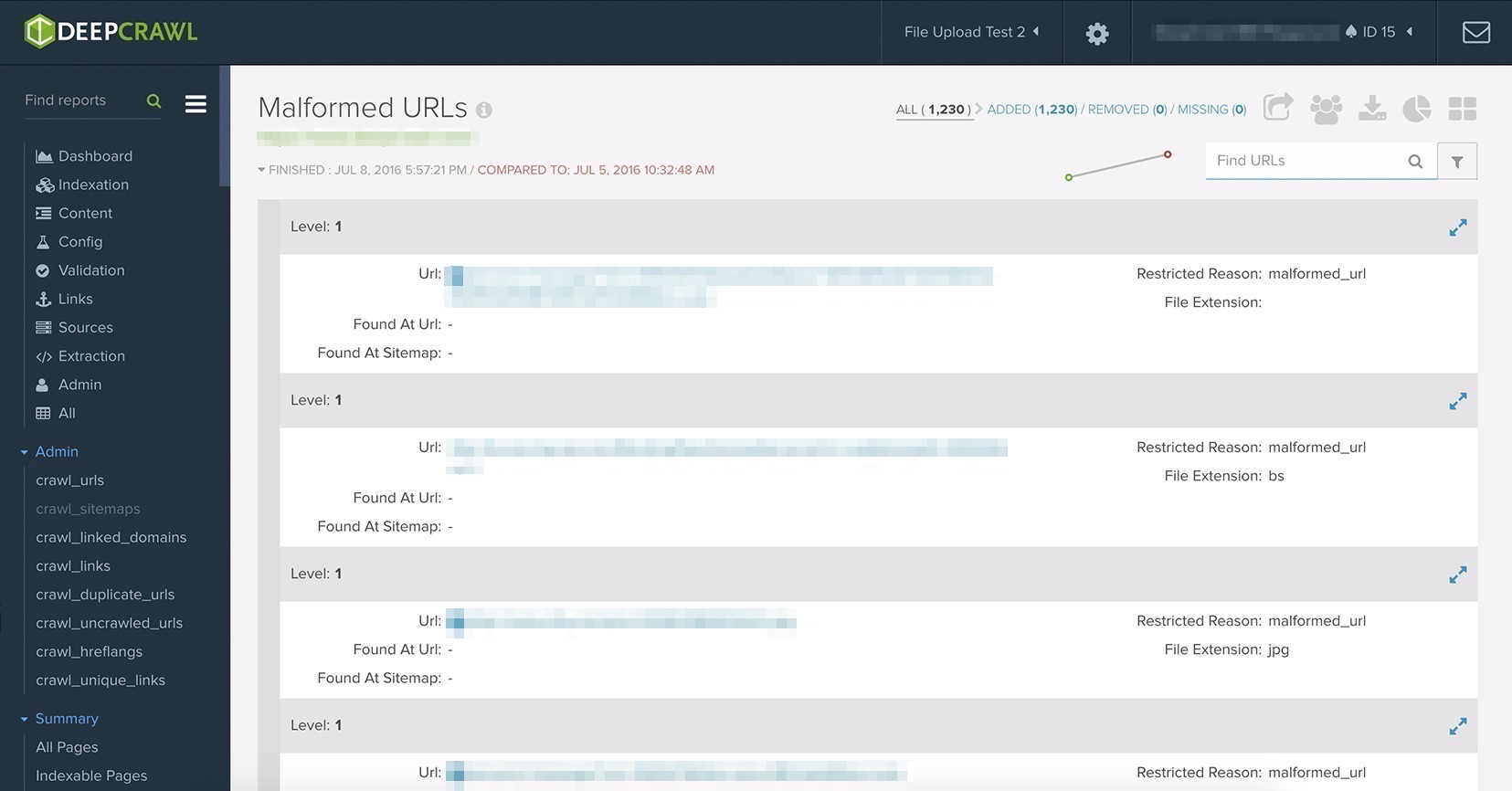
We fixed this issue from happening again, but that wasn’t the end of our problems. A huge amount of infinite URL loops existed in those previous 75k articles. I was able to find them, but they kept returning.
DeepCrawl took us to the core of the problem in the Malformed URLs Report showing us all of the URLs that were mistyped instead of reporting the URL loops itself, which was the side-effect of the problem. As a result of DeepCrawl’s ability to show all of these errors clearly in one single report, we were able to fix this issue in a single day.
Interlinks and Redirects
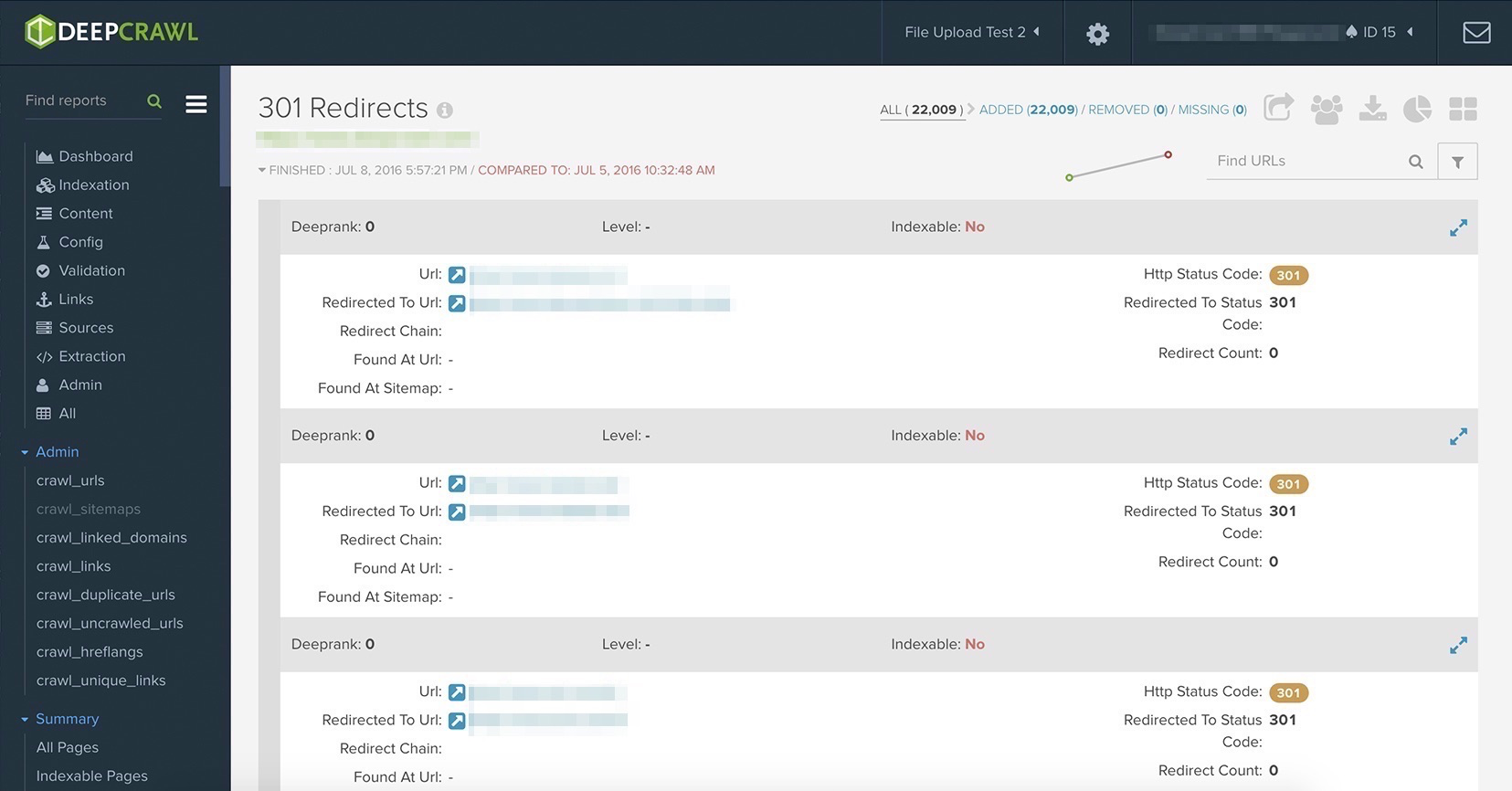
News is time sensitive, so we don’t put much focus on fixing broken external links – this would be an endless project. But over time our website has changed, we’ve shifted stuff around, come up with new content ideas, and simply killed some pages since they weren’t relevant anymore.
All of this moving around and many people working on the site resulted in a lot of unnecessary redirects and interlinking from to outdated pages. The issue I talked about before was a bug we were aware of before using DeepCrawl, but we only found out after the reports that we had more issues that had been building up over the years. DeepCrawl’s extensive Link and Redirect Reports gave us some quick insights into issues and how to solve them.
Compare Reports
When you have fixed most of the issues, a big part of SEO is monitoring and comparing any kind of fluctuations. However, doing this manually is just too time-consuming.
Data and numbers say nothing without interpretation and presentation and given the fact DeepCrawl does this with over 150 reports, it has become my go-to tool.
What next?
We haven’t used all of the features to their full extent yet, but DeepCrawl will definitely be a part of our SEO workflow with future projects.