
The latest episode in Deepcrawl’s ongoing webinar series is a deep dive into SEO and JavaScript with the Head of SEO at BitOasis, Sheikh Mohammad Bilal, and Deepcrawl’s own Chris Steele, Senior Technical SEO.
For developers, JavaScript helps to create impressively dynamic websites as well as fantastic user experiences. But when it comes to search optimization best practices, it can prove tricky for web crawlers to index JavaScript-heavy pages — which could mean lost opportunities for users to find all that impressive-looking content!
Bilal draws on his experience as head of SEO at BitOasis to highlight some key strategies SEOs can use to overcome these optimization issues for JavaScript-based sites. “Javascript is not going away,” he says, “We, as SEOs, have to evolve with it.”
Read on for the top takeaways from Bilal’s presentation on how to optimize JavaScript pages to meet Google’s Core Web Vitals, as well as his explanation of JavaScript issues relating to accessibility, indexability, media loading, and how to make sure JS-generated internal links are still indexable. (You can also watch the full webinar — as well as the Q&A session—in the video embedded above.)
JavaScript Rendering: How to Ensure Crawlability and Indexability
Bilal points to three different ways JavaScript renders site content from the perspective of search engine crawlers:
- Client-Side Rendering (CSR)
- Server-Side Rendering (SSR)
- Dynamic Rendering (DR)
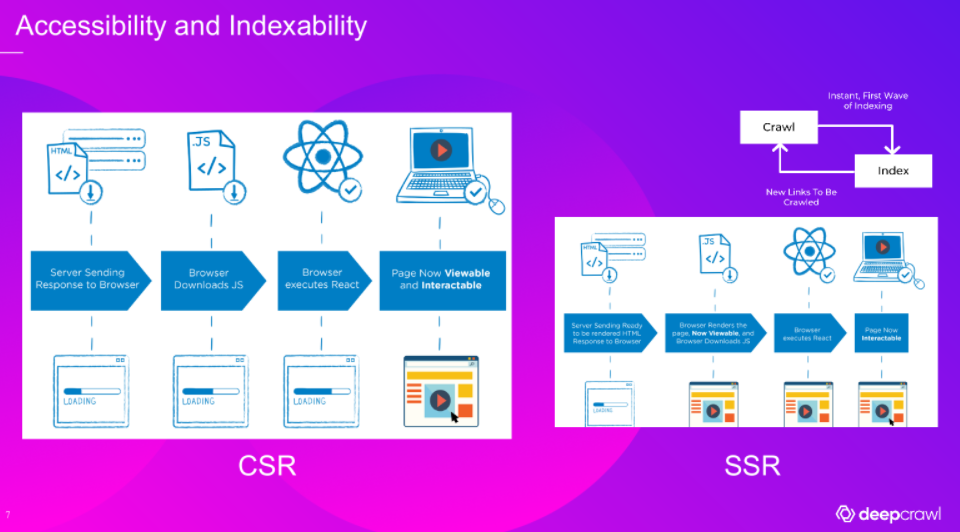
The way JavaScript-generated content is rendered can have a big impact on the crawlability and indexability of your site.
Bilal highlights that with client-side rendering when a crawler reaches a JavaScript page, the first fetch can only see empty application shells. Google can render after fetching in the first step (but other search engines such as Bing can not ‘fetch and render’), but even for search engines that can handle fetch-and-render, this can result in potentially wasted crawl budget (and anything that loads after the render won’t be crawled at all).
We can achieve better indexability across a wider array of search engines by using server-side rendering (SSR), where rendering is much more instant for the crawlers. This is especially useful for big websites such as eCommerce sites, where crawl budget may be more of a concern as you would be expecting the search engine to crawl and index hundreds of thousands of pages.
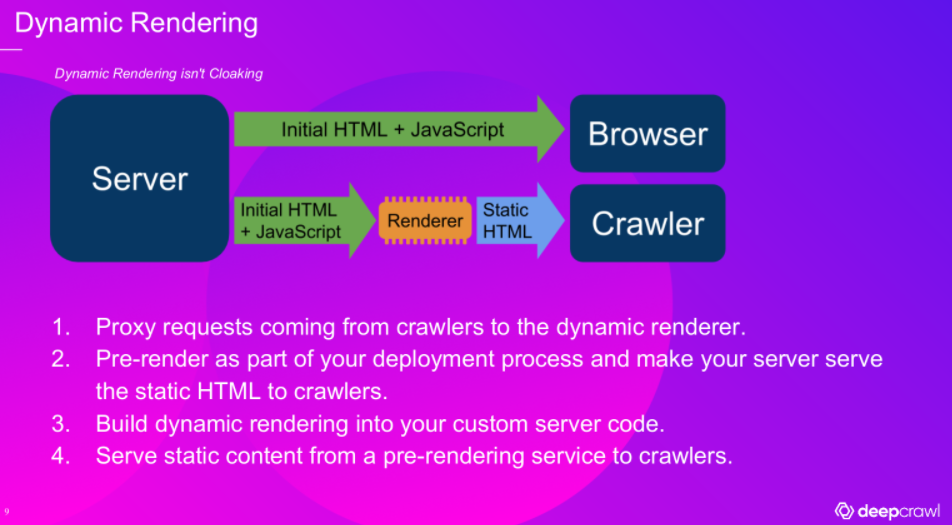
SEO Best Practices for Creating Internal Links with JavaScript
We have seen how content loaded by JavaScript can be difficult for web crawlers to cope with.
Bilal also highlights that internal links generated by JavaScript might not be crawled at all if they are not implemented properly. This can have massive repercussions for how search engines crawl and index your site.
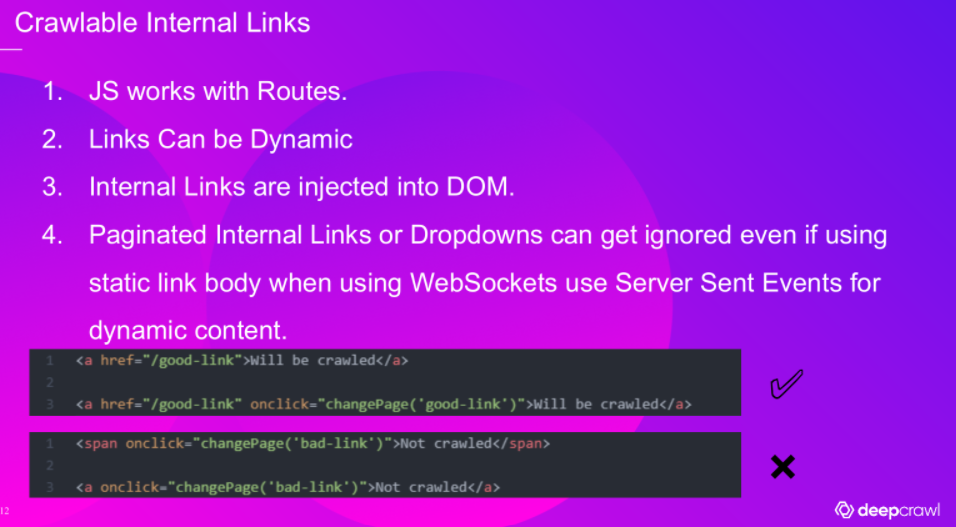
In his example, Bilal points to standard ‘href’ links that are easily crawled by search engines in comparison to a ‘bad’ example that would be less likely to get indexed by search engines, where a JS-generated link uses ‘span onclick’. While both of these are visible to the user, and both were crawled – Google still excluded the latter from its index because of the particular way those links were implemented. Even if your JavaScript is generating links a user can access, for SEO purposes, you should double-check that your JS implementation methods for links are not impacting indexability.
Media Loading Issues with JavaScript
Bilal highlighted that it is important to note the differences between how websites are seen by users compared to how Google’s crawlers ‘view’ a website. For example, when Google crawls a page, it doesn’t scroll down the page as a user would, but rather takes the page as a whole —utilizing what is known as a ‘view port’.
For pages with a long scroll, many developers will use Lazy Loading for images, so that they are not loaded until needed, in order to try and conserve resources and improve the time it takes for a page to load for a user. Googlebot does support lazy loading, but it cannot scroll a page like a user would, so it needs to resize its viewport in order to see the whole content. So you want to make sure your images are lazy-loaded not with a ‘scroll identifier’, but with an event ‘listener’ that can be tied to when the page DOM is complete.
Bilal says there are several things to remember when using Lazy Loading:
- Don’t lazy load images ‘above the fold’.
- Do use a lazy load JS library for browsers that do not yet support lazy loading.
- Ensure to scale the images according to the viewport (consider scale for mobile viewports)
JavaScript, Page Speed, & Core Web Vitals
Bilal also has some recommendations for improving Core Web Vitals performance on JavaScript sites. They are:
- Minify JavaScript to streamline code making it smaller and faster to load. (Numerous minifiers are available.)
- Defer non-critical JavaScript until after the main content is rendered in the Document Object Model (DOM).
- In-line critical JavaScript for quick above-the-fold loading or serve JavaScript in smaller payload bundles as recommended by Google (separate for critical elements)
- If you are using tracking or other 3rd party tools, place those scripts in the footer being lazy-loaded, if possible.
- Stay up-to-date with web.dev and Google’s Search Central Blog for any new updates regarding speed optimizations and performance for JavaScript web apps.
For more on JavaScript rendering best practices, check out Deepcrawl’s SEO Office Hours recaps on JavaScript rendering, or our Guide to JavaScript for SEO.
Want more Deepcrawl webinars? Check out our full archive of on-demand webinars.


