

Lumar allows users to crawl XML Sitemap URLs and any URLs found in a Sitemap file.
To add XML Sitemaps to a new crawl project follow these instructions:
Start a New Crawl Project
Create a new crawl project in Lumar.
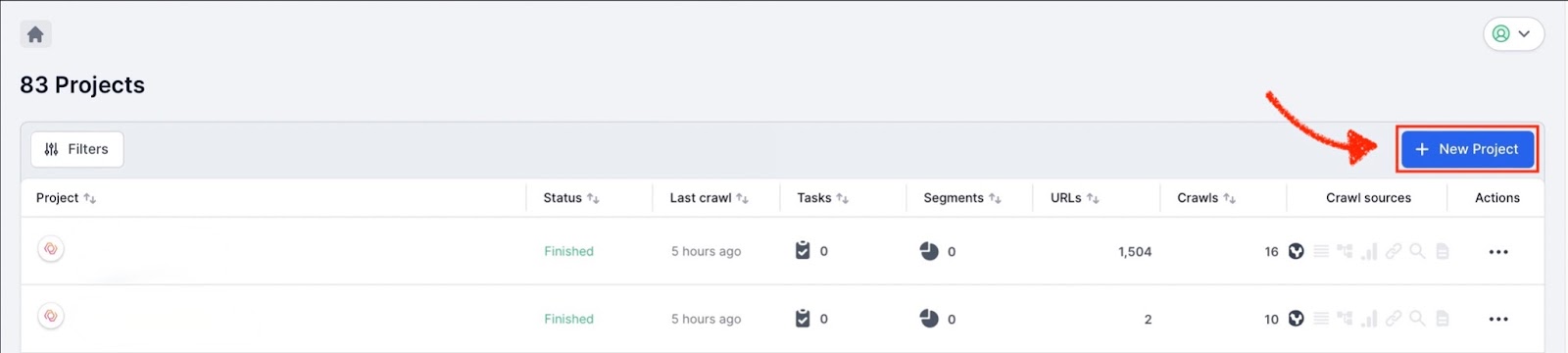
Enter the primary domain where the XML Sitemap files are located and name the project (enable JavaScript rendering if you want to use the Page Rendering Service).
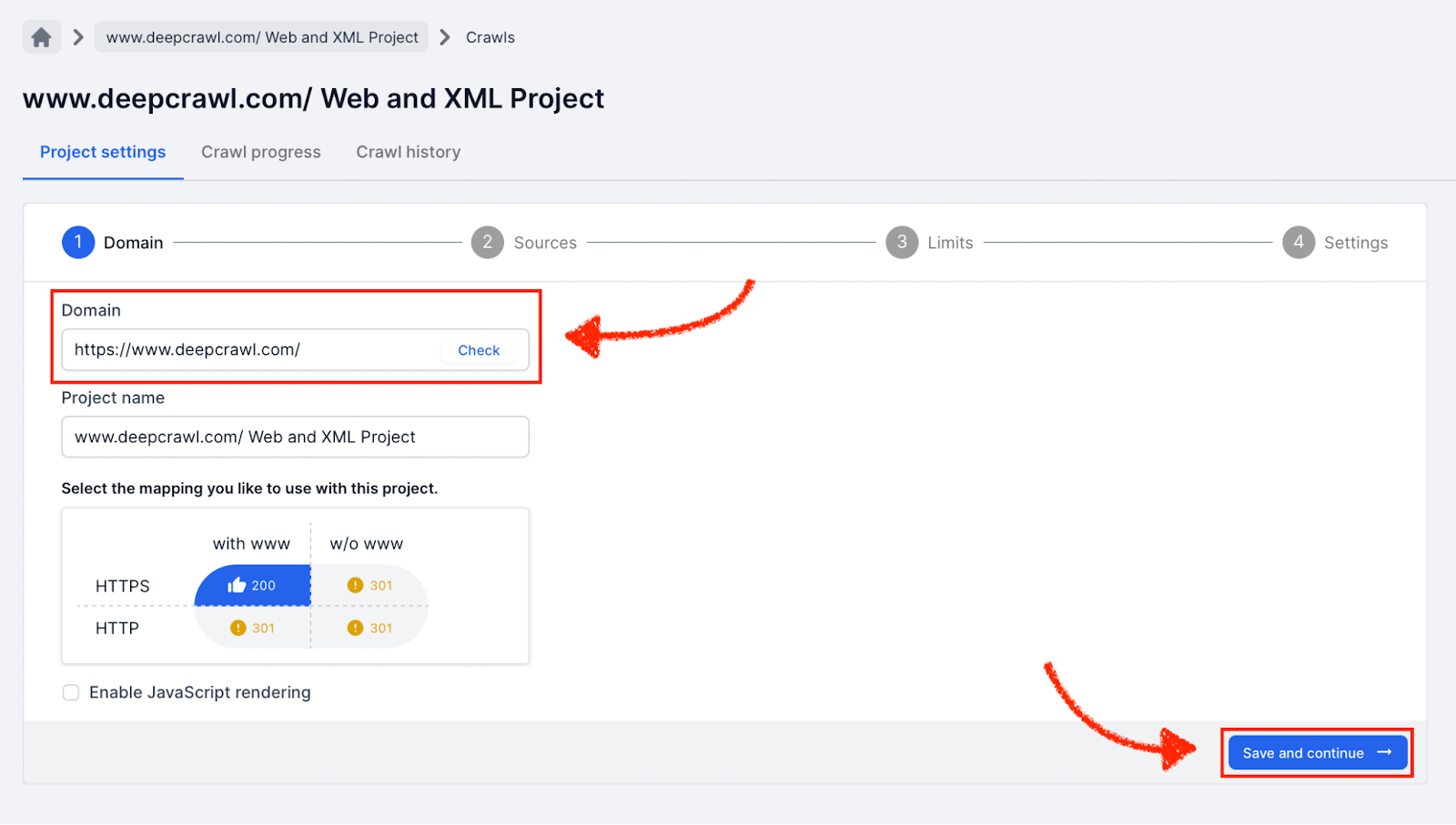
Source Settings
In the Sources settings select the Sitemaps option. By default Lumar discovers and crawls XML Sitemaps using the /robots.txt file.
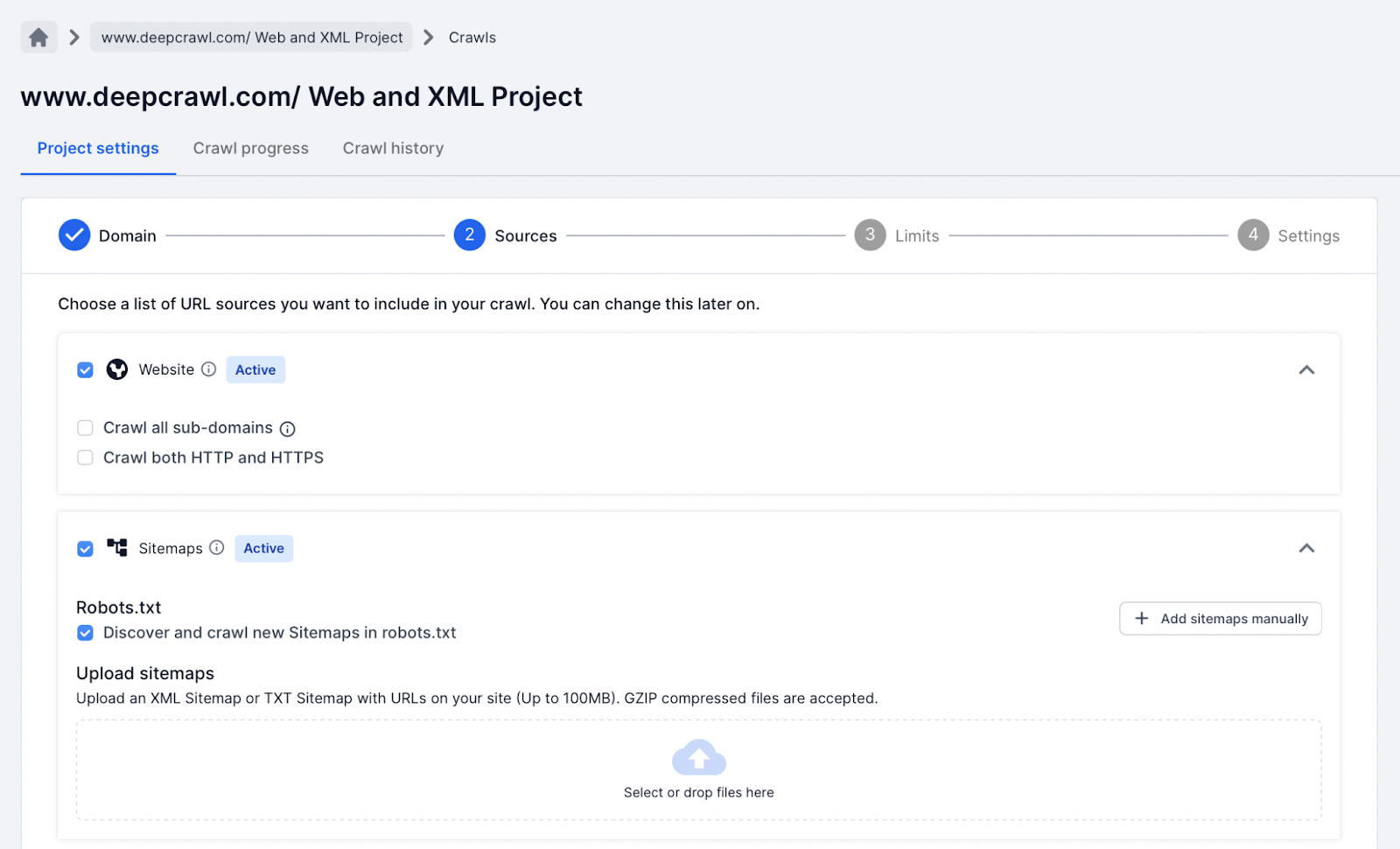
How to Add XML Sitemaps to Lumar
When adding Sitemaps to a crawl project, there are a number of options that help Lumar discover Sitemap URLs:
- XML Sitemaps referenced in the /robots.txt file (this is done by default).
- Manually copy and paste XML Sitemap URLs into Lumar.
- Manually upload .xml or .txt files into Lumar.
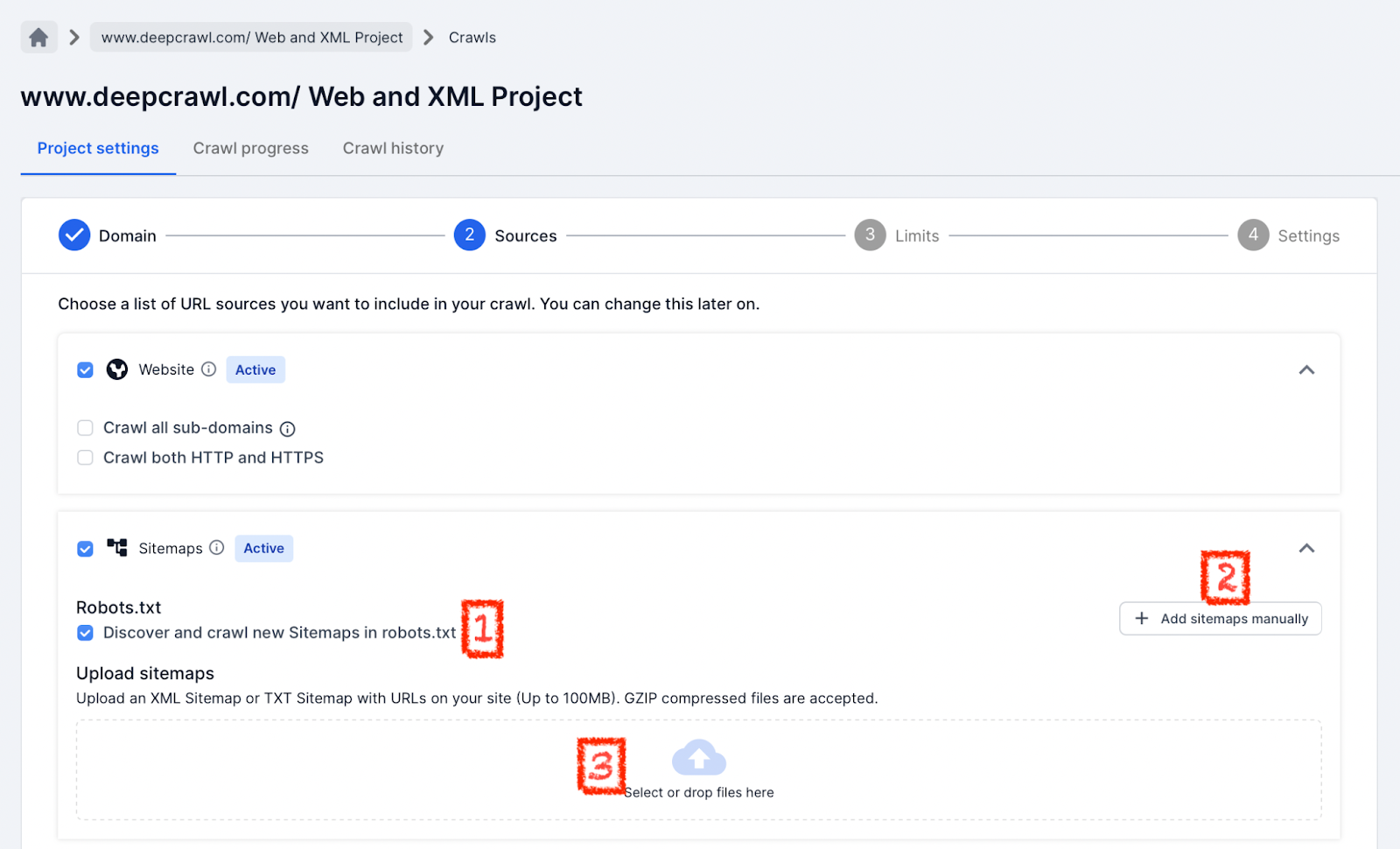
Discover XML Sitemaps Found in Robots.txt File
By default, Lumar will discover any XML Sitemap URL in a /robots.txt file when selecting the Sitemaps data source.
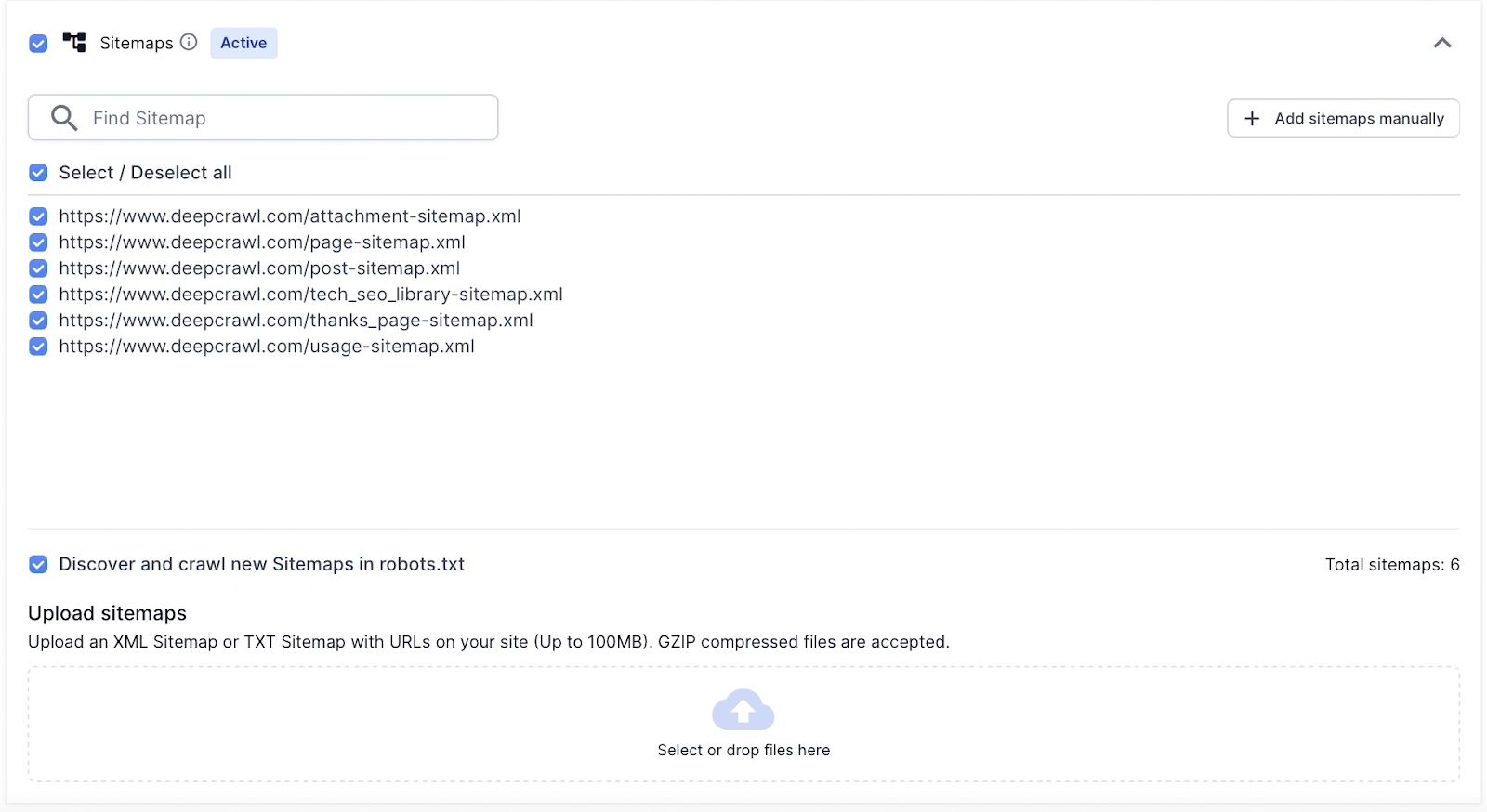
This means that any Sitemap URLs found in the /robots.txt will be automatically pulled into the list of Sitemaps Lumar will crawl.
For example the following /robots.txt file:
User-agent: *
Sitemap: https://www.example.com/sitemap_index.xml
Lumar would discover the Sitemap Index and crawl all the XML Sitemaps contains within that file. Any Sitemaps not included within that Sitemap Index would not be discovered and crawled by Lumar in this example.
If you do not want Lumar to discover XML Sitemaps in the robots.txt file in future crawls then unselect it in the Sources settings.
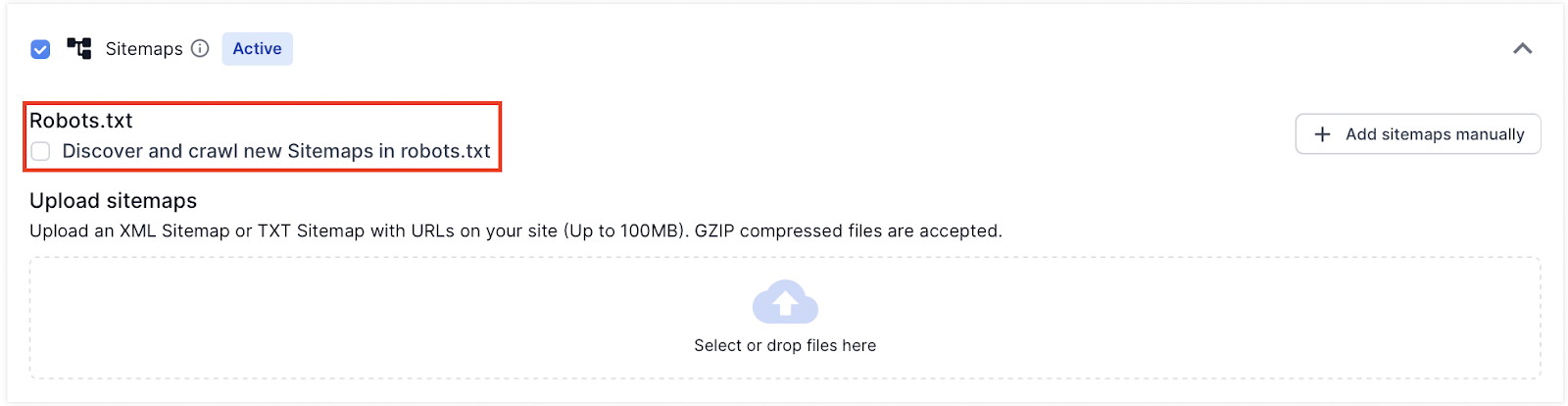
Remember to deselect the Sitemaps found in the /robots.txt, as they are not automatically deselected when deselecting the robots.txt option.
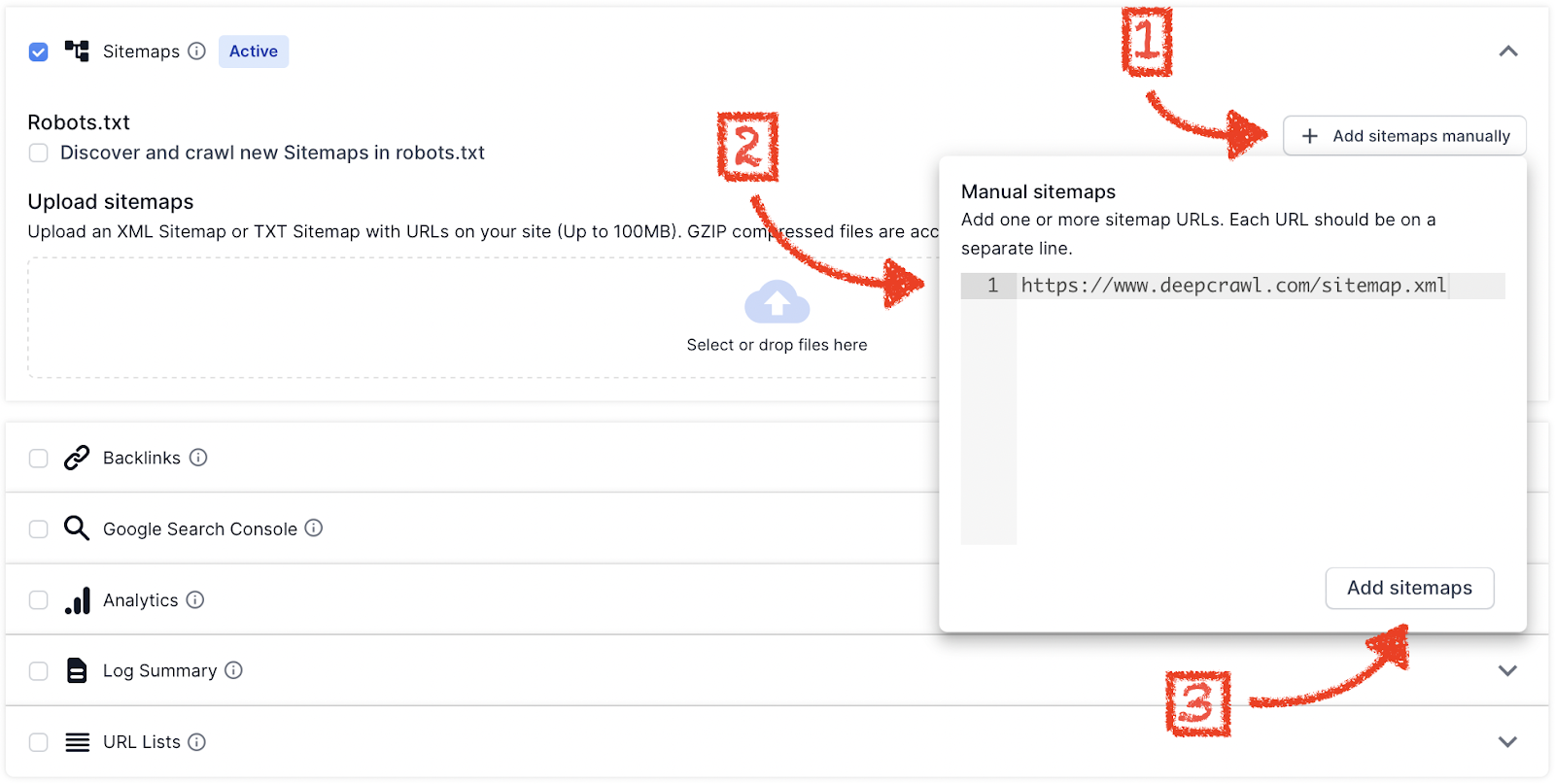
Add XML Sitemap URLs Manually
If XML Sitemaps cannot be found in the /robots.txt, then they can be added into Lumar manually.
To add Sitemaps manually to Lumar:
- Create a list of all your XML Sitemaps.
- Copy all the XML Sitemap URLs and paste them into the into the input box.
- Click Add Sitemaps.
When the new Sitemaps are added manually, they will be added to the list of XML Sitemaps which Lumar will discover and crawl.
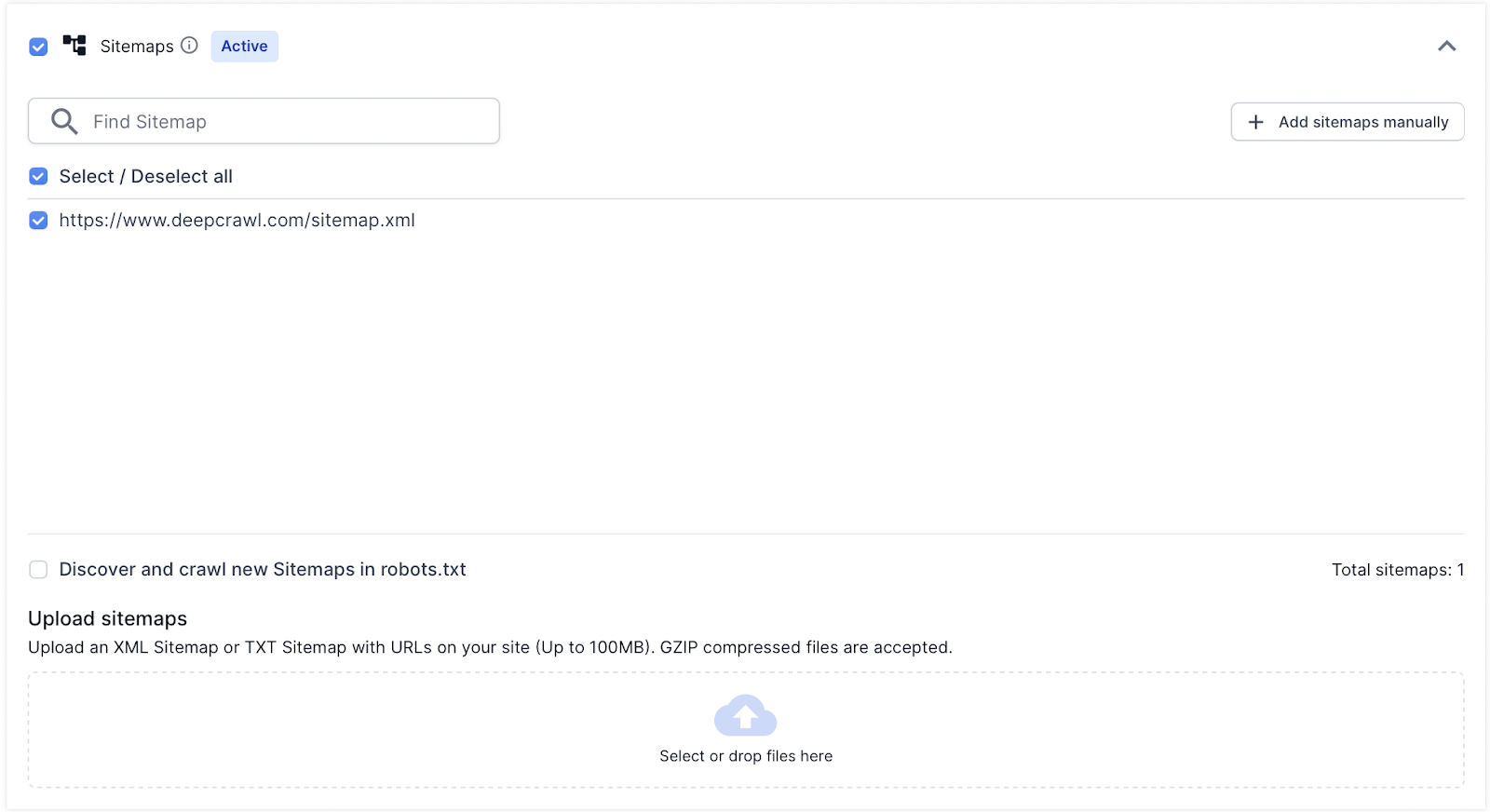
Once a list has been generated, Lumar also gives you the option to select or deselect the files from being crawled in the project.
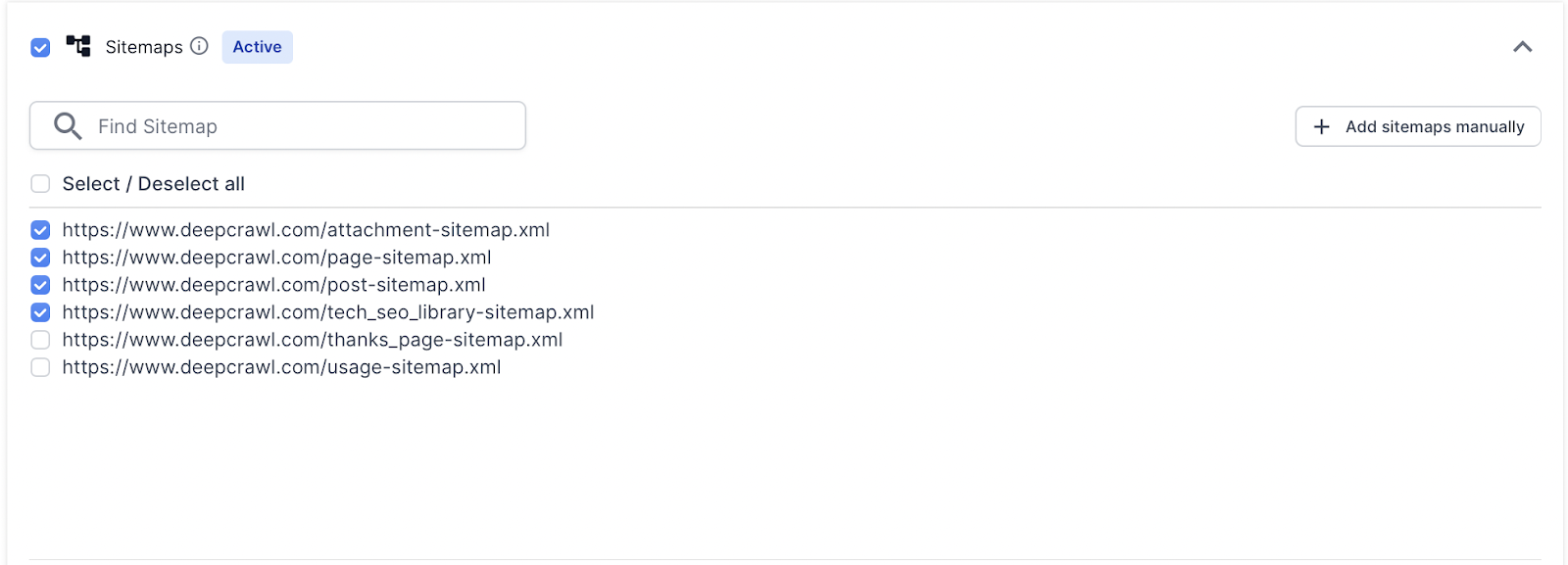
This is useful if you don’t want to crawl every single Sitemap uploaded.
Upload Sitemaps
Lumar gives the option to manually upload .xml and .txt files, which can be used as XML Sitemaps.
This option is very useful if web development and technical SEO teams who wish to test Sitemaps before they go live.
To upload a .xml or .txt file:
- Create a list of URLs you want to include in the .xml or .txt Sitemap.
- Create an XML Sitemap file or .txt file and include the URLs you want crawling by search engines (follow the Sitemap best practices guidelines).
- Upload the Sitemap file to Lumar (no more than 100MB per file upload and Lumar accepts gzipped compressed files).
Once a file is uploaded Lumar will display the Sitemap file names and file extensions in a list.
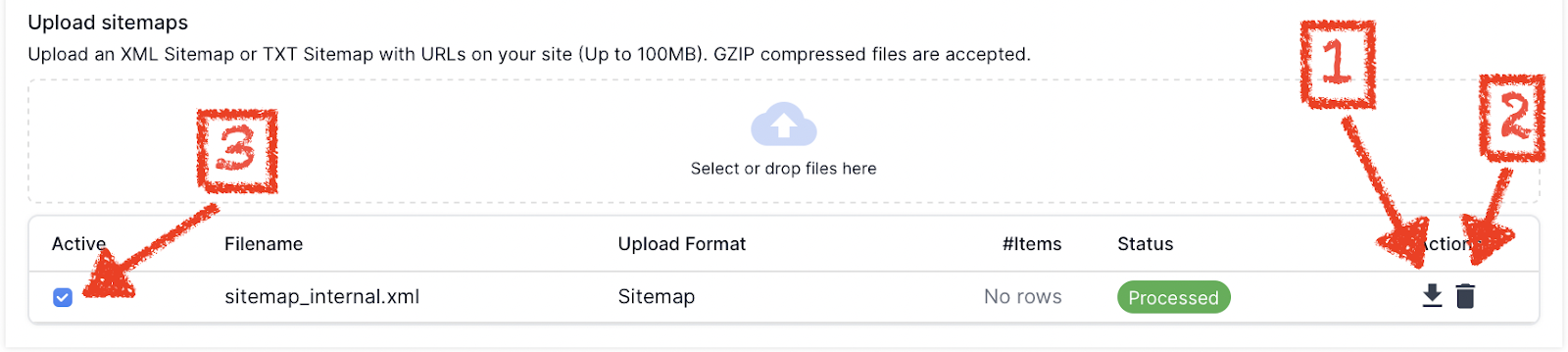
Lumar allows you to edit this list of uploaded files, from the Source settings you can:
- Download the file to make sure the contents are correct.
- Delete the file in case the wrong file was uploaded.
- Deselect the file from being crawled in the project.
Configure Crawl Limits and Advanced Settings
Once the XML Sitemaps have been added to the crawl project, then save and continue and configure the crawl limits and advanced settings.
Hit save, start the crawl and wait for the project to finalize to see XML Sitemap data included in the crawl.
Summary
Sitemaps can be added to new projects and can be uploaded in multiple different ways. When adding XML Sitemaps to a project:
- Start a new crawl project.
- Select Sitemaps in the Sources settings in a project, as well as other data sources.
- Choose which option to add an XML Sitemap (manual, file upload or through robots.txt).
- Save the Sources settings and configure the crawl limits and advanced settings.



