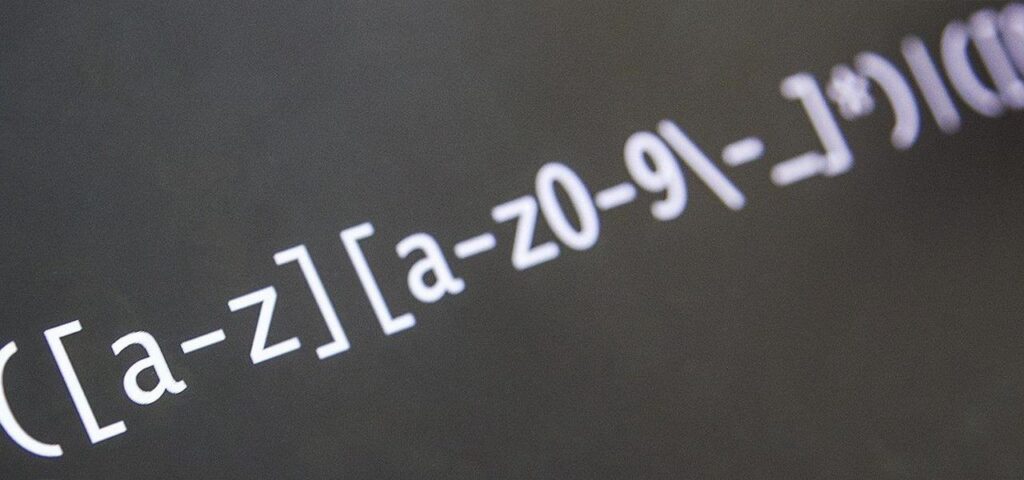

Getting started with regex
Regular expressions, aka Regex, are extremely useful for finding and/or extracting textual information from within sources such as HTML markup, log files, URLs, or even documents. Regex has a broad range of applications and is particularly useful for SEOs, as it allows us to define patterns to perform tasks such as filtering server logs, rewriting URLs, and extracting anchor text from links.
The first guide in this series will provide you with a basic introduction and understanding of regex. It’s important to note that there are many different flavors of regular expressions, each supporting varying syntax. For this document, we will focus on Ruby’s flavor of regex.

Once you’re comfortable working with this level of regex, you can begin to explore intermediate topics such as capture groups, shorthand character classes, mode modifiers and negated character classes, which we will cover in future guides. Looking beyond that, more advanced topics include conditional matching, look-around, catastrophic backtracking, and atomic grouping.
Patience is encouraged – it’s ok to explore some of these topics in any order, but developing a strong understanding of the fundamentals will be most beneficial. With practice, trial and error, you’ll be able to employ regex within Lumar projects and reports, empowering you to squeeze even greater value from our tool.
We will use Rubular.com for testing examples used within this document. Note that while not required by other regex flavors, Rubular requires that you escape forward slashes (‘/’) with a backslash (‘’), because Ruby uses ‘/’ to identify some reserved uses.
Basic regex tokens
Just what are Regular Expressions, and what’s so regular about them? In a nutshell, regex can be as deceptively simple as x. On the other hand, regex can be frustratingly, confusingly difficult with patterns such as: //[^/]+/(?:blog/)?(?!dcb|sfb) ([a-zA-Z]{2}(?:[-_](?:[a-zA-Z]{2}|d{2,3})b)?)(?:/|$).
Regex patterns can be used to search within any text, short or long, such as URLs, HTML markup, or server log files which may comprise multiple gigabytes of data. In addition to finding specific text within a document, regex also allows you to search for text that appears in specific arrangements. For example, a conventional search for que will match the following words: quest, obliqueness or risque.
Above all, regex is very powerful and amazingly useful! Think of it as text search with wildcards on steroids. Seemingly impossible searches, such as “find all words containing a q that are not followed by a u”, are easily accomplished using regex.
As you may have guessed, there are many reserved characters and character patterns that have special meaning in regex. These are referred to as Regex Tokens. Here are a few that are commonly used (the ‘→’ is not a regex token):
. → Matches ANY single character
* → Matches Zero or More characters
+ → Matches One or More characters
? → Matches Zero or One character, asserting that the preceding regex is Optional
The most basic of all regex tokens is the dot operator, .. It’s used as a single character wild-card. That is, . will match any single character, whether a letter, numeric digit, whitespace or punctuation. Repetition is specified using the tokens * or +. To match any character one or more characters of any type, use .+.
So to jump right in, a regex pattern of the.. will match the words there and their, but not them, because the pattern specified exactly 5 characters. Changing the previous regex to the.* will match all three words, there, their and them, in addition to the word the, because the repeated token .* will match any character zero or more times.
If you want to include a reserved metacharacter in your search, simply escape it with a backslash to treat it as a literal character. For example, dog. will match dog. (note end of sentence), but it will not match dogs.
If you want to find both singular and (simple) plural versions of a word, you can add the question mark token after the s to make it optional, so dogs? will match both words, dog and dogs.
It’s important to understand that by default, regex is greedy. This means that using a pattern such as .+ will match at least one character starting from the current position all the way to the end of the source string. So if you wanted to match only the salutation in the sentence “Please call her Ms. Smith.”, you might be tempted to use M[rs]+. (for Mr, Ms or Mrs). However, because regex is greedy, this would capture all the way to the period at the end of the sentence, Ms. Smith.. To make the + lazy, follow it with a ?, as in M[rs]+?.., which will then capture as intended: Ms..
Regex refinements
In addition to using tokens and literal strings to write regex patterns, a wider net can be cast using Refinements such as Alternation, Grouping, Character Sets, Quantifiers and Anchors. The tokens used to refine regex expressions are:
| → Alternation: specifies alternative patterns – same as OR
() → Grouping: parentheses are used to identify Groups
[] → Character Set / Class: match Any One of the characters within the brackets
{x,y} → Quantifier: asserts the regex must be matched Between X and Y Times
^ $ b → Anchor: matches at a specific, relative Position, not a specific character
Alternation & grouping
It’s often convenient to provide multiple regexes, any of which would be a match. For example, to find any of the words “travels”, “traveler” or “traveling”, you can use | (the pipe symbol) to separate the list of alternative words, as in travels|traveled|traveler|traveling. This is known as Alternation.
To simplify long expressions and improve readability, parentheses can be used to Group certain parts of the regex. Doing so, the previous regex can be simplified as travel(s|ed|er|ing), meaning to match the literal string travel, followed by either s, ed, er or ing.
But what about spelling variations such as the Brits’ preference for double-l as in “travelled” or “travelling”? Simply use the ? token to make the second l optional: travell?(s|ed|er|ing). This regex will now match any of the following words: travels, traveled, travelled, traveler, traveller, traveling or travelling.
Character sets & character classes
A Character Set is a simple list that can be used to match any single character listed within square brackets. Alternation using the pipe symbol (|) is not required to separate the list of characters. For example, [aeiou] will match any single vowel and [wkrp] will match only the letters w, k, r, or p.
A Character Class is an ordinal range of similar characters, separated by a hyphen (–) and listed within square brackets. A character class represents a specific family of characters, such as letters of the alphabet or numeric digits. For example, [a-z] represents any letter of the alphabet, and [0-9] represents any numeric digit.
Note that most flavors of Regex are case-sensitive by default. This means the character class [a-z] will match only lowercase letters. Use [A-Z] to match uppercase letters.
Also, the order of the characters inside a character class does not matter, so [z-a] is equivalent to [a-z]. Clearly, character classes are much simpler than listing all 26 letters (52 if you want a case-insensitive match), or even all 10 digits within a character set, such as [0123456789].
Similar to listing multiple characters as a character set, you can combine multiple characters and character classes. This regex character set is comprised of three distinct character classes, and it will match any single character that is either a number, letter (upper or lowercase), underscore, or comma: [0-9A-Za-z_,].
A character class can also represent a partial range of characters. For example, [a-m] will match only the first 13 letters of the alphabet, such as The quick, brown fox jumps over the lazy dog. Similarly, [A-Fa-f0-9] will match any hexadecimal number such as 7A (122) or F1 (241).
When followed by a token such as +, you can expand the default scope of matching any single character to one or more matching characters. For example, the regex [A-Za-z0-9]+ will match one or more of any letter or number combination, comprising any single word of any size and in any case.
Quantifiers
Quantifiers in the form {x,y} allow you to specify the number of times a regex token should be matched, from x to y times, where both numbers are integers. If only one value is present, as with {x}, the regex token should be matched exactly x times. Alternatively, a single value can either be preceded by or followed by a comma. In the case of {x,}, the regex should be matched at least x times. To assert that the regex should be matched at most y times, the syntax is {,y}.
Consider the subject string of “I’m pleased to make your acquaintance”. To find any combination of 2 or 3 vowels, you would write the regex as [aeiou]{2,3}, to match the strings of “ea”, “ou” and “uai” in the words “pleased”, “your” and “acquaintance”, respectively. To remove the upper limit of 3 vowels from your search, the regex would be [aeiou]{2,} and would still match the same three strings. Lastly, to match only strings of exactly three vowels, the expression would be [aeiou]{3}.
Anchors
Regex allows you to further refine your search target based upon context, or the specific position of your search text, using special tokens known as Anchors. These are zero-length – they do not match any characters, but rather a position. Here are the most common regex anchors:
^ → Asserts that the following regex must match at the Beginning of the text
$ → Asserts that the preceding regex must match at the End of the text
b → Asserts that this position marks a Word Boundary
For example, if you wanted to search for “it was the best”, but only at the beginning of the text string, you would use ^it was the best to find “It was the best of times, it was the worst of times…”, the opening words of Charles Dickens’ Tale of Two Cities. If the ^ anchor is omitted, red herrings may result, such as “regarding Friday, it was the best day of my life” or “thanks for the gift – it was the best!“, neither of which starts at the beginning of the text.
Expanding on our first example from Regex Tokens, what if you wanted to find que, but only when positioned at the end of a word? This is where the anchor b comes in to mark a word boundary, meaning that the only characters allowed to adjoin your target pattern at this position are spaces, punctuation or non-word characters such as hyphens, ampersands, etc. Your regex would be queb and would match “baroque” or “bisque“, but not “banquet”. Further, if you wanted only the whole word “que”, you would simply use bqueb.
Note that the pattern queb will match “risque” as well as “que“. If you only wanted words with 4 or more letters that end in “que”, you would use .+queb.
Putting it all together
To advance your regex acumen, here are some examples that employ the topics covered above. Beyond the regex basic expressions, this section is intended to improve upon some previous examples or expose omissions, potential caveats or red herrings.
Alternative to alternation
Suppose you wanted to find either 5-letter word, “there” or “these”, but no others. You could use the regex the.e, but this would also match words such as “theme” and “thebe”. To match only “there” or “these”, you could use there|these, or nicely grouped as (there|these). However, using a character class, you can specifically specify (tongue twister intended) that the 4th letter must be either “r” or “s” by using the[rs]e. Example: https://rubular.com/r/uSoqH4T8nG
‘Travel’, revisited
Let’s revisit our travel example from the Alternation & Grouping section. As you’ll recall, we ended with travell?(s|ed|er|ing). That regex will match any of 7 suffix variations of the word travel, also allowing for the alternative spelling with two l’s.
As we know you’re very astute, I’m sure you noticed that it does not match the root word itself! To do that, simply make the alternation group optional: travell?(s|ed|er|ing)?. This regex will now match the word “travel”, followed by an optional “l”, followed by any of the optional suffixes, “s”, “ed”, “er”, or “ing”.
However, this regex will also match the root word of the brand “travelocity”. To avoid false positives such as this, remember to add the word boundary token: travell?(s|ed|er|ing)?b. Example: https://rubular.com/r/i0aagNR71Y
HTML tags
A common use case for regex in the world of Lumar is custom extractions. Grabbing a basic tag such as <h1> is easily accomplished using (<h1>.*</h1>). But what if the <h1> has a class property such as <h1 class=”JX0GPIC-a-g”>, where the class value is of variable length or perhaps additional properties are present? We’ll cover this scenario in the second part of this guide, but here’s a sneak peek using a negated character set: https://rubular.com/r/BzDQfSjwBu.
Use regex to get more out of your crawls
If you’re interested in finding out how to get the most out of your crawls, then you can learn more about using regex in custom extractions in this guide. If you’re yet to be introduced to Lumar, then why not sign up for an account today to find out how you can improve your site’s technical health.



