

You can crawl your staging or test environment and compare it to your live website to see how they are different.
This can help you test a version of your website or part of your website before you release it to the live environment and check new site wide additions such as canonical tags, social tags or page pagination implementation etc.
Please note: Differences in data between the test and live sites are likely to have an impact on the results of any comparison crawls. Your test site may not contain all elements from your live site, or may have different meta data which affects how pages are reported, such as a site-wide ‘noindex’ tag.
Test Website Settings
1. Set up a new project and run a crawl of your live site (don’t enter your test site details yet).
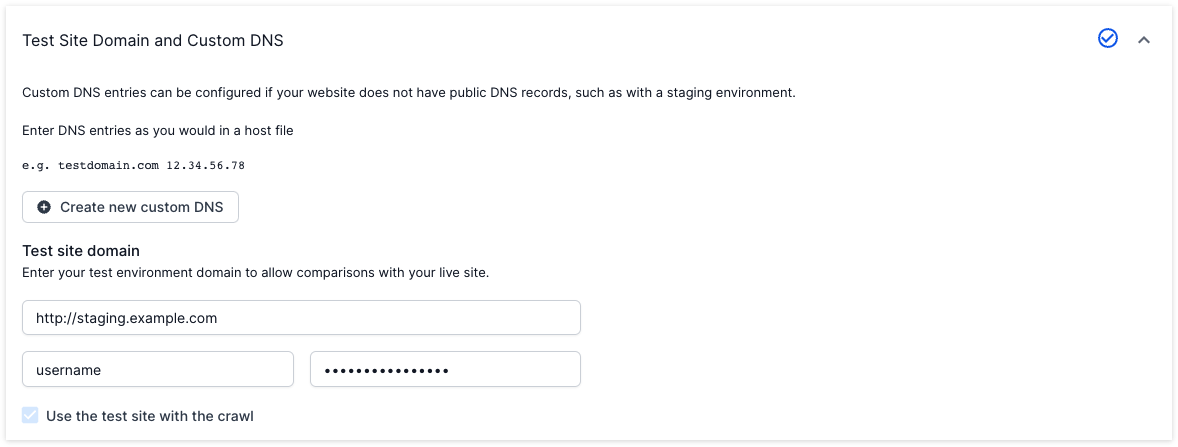
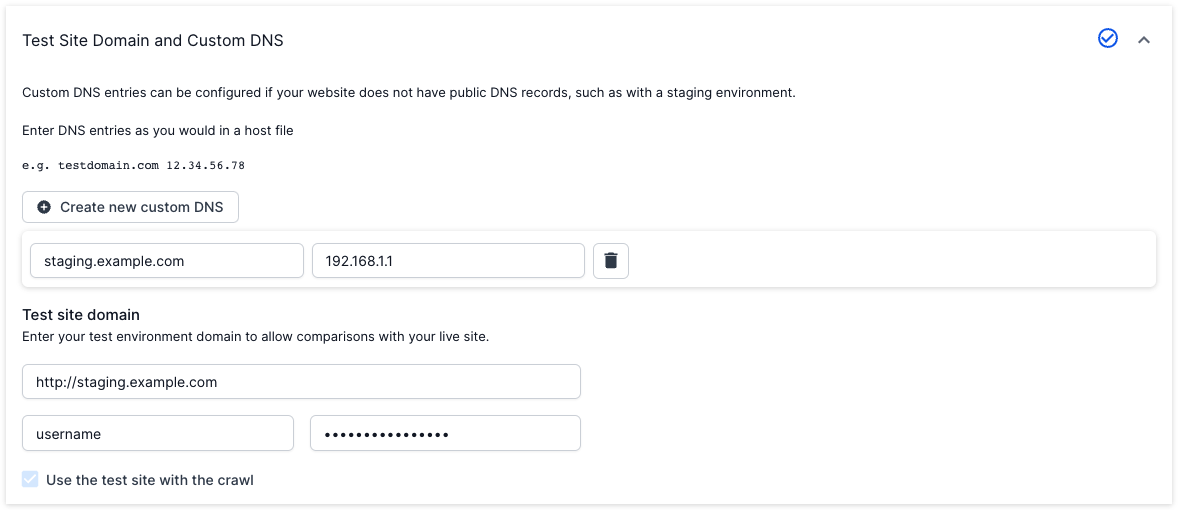
2. Once the crawl completes, return to ‘Advanced Settings’ in step 4 of the project setup and enter your test site details in the ‘Test Site Domain and Custom DNS’ section. The ‘Use the test site with this crawl’ setting will be pre-checked. If your test site is protected by a basic auth username and password, you can add these to Test Site Basic Authentication settings.
 3. Make sure that your project is set up to compare the crawl results to the last crawl.
3. Make sure that your project is set up to compare the crawl results to the last crawl.
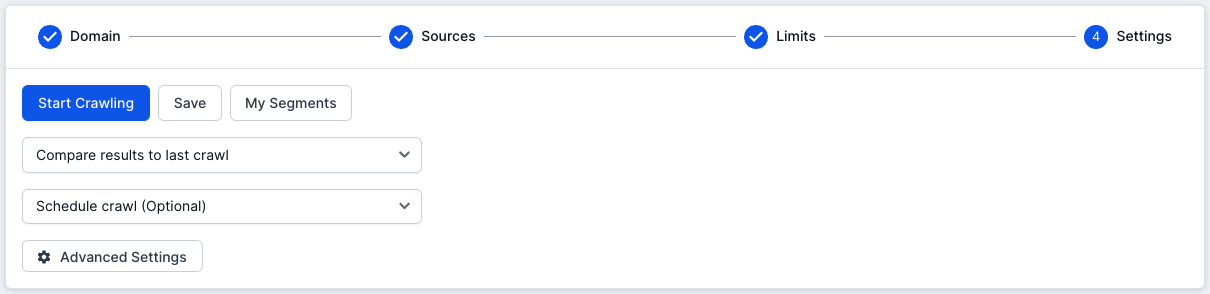
4. Run the crawl again to start crawling your test site, which will be compared to the previous crawl of the live site.
Robots Overwrite
Test site environments sometimes have a robots restriction in place to stop undesired traffic or crawling activity.
The most common type of restriction is to block the entire test site using the Robots Disallow directive in the robots.txt file, which stops crawlers from crawling the site.
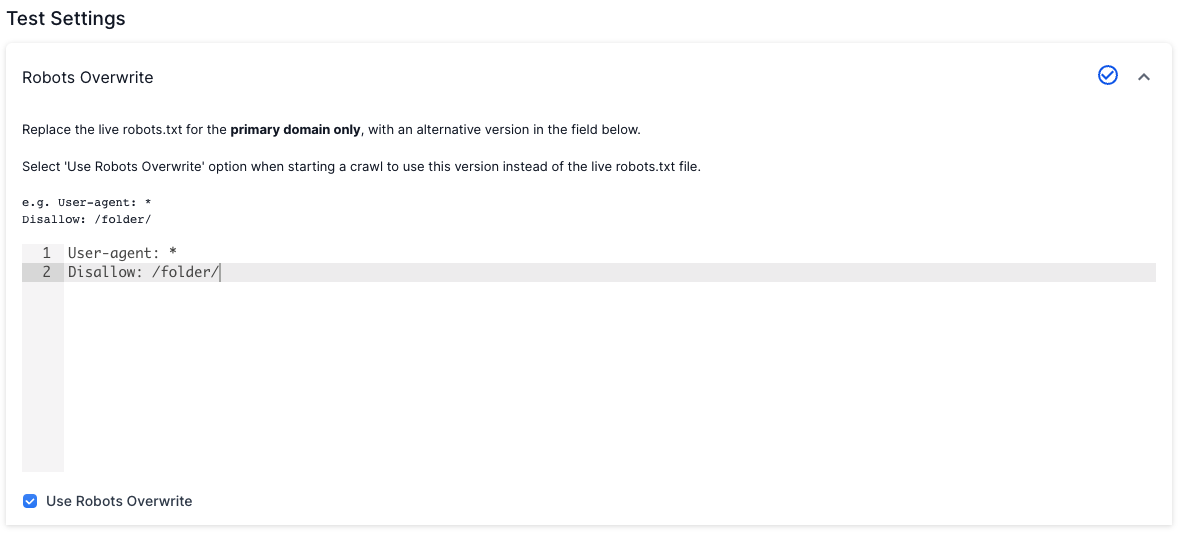
Lumar has a Robots Overwrite feature that allows you to input a different Robots rules to override these restrictions, and ensure that the URLs are not reported as Disallowed.
To set this up, head to Robots Overwrite in Advanced Settings and enter the robots.txt content you would like to use for the crawl. This could be a copy of the robots.txt from your live site, or an ‘Allow all’. e.g.
User-agent: *
Allow: /
Test site blocked from public access?
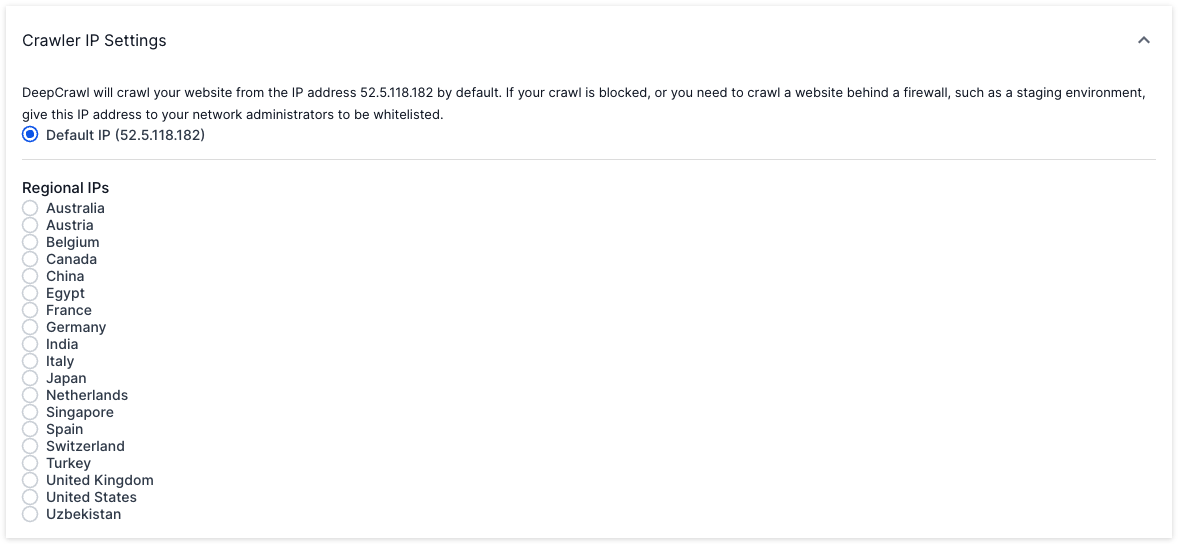
Your staging environment may be blocked from public access which can prevent it from being crawled by Lumar. You can ask the server administrators to whitelist the IP addresses that Lumar uses to crawl. Please ensure they whitelist both 52.5.118.182 and 52.86.188.211.
Test sites without public DNS records
Sometimes test site environment domains are only configured with DNS records within the company network and they will not work externally.
You can add custom DNS settings into the ‘Test Site Domain and Custom DNS’ section, under ‘Test Settings’ in ‘Advanced Settings’.
For further reading on using Lumar to compare a test website to a live website, check out Glenn Gabe’s Search Engine Land article: 5 Ways To Crawl A Staging Server Before Important Site Changes Go Live (To Save SEO).



