

If you want to crawl a website with an AJAX application, you will need to use the AJAX crawling feature to allow Lumar to access the links and content on the site.
Note: Google stopped using the AJAX crawling scheme at the end of quarter 2 of 2018. If you are relying on the AJAX crawling scheme for Google to crawl and index dynamic content, then this is no longer supported. For more information on getting JavaScript websites crawled and indexed please read new Google Developers documentation.
In this guide we will be focusing on:
- What is AJAX?
- How does the AJAX crawling scheme work?
- How do I configure Lumar to crawl AJAX websites?
What is AJAX?
The term AJAX stands for Asynchronous JavaScript and XML. It is a technique used by developers to create interactive websites using: XML, HTML, CSS, and JavaScript.
AJAX allows developers to update content, when an event is triggered, without having to make the user reload a page. Although an AJAX website can create an excellent experience for users, it can cause server issues for search engines.
The main problems with AJAX websites are that:
- They do not create unique URLs for a page, instead they create a # for a page.
- The on-page content dynamically generates once a page has loaded.
Both problems stop search engines from crawling and indexing dynamic content on a website. To manage these problems, Google came up with the AJAX crawling scheme which allows search engines to crawl and index these types of websites.
How does the AJAX crawling scheme work?
A website that implements the AJAX crawling scheme provides search engine crawlers with a HTML snapshot of a dynamic page. The search engine is served an “ugly URL”, while the user is served with the dynamic “clean URL” of a web page.
For example:
- Clean URL in the browser: https://www.ajaxexample.com/#!hello
- Ugly URL for crawler: https://www.ajaxexample.com/?_escaped_fragment_=hello
For an overview on how to create HTML snapshots and the AJAX crawling scheme read the following official guide by Google.
How to configure AJAX crawling in Lumar
When configuring Lumar it is important to make sure that:
- The AJAX website supports the AJAX crawling scheme.
- The advanced settings in the Lumar project are updated.
Supporting the AJAX crawling scheme
Our team recommends following the AJAX crawling scheme instructions to implement it on an AJAX website. It is important to note that there are two ways to indicate the scheme: An AJAX website which has hashbang (#!) in the URL, and AJAX websites which do not include a hashbang (#!) in the URL.
Our team has provided further details below for each setup and how it impacts Lumar.
AJAX websites using hashbang URLs (#!)
For Lumar to crawl an AJAX website which has a hashbang in the URL it needs the following requirements:
- The AJAX crawling scheme is indicated on clean URLs using hasbang (#!).
- The site’s server should be setup to handle requests for ugly URLs.
- The ugly URL should contain the HTML snapshot of the page.
If these requirements are not met, then Lumar will be unable to crawl an AJAX website.
AJAX websites without hashbang URLs (#!)
For Lumar to crawl an AJAX website without a hashbang in the URL it needs the following requirements:
- AJAX crawling scheme is indicated on clean URLs using meta fragment tag.
- The _escape_fragment_ parameter is appended to the end of clean URLs.
- The ugly URL should contain the HTML snapshot of the page.
The meta fragment tag and _escape_fragment_ parameter only need to be included on pages that are using AJAX. They do not need to be added to every page of a website, unless all pages use AJAX to load content.
Updating Lumar settings to crawl AJAX websites
Once the website is updated to properly indicate the AJAX crawling scheme to search engines, you will need to update the ‘URL Rewriting’ settings in ‘Advanced Settings’.
1. Firstly, uncheck the ‘Strip # Fragments from all URLs’ box. This will force Lumar to crawl the hashed URLs.

2. Then create the following three rules in the URL rewriting settings.
| Match From | Match To | Case Options |
|---|---|---|
| #! | ?_escaped_fragment_= | No Change |
| ^(?!.*?_escaped_fragment_=)(.*?.*) | $1&_escaped_fragment_= | No Change |
| ^(?!.*?_escaped_fragment_=)(.*) | $1?_escaped_fragment_= | No Change |
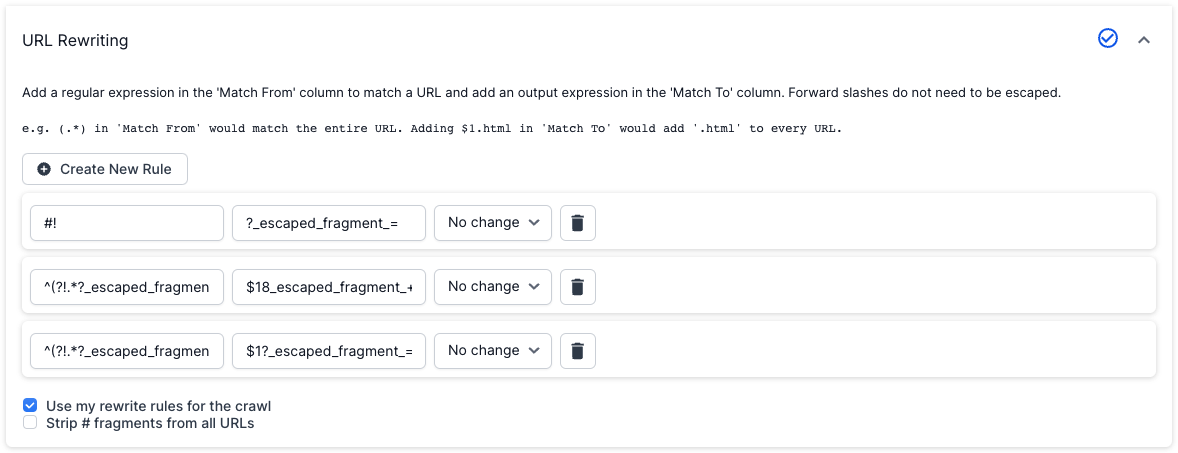
3. Hit “Save” at the bottom of the advanced settings in the project to save the rewrite settings.
4. Run a test crawl to see if the new project settings are working.
How does the URL rewrite rule work?
The first rewrite rule will replace #! with _escaped_fragment_= in all URLs, for example:
Pretty URL: www.example.com/document#!resource_1
Rewritten URL: www.example.com/document?_escaped_fragment_=resource_1
This will allow our crawler to access the HTML snapshot of the page.
The second rewrite rule will append the escaped fragment onto the end of a URL that contains parameters, for example:
Pretty URL: www.example.com/document/?resource_1
Rewritten URL: www.example.com/document/?resource_1&_escaped_fragment_=
The third rewrite rule will append the escaped fragment onto the end of a URL that does not contain parameters, for example:
Pretty URL: www.example.com/document/resource_1
Rewritten URL: www.example.com/document/resource_1?_escaped_fragment_=
These rules will also allow for links on the website, which already contain the ‘?_escaped_fragment_’, in which case the solution should not be appended.
Frequently Asked Questions
Why does Google no longer support the AJAX crawling scheme?
Google stopped officially crawling #! URLs in the summer of 2018. They have stopped supporting this scheme as Googlebot can now render AJAX websites using the web rendering service (WRS).
Do any other search engines support the AJAX crawling scheme?
At the time of writing this guide, Bing and Yandex still support the AJAX crawling scheme. Neither of these search engines have announced plans to stop supporting the AJAX crawling scheme.
How long will Lumar support the AJAX crawling scheme?
The Lumar team does not have any plans to deprecate this feature. For any updates please follow our blog.
What should I do if Lumar is not crawling our AJAX website?
If Lumar will not crawl your website, even with AJAX crawling enabled, then we recommend checking the following:
- Ugly URLs are not blocked in the robots.txt
- Ugly URLs are producing a 200 http status code
- Ugly URLs include links to other pages on the website and are navigable
We’d also recommend reading our debugging blocked crawls and crawling issue guides.
AJAX crawling feedback
If you have any further questions about AJAX crawling then please get in touch.



