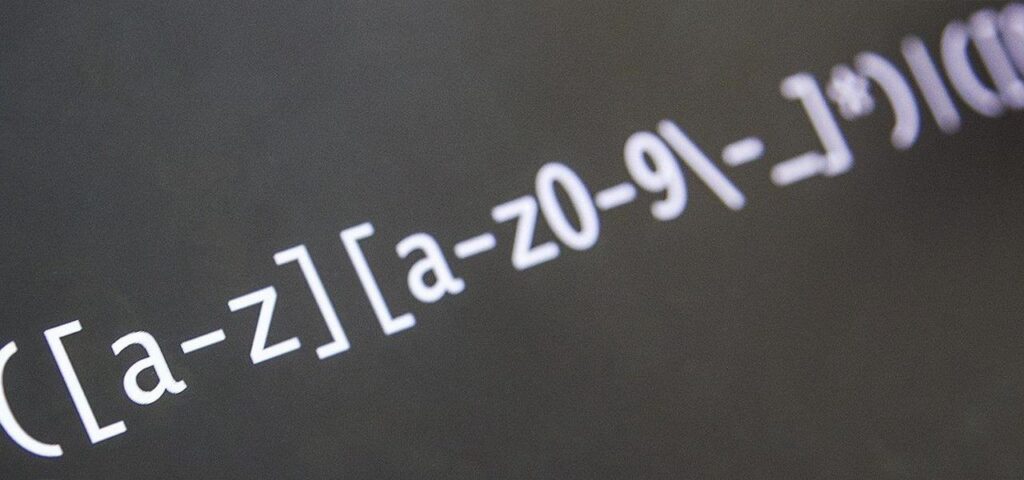

Many of Lumar’s features are centred around identifying and monitoring issues with site architecture. But the tool can also be used creatively to improve user experience, gather data about the structure of your site, and even make non-technical tasks such as seeking out text on your site easier and more reliable.
Often, these approaches will be dictated by the industry or site you are working on, or by your own strategic goals. We thought we’d share four examples of how using regular expressions within Lumar can provide you with valuable data to make your life easier.
What is regex?
“Regex”, or “regular expression” is a series of characters that describe a search pattern. When used in conjunction with Lumar, it allows you to pull only a certain type of data from a site. The way you write the regex allows you to decide exactly what information you receive.
There are a number of standard custom extractions you can use, but if you’re interested in learning more, we recommend https://regexr.com/ or https://rubular.com/, where you can see examples, test queries and build your knowledge of advanced use of Ruby regular expressions.
1. Track down thin content
Imagine you are responsible for SEO on an eCommerce site, which has several categories of product, with regular new additions. You’re especially interested in the number of products in each category, and on each each individual category page.
You know that sections without many products will produce “thin content” pages – pages that search engines use as a negative ranking signal, meaning your site will be lower down in the results if someone searches for it.
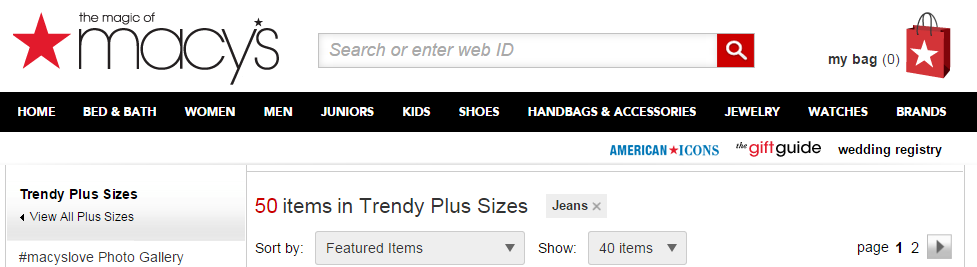
In the case of Macys.com, the navigation bar links to a page for ‘Trendy Plus Size Jeans’:
Along with a link to the ‘FitBit’ brand page:
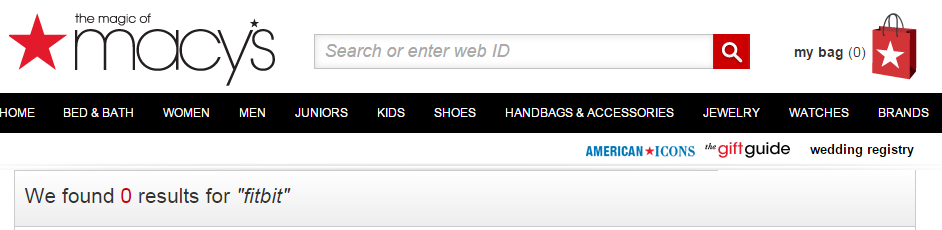
You want to discover which pages are consistently showing a low number of results. In this instance, the “FitBit” page is returning no results at all.
You know that discovering these thin pages will allow you to make decisions about whether they would better fit into another category. This would let you prune unnecessary pages, leading to a better ranking in the search results.
Additionally, the more thin pages without content, the more likely users are to suddenly leave the site. A higher bounce rate will also contribute to a negative ranking signal.
You decide to use an extraction setting to pull out the HTML data that provides the number of results returned. On this site, you could use:
Here (.*?) is used to return the ‘product count’.
In the first example, this now returns ‘50’, and for the second example it returns ‘0’.
Your tactic reveals a number of categories lacking good content. You can then work alongside the development team to reduce these categories, leading to a lower bounce rate and a higher ranking in the SERPs.
As with most regular expressions, this is not for standard use across all sites, and would need to be customized.
2. Spot useful data about your products
In some cases, you may wish to pull out very specific pieces of information about a particular product (or set of products), not just the categories they fall into.
For instance, data about the price of items shown on your site, or a quality such as size or colour could be useful. In some cases, you could even use the Custom Extraction feature to pull out information on which products are showing as out of stock.
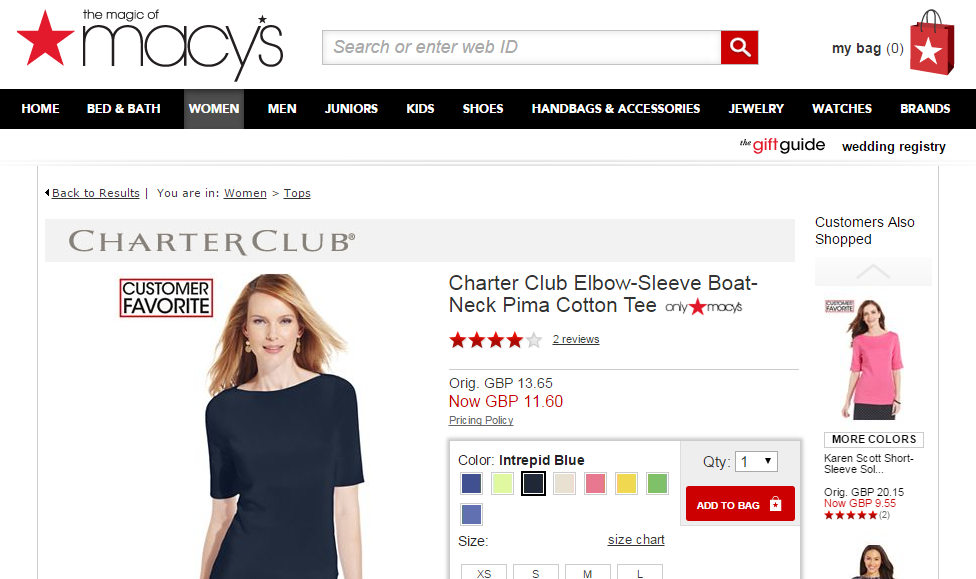
Let’s say you are interested in spotting trends in the pricing of women’s tops on your site. There has been a recent sale, and several items have been reduced.
You decide to use a regex similar to the following:
This returns the current sale price of GBP 11.60. You can then combines this with the regex:
To discover the original cost of the item – in this case, GBP 13.65.
By running both regexes across your product pages, you are able to see which ones had a sale price attached, and which ones are still at the original cost. You now have access to useful data that can inform your pricing strategy.
3. Analyze multiple pieces of data on a single page
Let’s say you want to look at multiple pieces of data on one page – for instance, where there is more than one occurrence of an item (such as ALT tags for images, or data on videos).
Using a custom extraction regex, you could pull out images missing the ALT tag by using something like the following:
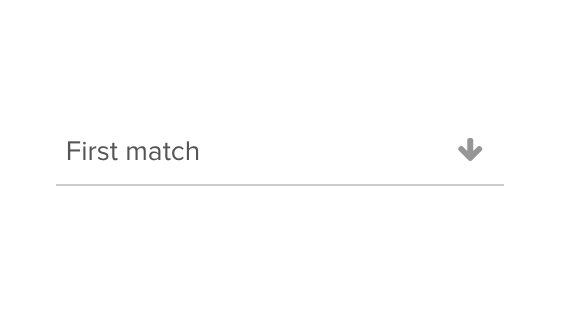
Using the ‘Matches’ dropdown you can select up to how many images with missing alt tags you would like to extract per page. The maximum is 20 extractions or matches per page.
4. Scan your site for words or phrases
You may wish to look through the content for instances of a certain word or phrase being used.
Let’s say you are the copy editor for a start-up. It’s your job to ensure that a consistent tone of voice is used through all channels of communication. You find it time consuming to constantly check the site manually.
The brand tone of voice dictates that clients are never referred to as “customers.” You decide to use regex to track down all uses of the term on your site, so that you can easily remove them. You write the extraction regex:
(customers)
Here, if you were to search for any page where this word appears, you wouldn’t need to search for multiple pieces of data, as it appears at least once.
However, if you were looking for pages where this appears at least two or three times, you could simply add this to the regex:
(customers)
Your use of a regex command now allows you to rapidly track down breaches in the brand’s tone of voice, saving valuable hours at work.
Thanks for reading – we hope this guide has been useful, and has given you some ideas for potential extractions that could be performed on your site. For more help with writing regex and using the Custom Extraction feature you can read our guides on learning regex and getting the most of Lumar with custom extractions.



