
Lumar can be used to monitor XML Sitemaps by using the crawl schedule and task management features.
This technique allows users to:
- Schedule crawl projects to monitor multiple XML Sitemaps.
- Create prioritised tasks in the task management system in Lumar.
- Get prioritised tasks emailed straight to a user’s inbox.
- Monitor Sitemaps without logging into the Lumar app.
Please read how to set up Sitemap audits for further information on the advantages and disadvantages of different Sitemap crawl projects.
Create a Separate Project
Create a new project and use the primary domain whose XML Sitemaps you want to monitor. For example:
Primary Domain: https://www.deepcrawl.com/
XML Sitemaps to monitor:
- https://www.deepcrawl.com/
- https://www.deepcrawl.com/sitemap_index.xml
- https://www.deepcrawl.com/post_sitemap.xml
- https://www.deepcrawl.com/page_sitemap.xml
If pages in the Sitemaps use JavaScript to load links, metadata and content then we recommend selecting Enable Javascript rendering.
In the Sources settings only include the Sitemaps data source.
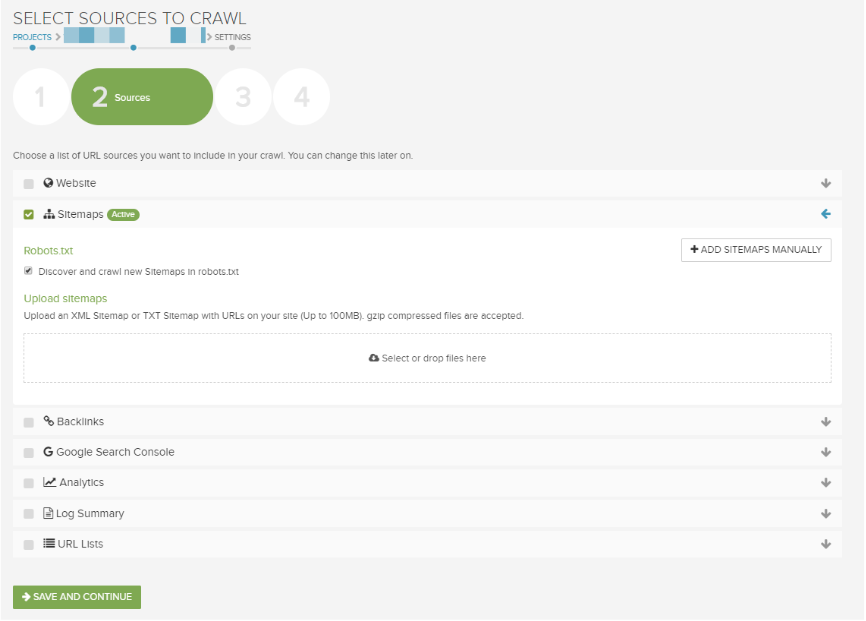
Then add the XML Sitemap(s) using the three available options:
- XML Sitemaps referenced in the /robots.txt file (this is done by default).
- Manually copy and paste XML Sitemap URLs into Lumar.
- Manually upload .xml or .txt files into Lumar.
Choosing which option to include XML Sitemaps in your crawl entirely depends on your technical set up. Our guide on how to add XML Sitemaps to your project provides further information on how to use each option.
Once the XML Sitemaps are added using the chosen option, configure the Crawl Limits and Advanced settings in the next steps.
Once all the settings are all configured it is time to run a test crawl.
Running a Test Crawl
Running a test crawl is essential because it helps identify any configuration issues or problems in the crawl project.
At the moment Lumar does not show the HTTP status codes or URLs it is crawling. This can be an issue if the crawler is finding 4xx or 5xx error codes and not actual pages that need to be crawled.
Once the settings of a crawl project have been configured, it is time to hit the Save & Crawl.
Wait for the test crawl to run and finalise. How long it takes to crawl the Sitemaps depends on how many were added.
Results of the Crawl
Once the crawl has finalised, it is time to check if there are any errors. Use the following reports to check for 4xx or 5xx status codes:
A large number of 5xx errors then this could indicate that the website’s server cannot handle the number of requests from Lumar. If this is the case, then you may want to consider updating the Crawl Limit settings in the crawl project and discussing when the best time to crawl the website with your WebOps team.
As well as checking for URL errors, you can use Lumar to identify if the XML Sitemaps added are valid. This will help understand if the Sitemap SEO metrics being reported on in Lumar is accurate.
Read our guide on how to check if Sitemaps are valid for further information.
Identify Issues With XML Sitemaps
If there are no issues with the XML Sitemap crawl project, then the next step is to audit your Sitemaps and create tasks for any problems.
Read our guide on how to audit XML Sitemaps using Lumar to identify potential issues with any XML Sitemaps added to the crawl project.
The most common reports in Lumar which can show issues in XML Sitemaps are:
| Report | Contents |
|---|---|
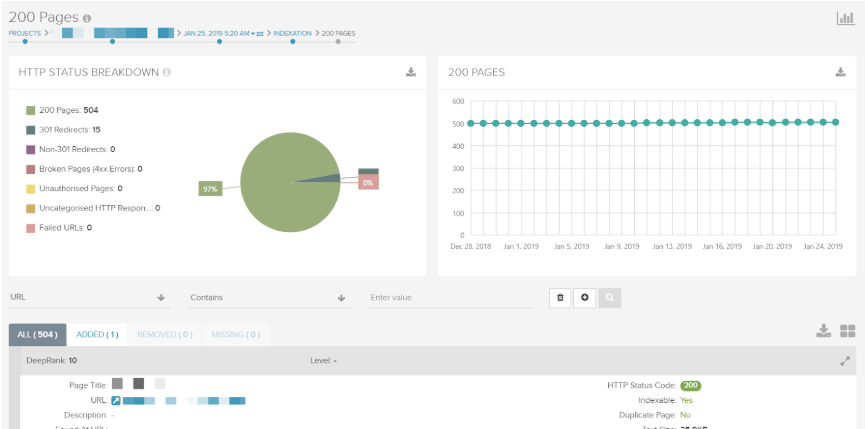
| 200 pages | URLs which return a 2xx status code. |
| XML Sitemaps | Sitemap URLs discovered and crawled by Lumar. |
| Broken Sitemap Links | URLs in Sitemap which return a 4xx or 5xx HTTP status code. |
| All Redirects | URLs which return a 3xx HTTP status code or have a meta refresh tag. |
| Canonicalized and Noindexed Pages | URLs which have a noindex tag (meta robots or X-robots) or a canonical tag which references another page. |
| Disallowed/Malformed URLs in Sitemaps | URLs in a Sitemap which are disallowed in the /robots.txt file or are malformed. |
| Broken/Disallowed Sitemaps | XML Sitemap URLs which returned a 4xx HTTP status code or were blocked in the robots.txt file. |
The reports in the table above are just the most common reports used, and we encourage users to use reports which are useful to uncover unique XML Sitemap issues on their website. For example:
- URLs with duplicate content
- URLs with thin content included in XML Sitemaps
- URLs with empty body content
Create Tasks to Monitor Sitemap Issues
As each issue is identified, you can begin creating tasks in the Lumar task management system.
When a task is created in the task management system, it is allocated to a report URL in Lumar. Creating tasks will help users monitor specific issues within the XML Sitemap crawl project, which can then be emailed straight to your inbox.
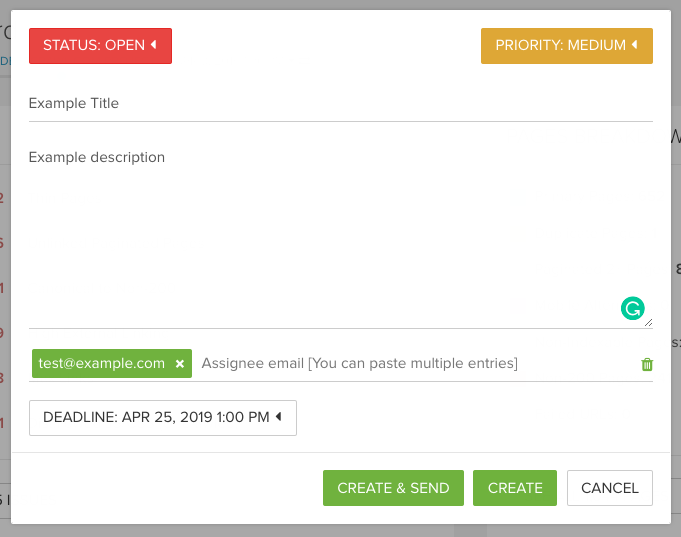
When an issue is identified, create a task by clicking on the Task Manager icon in the top right and click on the Create a Task in the drop down and then:
- Add a title and description to the task.
- Add an email address where you want the tasks emailed.
- Set a priority based on your business and digital strategy goals.
- Once all the issues and tasks have been added, you need to schedule your crawl project.
- Set a deadline if applicable.
- Hit create.
Schedule Crawl Project
Now to schedule the crawl project so it will run on a schedule. Go to advanced settings in the crawl project → Schedule crawl option.
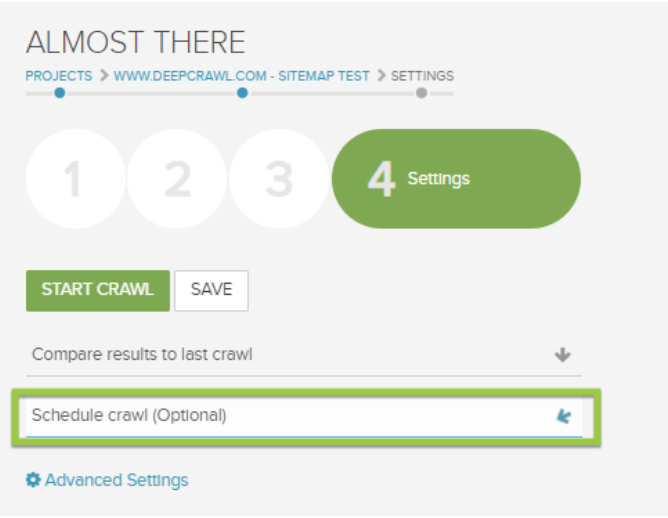
Select the time when the crawl will start and on what schedule you want the crawl to run. The schedule options include:
- Hourly
- Daily
- Weekly
- Fortnightly
- Monthly
- Quarterly
Use the schedule option which will help monitor changes alongside website updates.
For example, if your web development team have fortnightly sprints to push changes to the live website, then select the fortnightly option.
Then select a date and time for the crawl to start (e.g. 30/01/2019 at 04:00 am).
We’d then recommend setting the time of the crawl to just after any technical sprint. If it is set before then, you will miss changes or issues made to the XML Sitemaps.
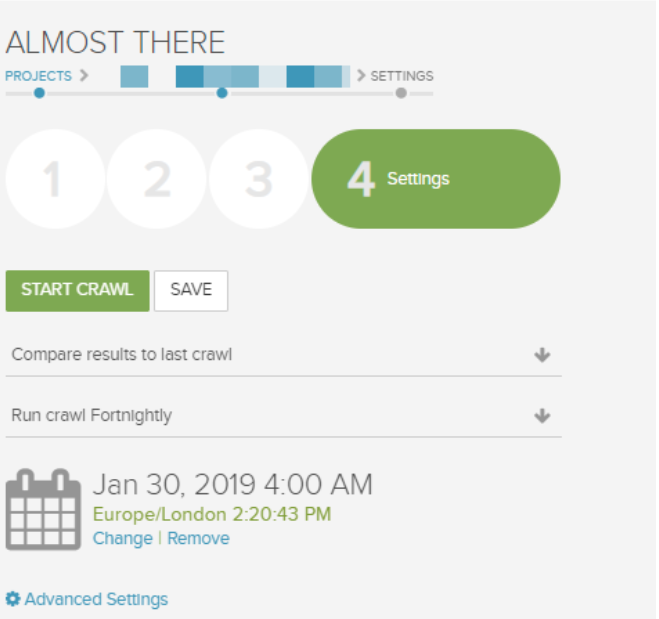
The crawl will run the schedule from this date. For example, the next crawl will run on the 13/02/2019 at 04:00 am. The time zone will be shown in the settings.
If you wish to change the time zone, this can be done in the Account settings → Timezone.
That’s it! The monitoring crawl project for Sitemaps is set up.
Monitor Sitemaps From Your Inbox
Once the crawl project is scheduled to wait until the next crawl, once it is finalised, Lumar will send you an email with all the tasks which you created in the app.
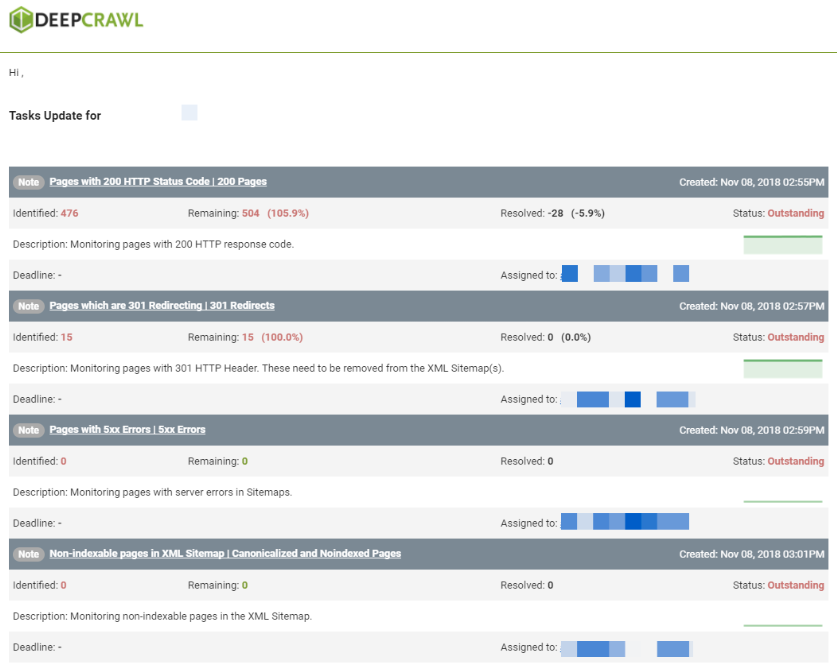
This email details all the tasks which are in the tasks tab. It highlights:
- Identified: Pages first identified when the task was created
- Remaining: All the pages found in the last crawl in the report
- Resolved: Number of pages no longer in the report
- Date task created: When the task was first created
- Title of task: Title inputted by the user
- Description of task: Description inputted by the user
- Emails: Emails added to tasks (who will receive this email)
- Priority: The priority of the task submitted by the user
These reports will be emailed to you every time Lumar runs a crawl for the project.
If you notice an increase in the pages Remaining, or want to visit the report in Lumar, click on the task title.
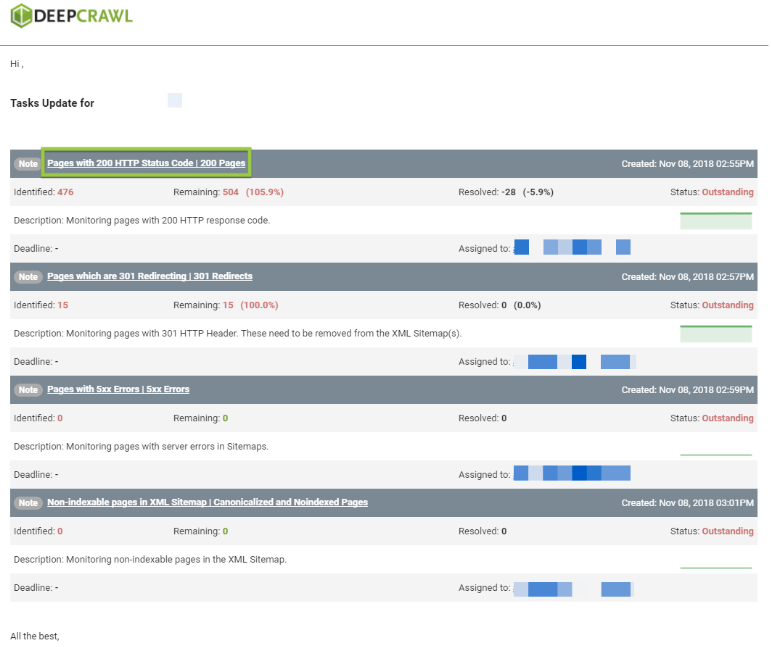
Clicking on the task title will send you directly to the report in Lumar.
Summary
This technique can be used to monitor and schedule Sitemaps depending on your or your team’s requirements. Using this technique allows users to:
- Schedule crawl projects to monitor multiple XML Sitemaps.
- Create prioritised tasks in the task management system in Lumar.
- Get prioritised tasks emailed straight to a user’s inbox.
- Monitor Sitemaps without logging into the Lumar app.



