

A valid XML Sitemap file or Sitemap Index can be added to a crawl project. However, it is important to understand what type of data you want to include in any XML Sitemap audit.
There are three ways that XML Sitemaps can be audited in Lumar:
- A crawl project with all data sources enabled.
- A crawl project with web and XML data sources enabled.
- A crawl project with only the XML data source enabled.
Each of these crawl projects has advantages and disadvantages depending on what you want to achieve.
Before setting up a crawl project, it is important that any Sitemaps included in a crawl are tested to make sure they are valid.
Test XML Sitemap Files
An invalid Sitemap will provide inaccurate crawl data and will mean that the crawl will need to re-run.
To avoid any inaccurate crawl data our team recommends:
- Running a separate test crawl project which only includes the XML Sitemap files
- Following the instructions in the how to check XML Sitemaps are valid guide.
Once you are confident the XML Sitemaps are valid, then you can choose to include them in a crawl project which meets your audit objectives.
Choose Your Crawl Project When Auditing XML Sitemaps
It is essential to understand the differences between the different crawl projects to make sure data from Lumar achieves your intended goal.
Here is a chart to compare the three different types of crawl project:
| Crawl Project | Validate XML Files | Use traffic and backlink data in Sitemap analysis | Use internal link data in analysis | Audit URLs in XML Sitemaps? | Run crawl quickly |
|---|---|---|---|---|---|
| All Data |  |
|
|
|
 |
| Web and XML Sitemap | |
|
|
|
|
| XML Sitemap | |
|
|
|
|
For each crawl project, we have provided further detail about the disadvantages and advantages of using them.
All Data Sources Crawl Project
In this crawl project type, all the data sources are selected.
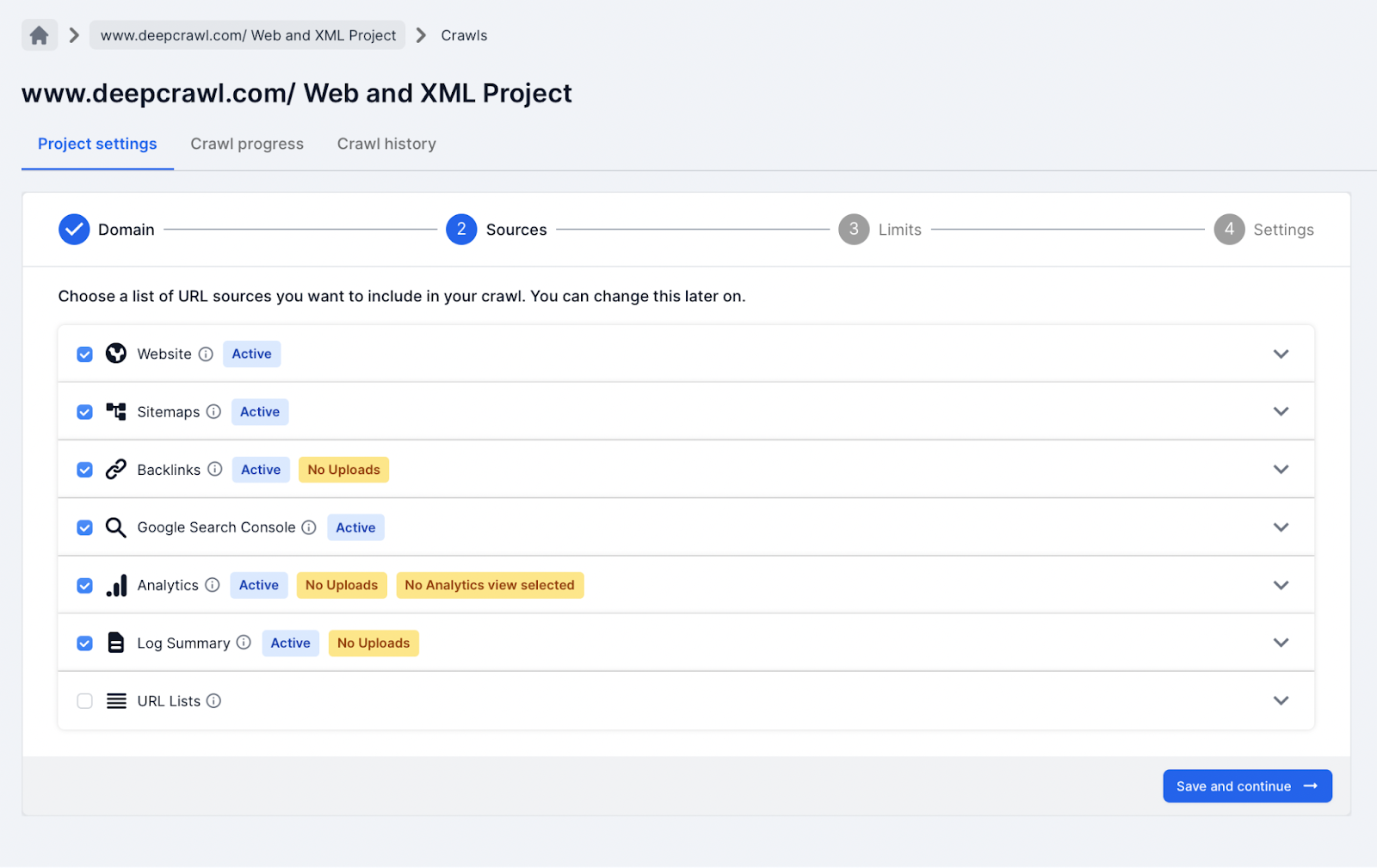
This helps to understand better the URLs found within the XML Sitemap files in the context of other data sources (Google Search Console, backlinks, etc.).
Advantages:
- This crawl project type provides in-depth URL data which can be used to understand backlink, traffic and internal link signals of the URLs included in the XML Sitemaps.
- It can help understand whether URLs in the XML Sitemap are either found in the internal link structure of a site or were not found in the web crawl (orphaned pages).
- Including the backlink, Google Analytics, and Search Console Performance data allows for further understanding of the important or unimportant URLs in the XML Sitemaps.
Disadvantages:
- This crawl project type takes longer to crawl and process all the link data from each source.
When Should This Project Type be Used?
A crawl project with all data sources selected is best to be scheduled to be run every month or quarter. This is because a crawl with all data sources selected would take more time to crawl due to the extra data sources which Lumar needs to request and process.
Data Sources Should Use the Same Primary Domain Name
When connecting all data sources within the crawl set up, please make sure they are all using the same primary domain as the XML Sitemap and web crawl (example.com, www.example.com, etc.).
If the primary domains are different in the backlink and analytics data sources, then any XML Sitemap analysis will be invalid in Lumar. This is because all impression, click, and backlink metrics associated with a URL will not match up to the URLs found in the Sitemaps.
Web Crawl and XML Sitemap Crawl Project
In this crawl project type, only the website and XML Sitemap data sources are selected.
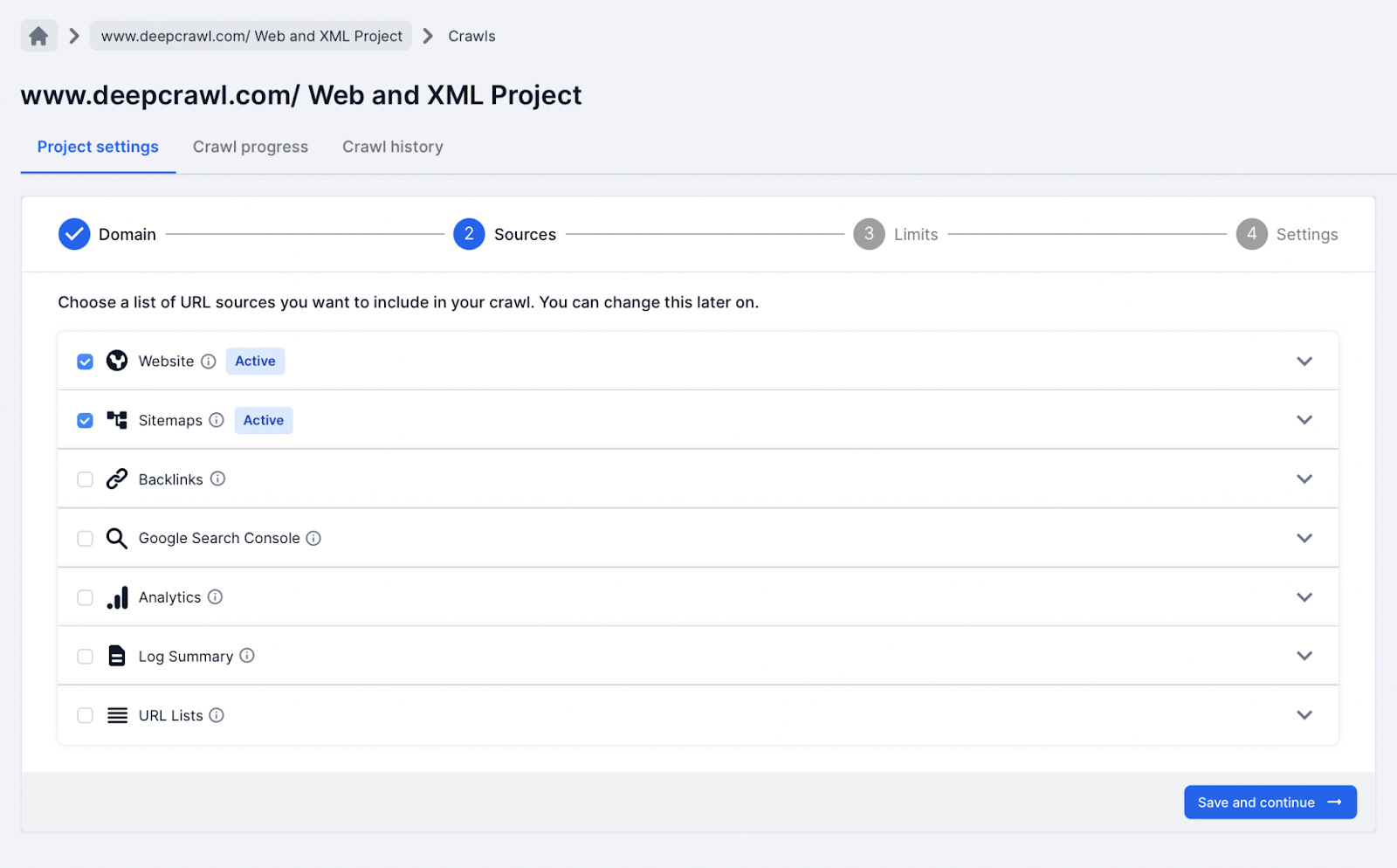
The website and XML Sitemap crawl project helps to better understand the URLs found within the XML Sitemap files in the context of the on-site signals (internal links, orphaned pages, canonicalization, etc.).
Advantages:
- This crawl project type is ideal for understanding the URLs found in XML Sitemaps within the context of the crawled site.
- It can help understand whether URLs in the XML Sitemap are either found in the internal link structure of a site or were not found in the web crawl (orphaned pages).
- Useful to quickly identify canonical signal mismatches across the website (XML Sitemap is a canonical signal).
- This crawl project is faster to run than using a project with all data sources selected.
Disadvantages:
- The crawl project type takes time to crawl and process all the link data from the website.
When Should This Project Type be Used?
A crawl project with all data sources selected is best to be scheduled to be run every month or quarter. This is because a crawl with all data sources selected would take more time to crawl due to the extra data sources which Lumar needs to request and process.
Website Crawl Should Use the Same Primary Domain Name
When choosing both the website crawl data and XML Sitemap data source, make sure both are using the same primary domain.
If the primary domain is different in the website data source then any XML Sitemap analysis will be invalid in Lumar. All on-page metrics associated with a URL will not match up to the URLs found in the Sitemaps.
XML Sitemap Crawl Project
In this crawl project type, only the XML Sitemap data source is selected.
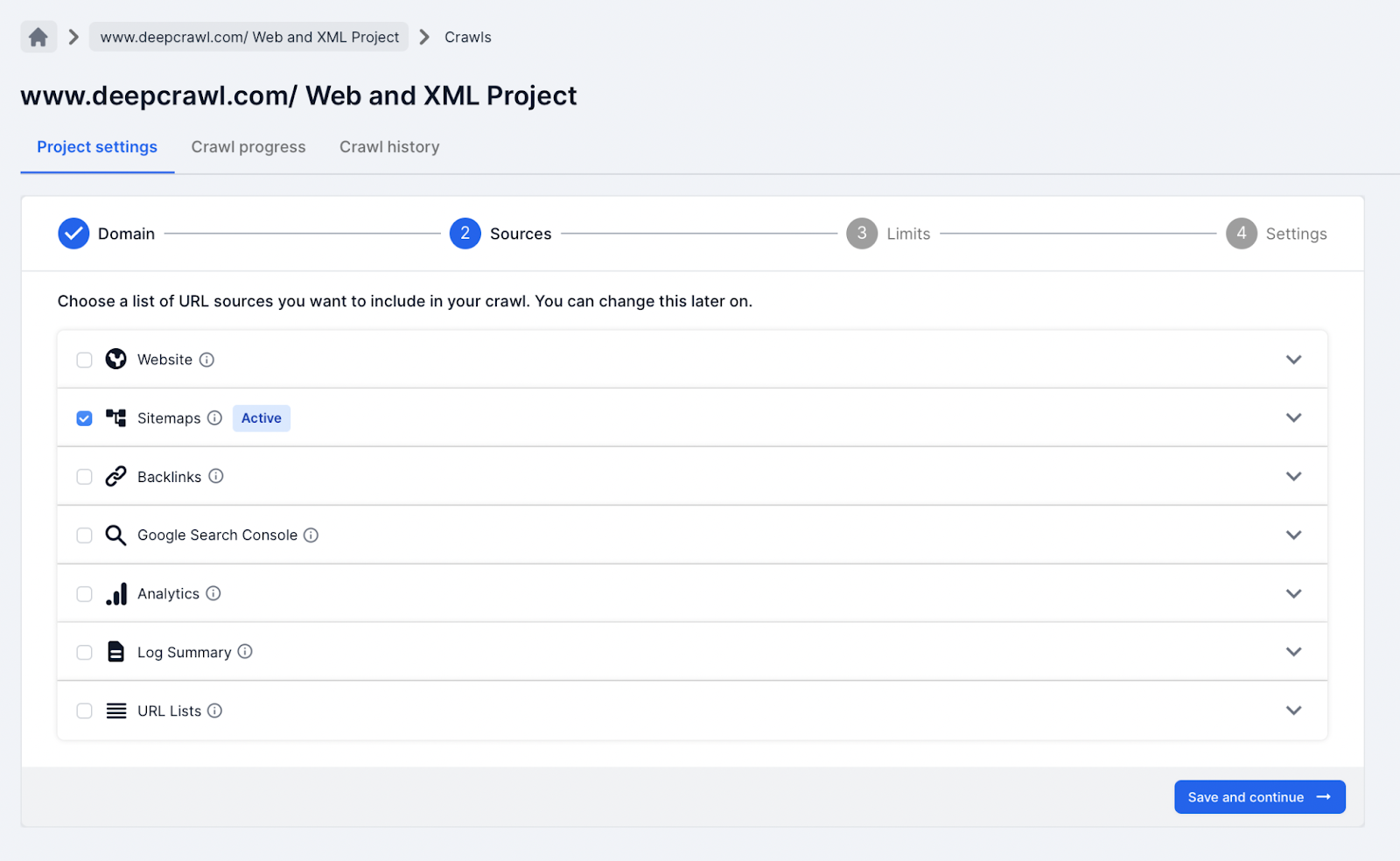
The XML Sitemap crawl project helps to quickly understand any issues with the URLs found in XML Sitemap files (HTTP status codes, noindexed pages, broken links, etc.).
Advantages:
- This crawl project type is ideal for quickly understanding page level metrics of URLs found in the XML Sitemap files.
- Combined with our scheduling feature this crawl project is useful for monitoring technical issues with XML Sitemap files on a daily or weekly basis.
- This crawl project is the fastest to run compared to the other crawl projects.
Disadvantages:
- Not selecting other data sources means the URLs within the XML Sitemap are missing website and analytical context (internal link, external link, canonical signals, etc.).
- Only the URLs found in the XML Sitemap are crawled, Lumar does not crawl any links discovered on the pages.
When Should This Project Type be Used?
The crawl project is ideal for when development or SEO teams want to monitor XML Sitemaps and want to get data back quickly.
Summary
There is no right or wrong way to set up a crawl project for auditing XML Sitemaps. Just remember that when setting up an XML Sitemap project using Lumar to:
- Identify what data you will need for your XML Sitemap audit.
- Test all XML Sitemap(s) are valid.
- Choose a crawl project which meets your auditing needs.
- Make sure all sources are using the same primary domain.
- Run a test crawl to check data is valid.
- Run the full crawl, and if applicable schedule a crawl.



