
Lumar supports manually uploading of a wide range of file types to our crawl sources. This page runs through the valid file types for each source, and where to find them.
Supported crawl sources
The following crawl sources, which can be added in step 2 of a project’s advanced settings, support manually uploading data in Lumar:
A full breakdown of how to manually upload files for each source can be found below.
Sitemaps
A sitemap file can be uploaded to Lumar by dragging and dropping a file (up to 100MB file size).
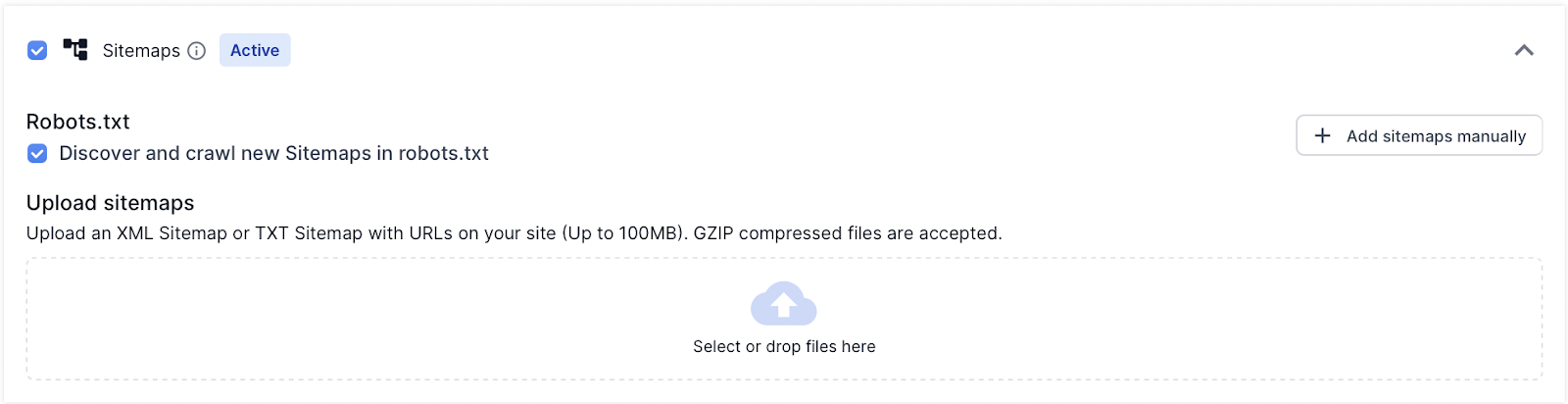
The sitemap source supports the following file types:
- Text files (.txt)
- XML Sitemap files (.xml)
- Gzip compressed sitemap files (.gzip)
Analytics
Our Google Analytics integration allows users to connect their Google Analytics profile to Lumar, which automatically pulls in analytics data. However, there will be certain circumstances when you want to manually upload analytics data from other tools (or from Google Analytics).
A file can be uploaded to Lumar by dragging or dropping it into the Analytics Source (up to 100MB file size).
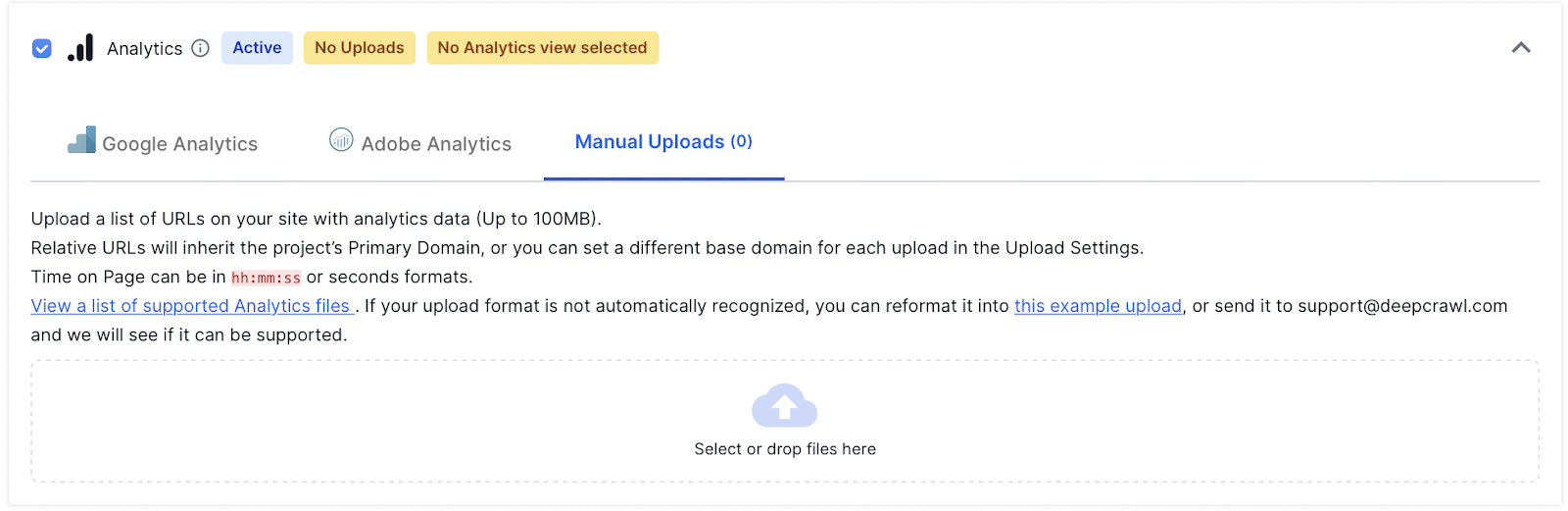
When manually uploading a file please be aware that it needs to follow a specific format for our system to automatically recognise supported metrics.
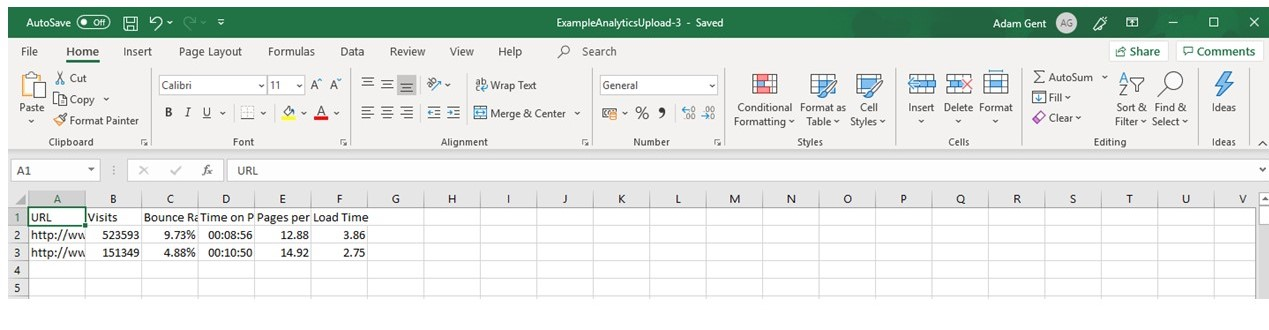
Download an example file with the supported format here.
If an uploaded file is not in the supported format it will not automatically be processed and will prompt the upload settings to appear.
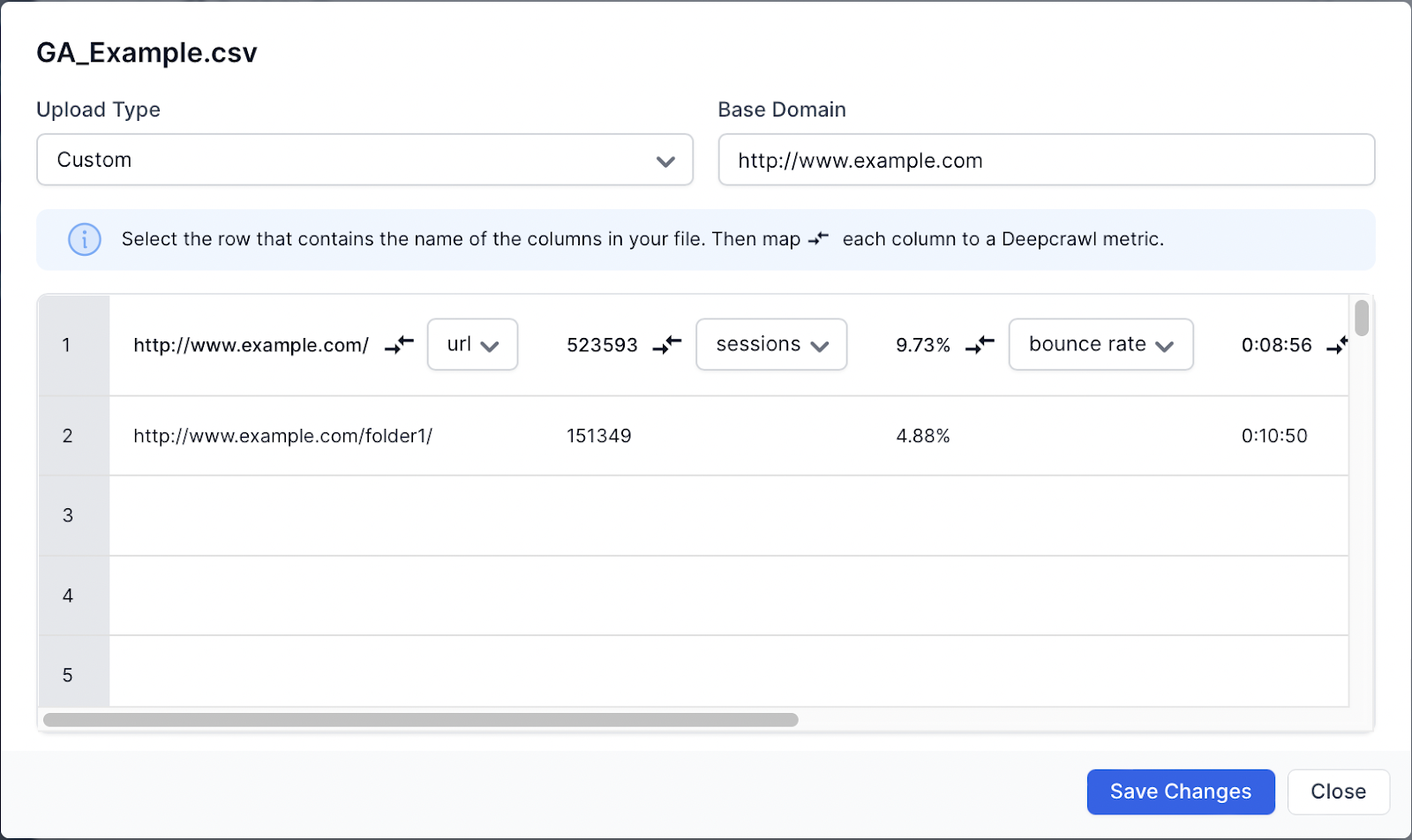
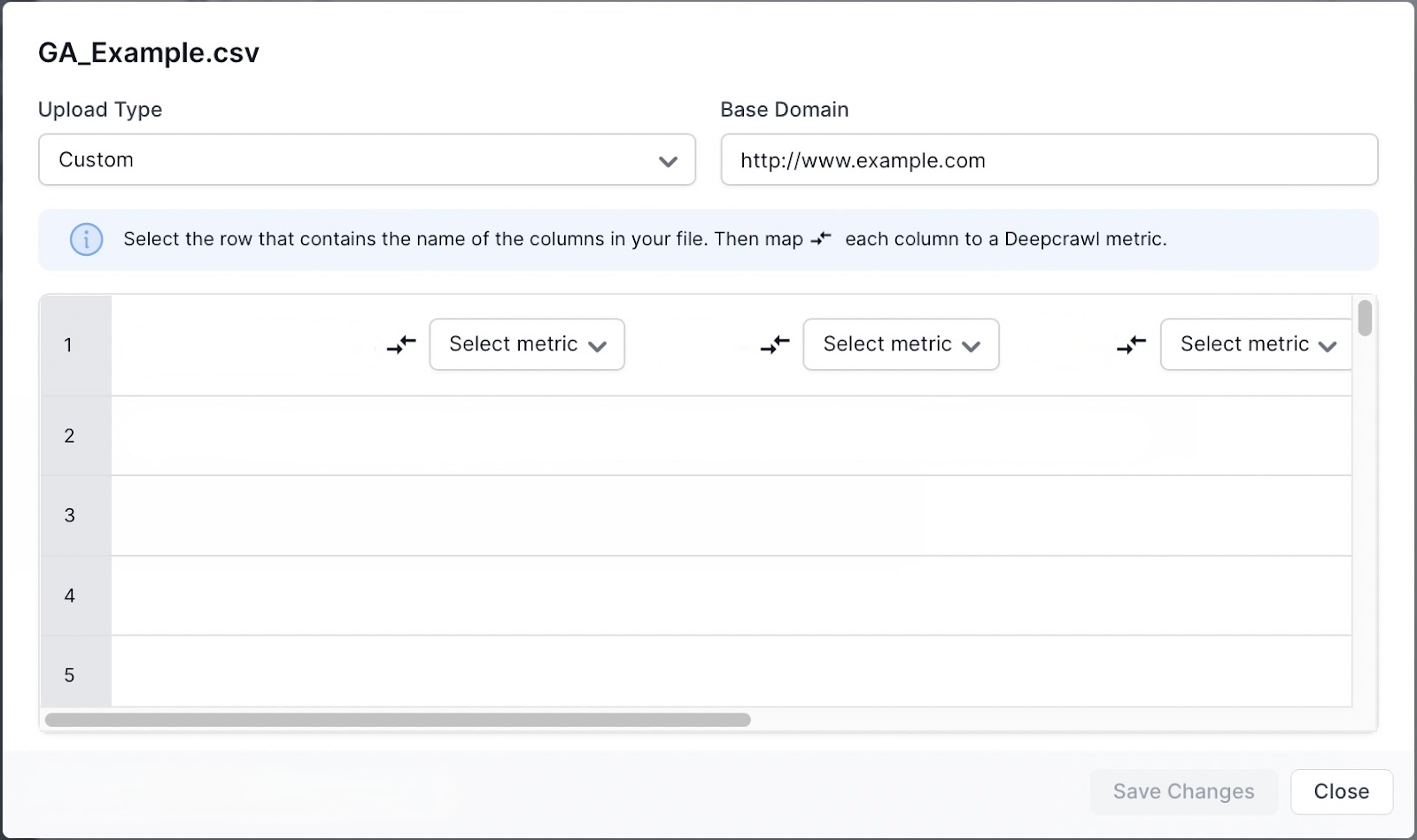
You will need to manually match up the following metrics with the data you have uploaded:
- URL
- Sessions
- Average page load time
- Bounce rate
- Average time on page
- Pageviews per session
By default, any relative URLs in the uploaded file will use the primary domain in the project settings. If you wish to override the primary domain when uploading data, then use the “Base Domain” in the upload settings.

Note: Be aware that if the Base Domain is a subdomain or separate domain and is not included in the secondary domain settings then Lumar will not crawl the landing pages.
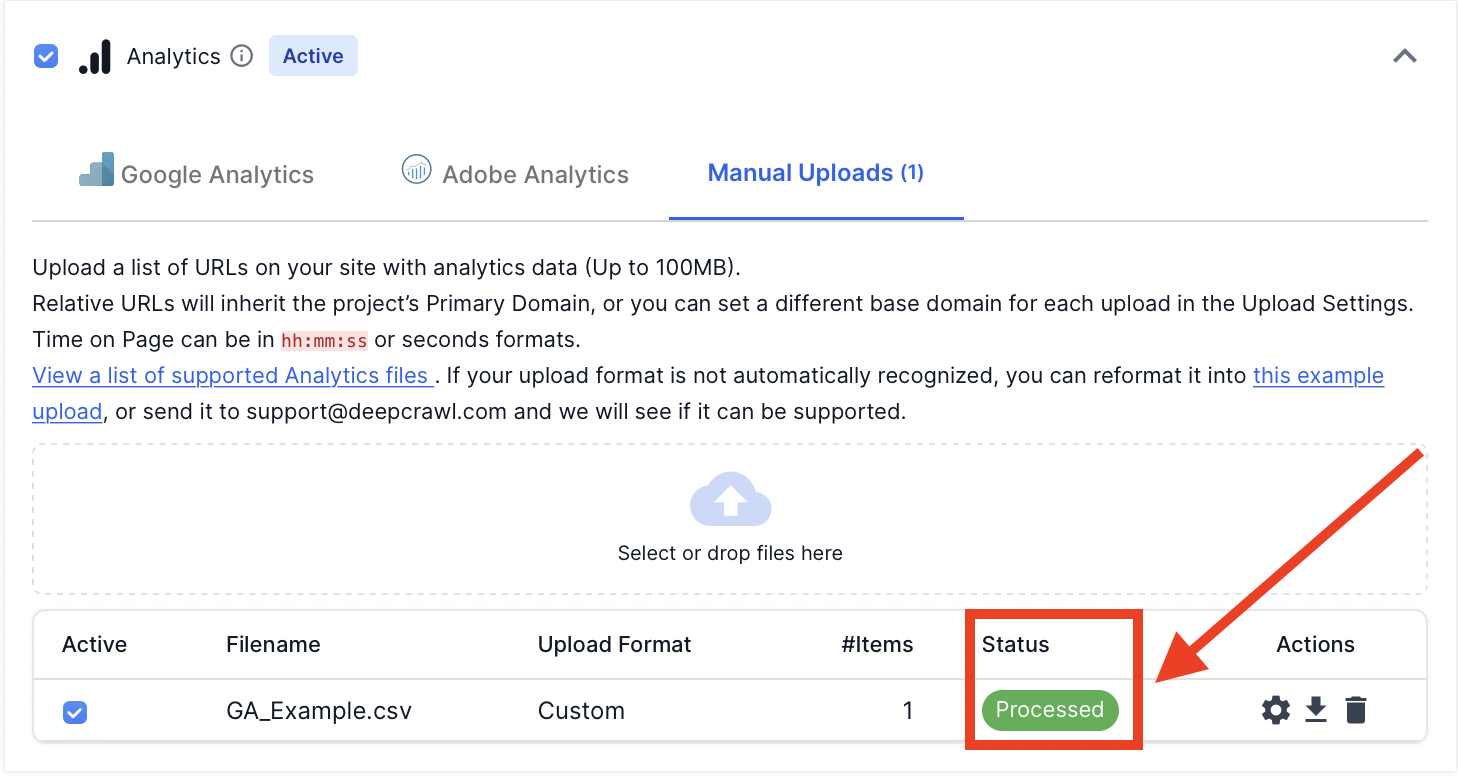
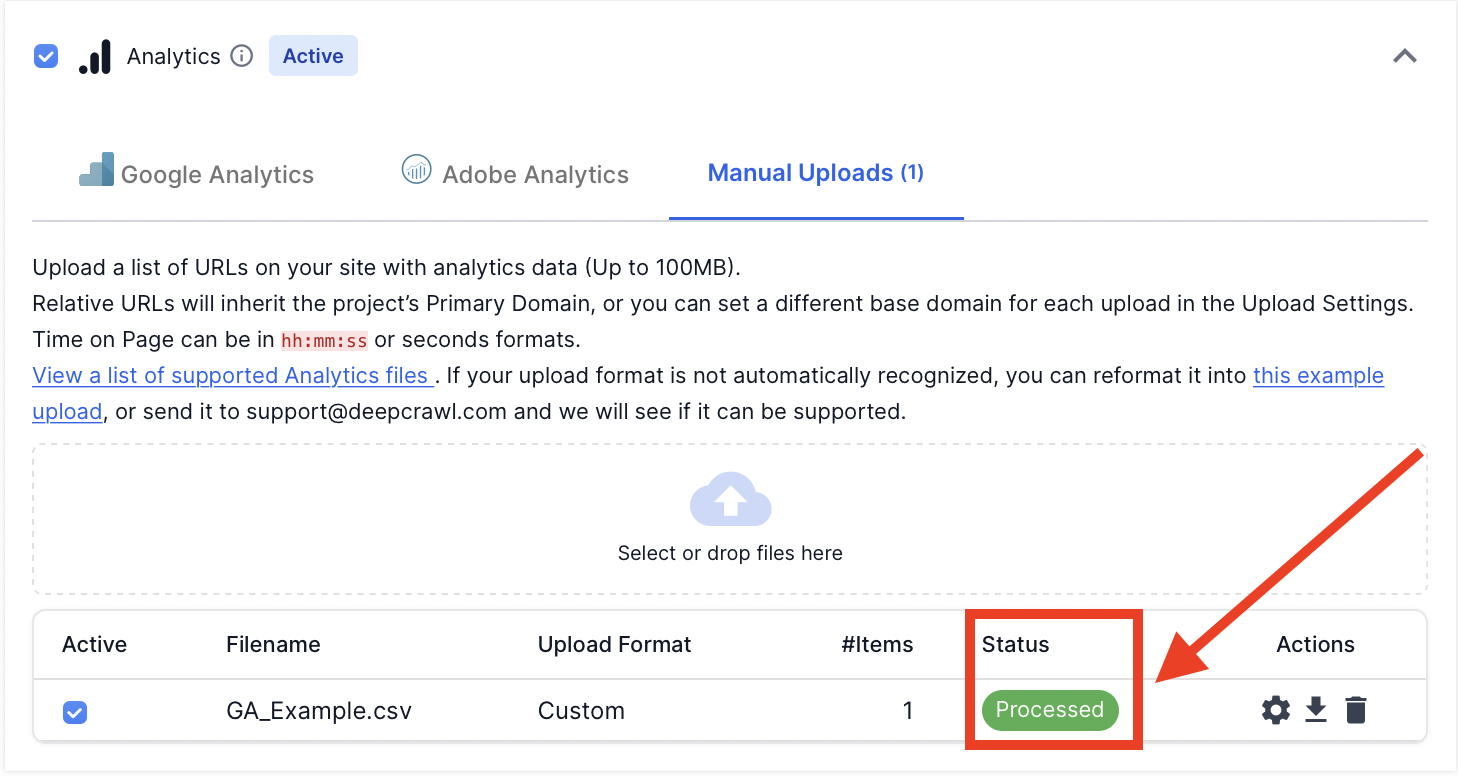
Once you have manually matched the data with the metrics in the upload settings, hit “save changes”. The file will be processed by Lumar and, if supported, will be marked as processed.
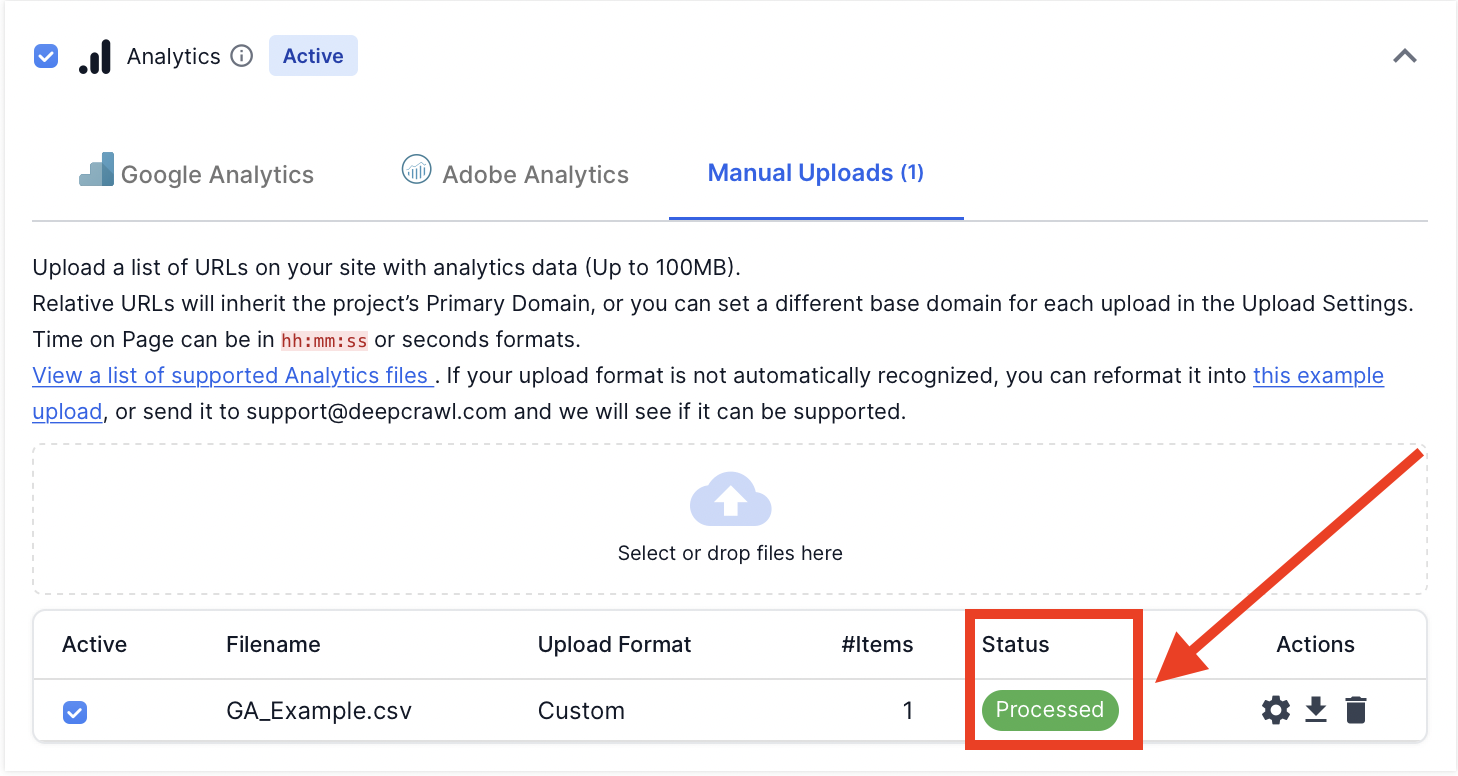
If the 100MB limit per file is not enough, repeat this process for each file uploaded. Once everything is processed you can run a crawl with the analytics crawl source enabled.
Please see below for the steps that need to be taken to upload Google Analytics and AdWords data into Lumar.
Google Analytics
In Google Analytics go to Behaviour > Landing Pages. If you want to upload pages with organic search traffic, then make sure you are using the Organic Traffic segment.
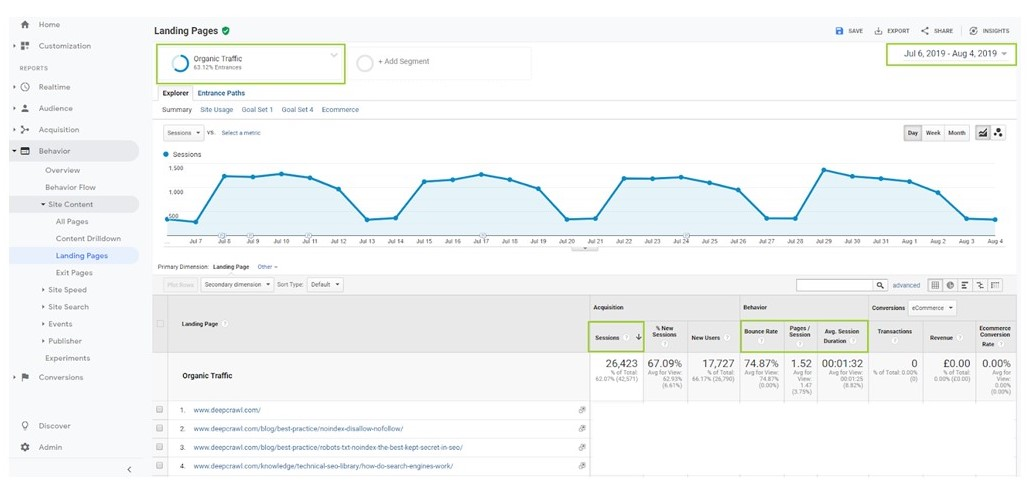
Change the number of rows to 5000 to obtain the maximum number of rows on a single page.

Note: If you have a lot of URLs then you will need to download multiple pages from Google Analytics.
Export the data in a CSV file format.
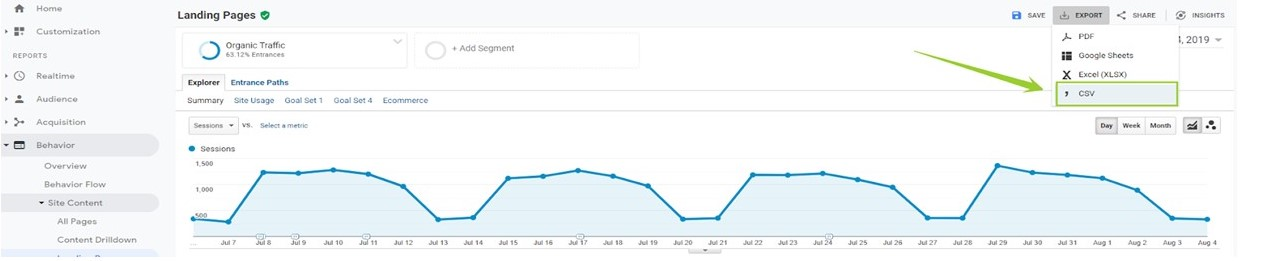
Upload the exported CSV file to Lumar in the Analytics crawl source. When the file is uploaded the Upload Settings will be loaded. As already discussed, you will need to assign columns with supported metrics before submitting.
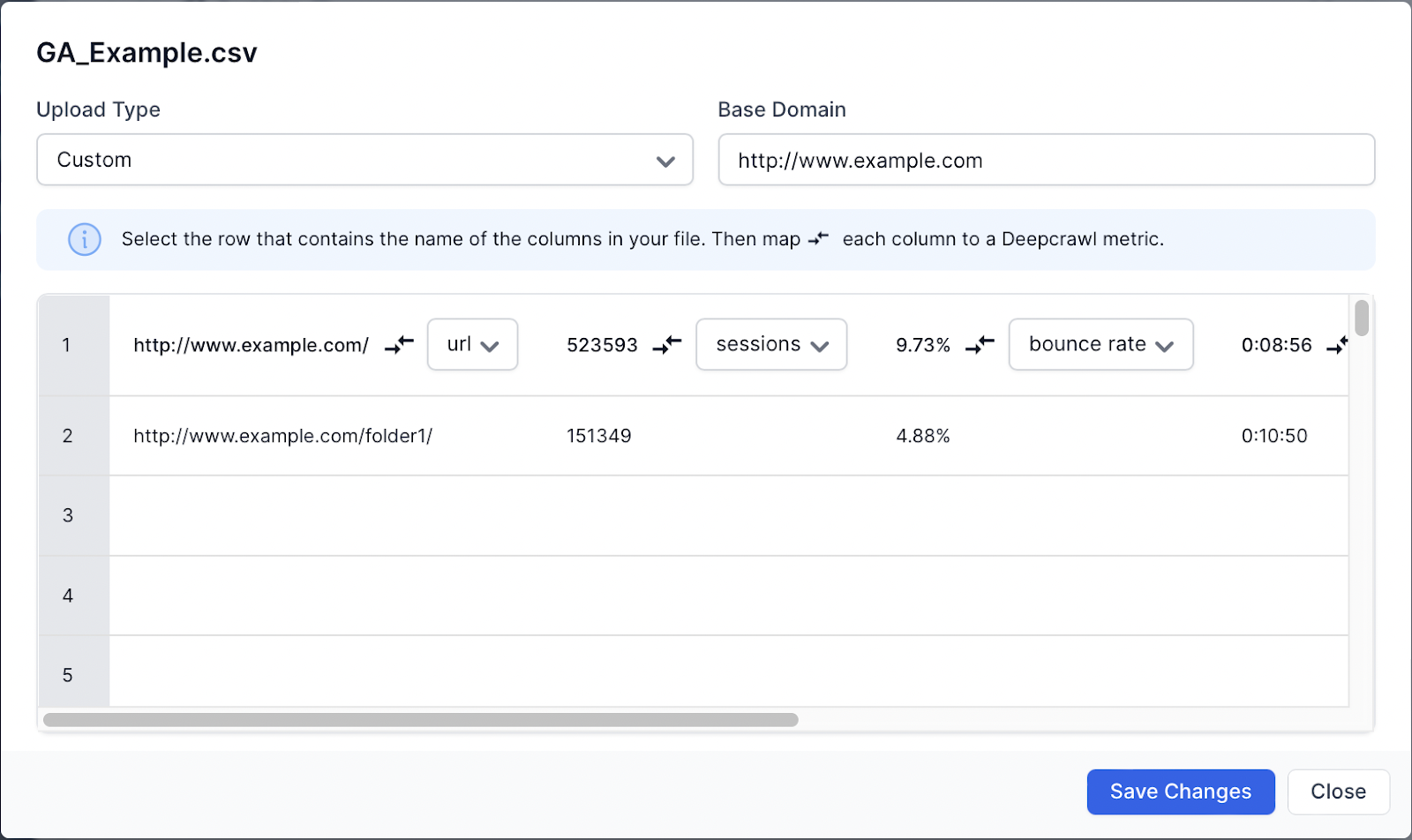
Once the metrics are assigned, click “Save Changes”. If there are no errors, then the Google AdWords file format will be marked as “Processed” in the status.
AdWords
AdWords destination URLs can be imported into Lumar’s Analytics metrics to help you ensure that you are sending users to relevant pages, and that they’re not broken or orphaned.
In Adwords, load the “Reports” screen. Choose “Predefined Reports” > “Basic” > “Final URL”.
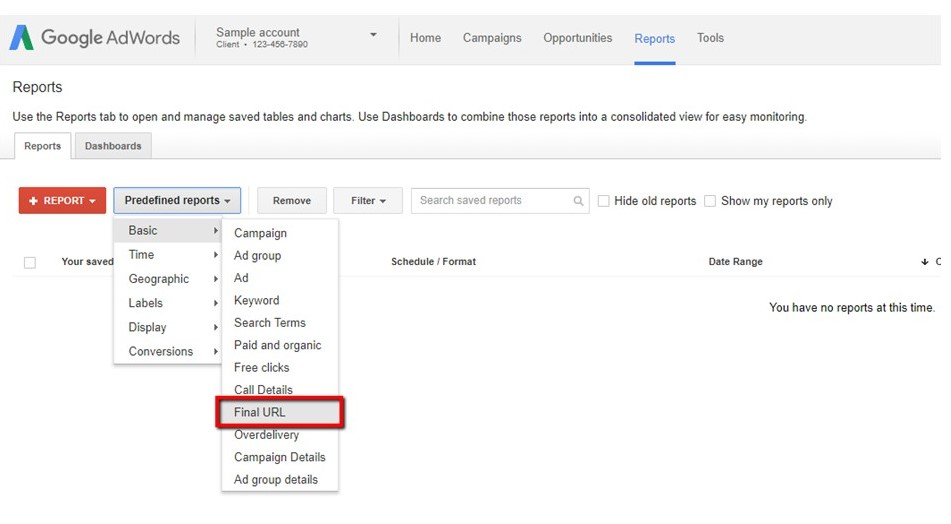
Export the Final URL report as a csv. Open the file, remove the first 2 rows and make sure all metrics are on the top row (as this makes it easier to upload).
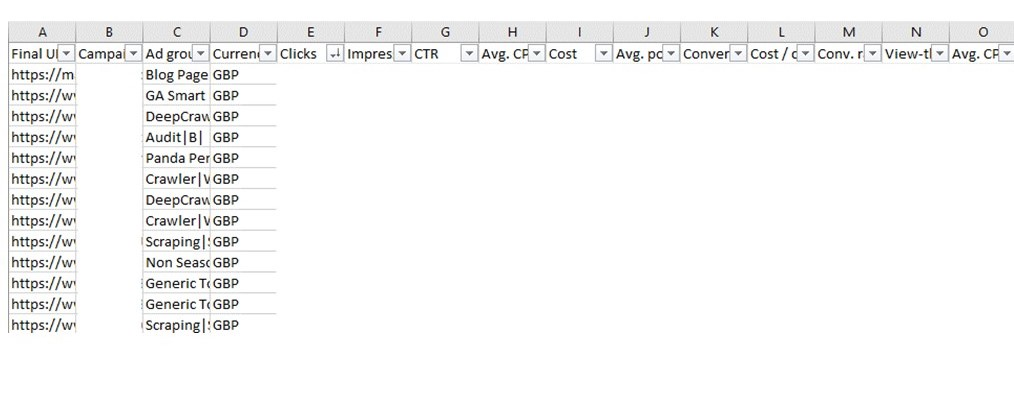
Upload this to Lumar’s Analytics tab in your Project’s settings, once the file is uploaded the Upload Settings will appear. As already discussed, you will need to assign columns with supported metrics before submitting.
Note: Use Clicks as the metric for the Sessions column.
Once the metrics are assigned, click “Save Changes”. If there are no errors, then the Google Analytics file format will be marked as “Processed” in the status.
Backlinks
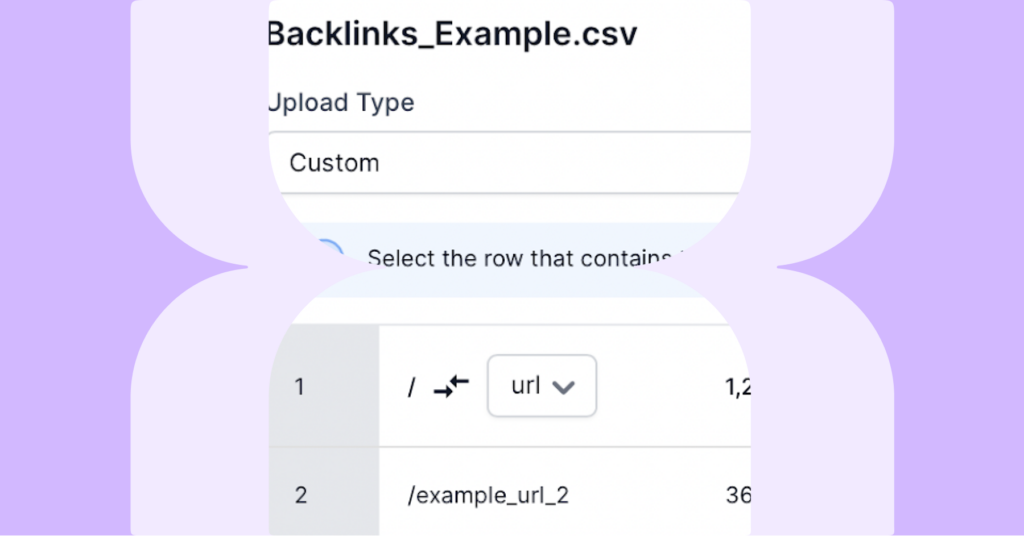
Backlink data can be uploaded to Lumar by dragging and dropping a CSV file (up to 100MB).
When manually uploading a backlink .csv file, be aware that it needs to follow a specific format for our system to automatically recognise metrics to pull into reports.
Download an example file with the supported format here.
If an uploaded file is not in the supported format it will not automatically be processed and will prompt the upload settings to appear.
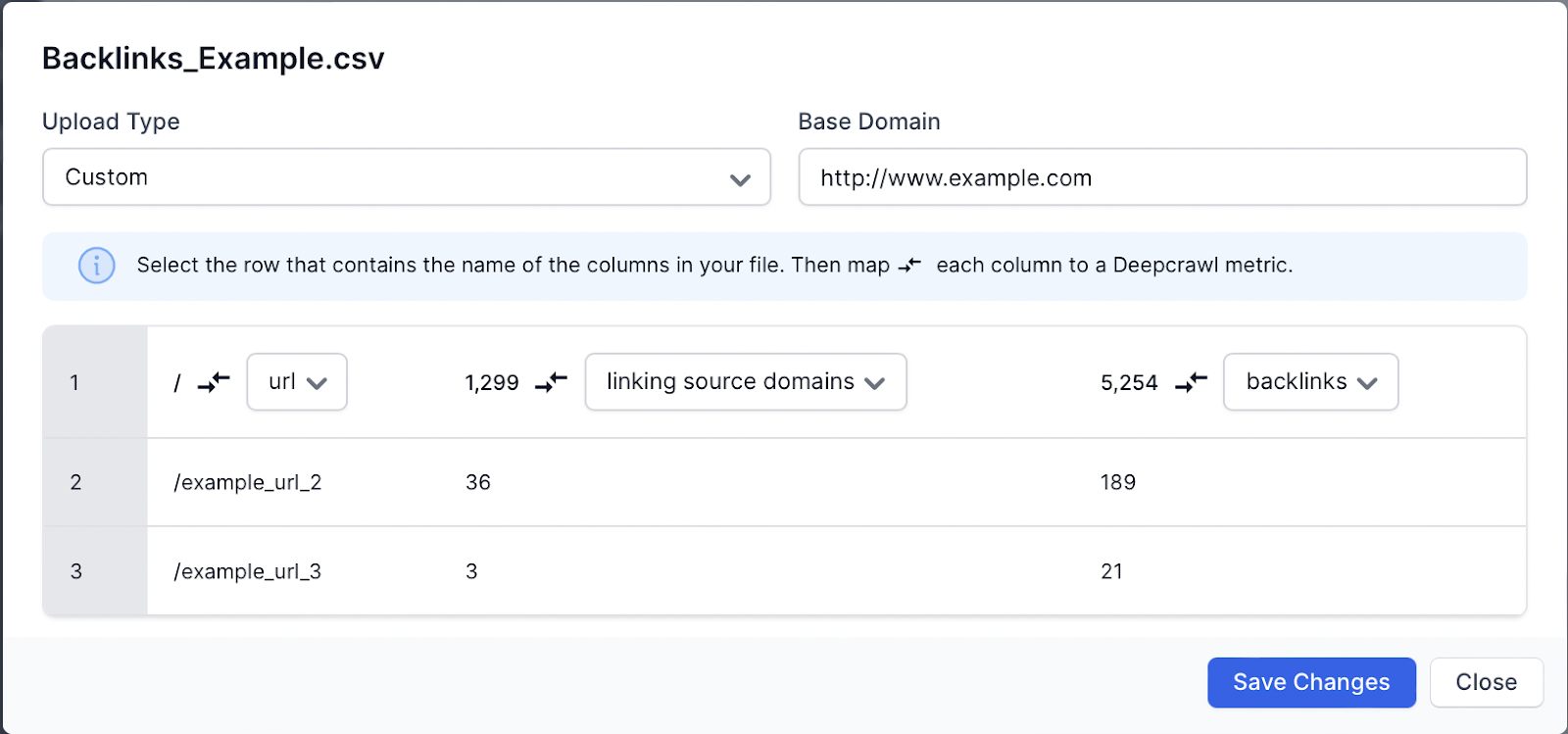
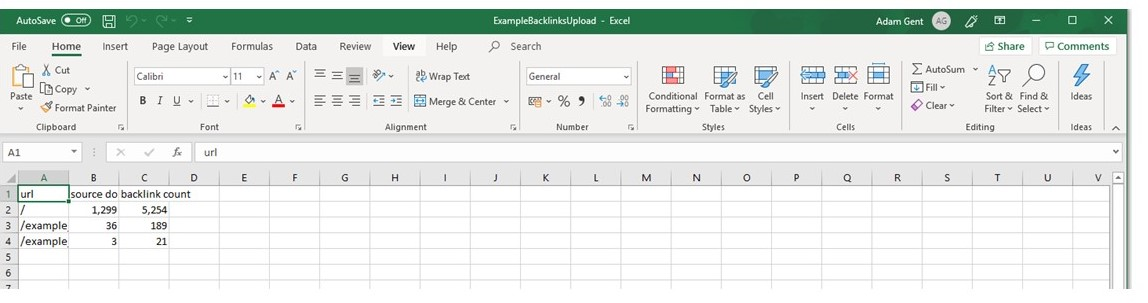
You will need to manually match up the following metrics with the data you have uploaded:
- URL
- Backlink count
- Source domain count
By default, any relative URLs in the uploaded file will use the primary domain in the project settings. If you wish to override the primary domain when uploading data, then use the “Base Domain” in the upload settings.
Note: Be aware that if the Base Domain is a subdomain or separate domain and is not included in the secondary domain settings then Lumar will not crawl the landing pages.
Once you have manually matched the data with the metrics in the upload settings, hit “save changes”. The file will be processed by Lumar and, if supported, will be marked as processed.
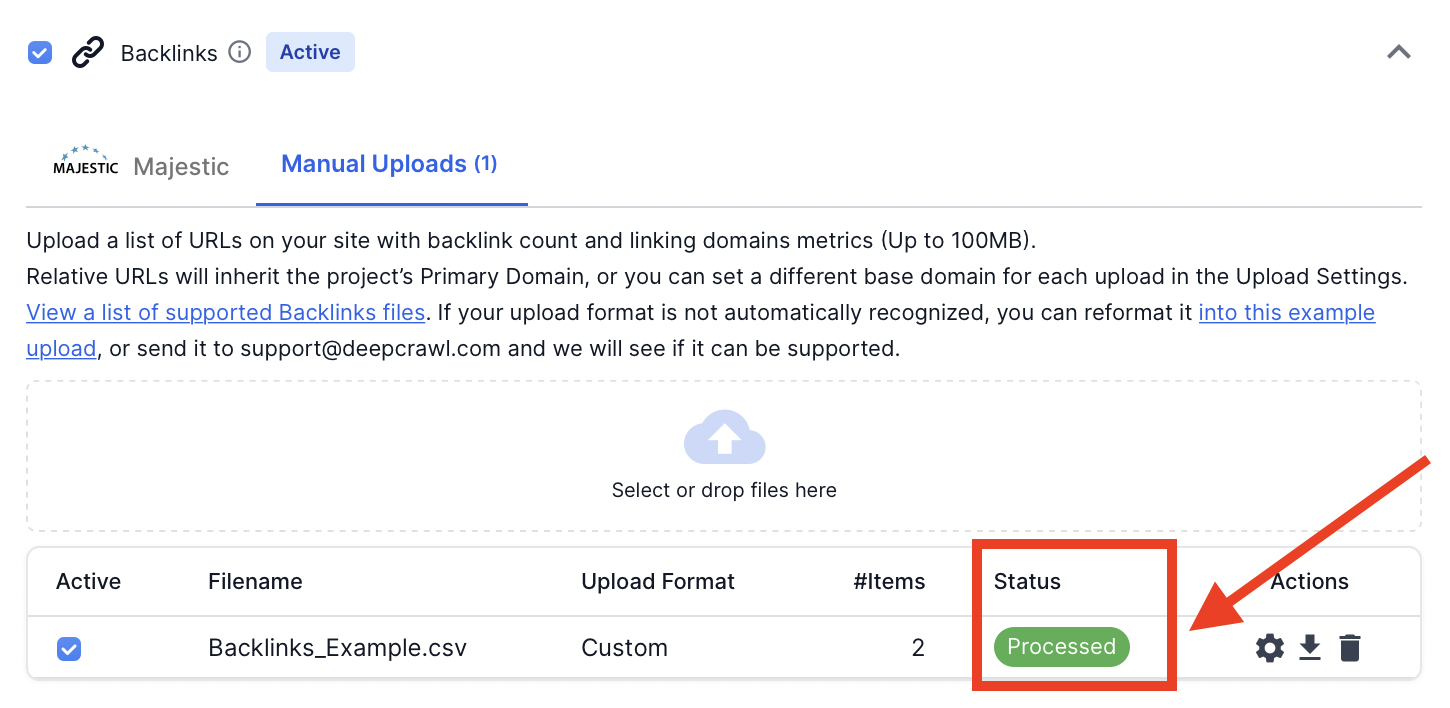
If the 100MB limit per file is not enough, repeat this process for each file uploaded. Once everything is processed you can run a crawl with the backlinks crawl source enabled.
Google Search Console
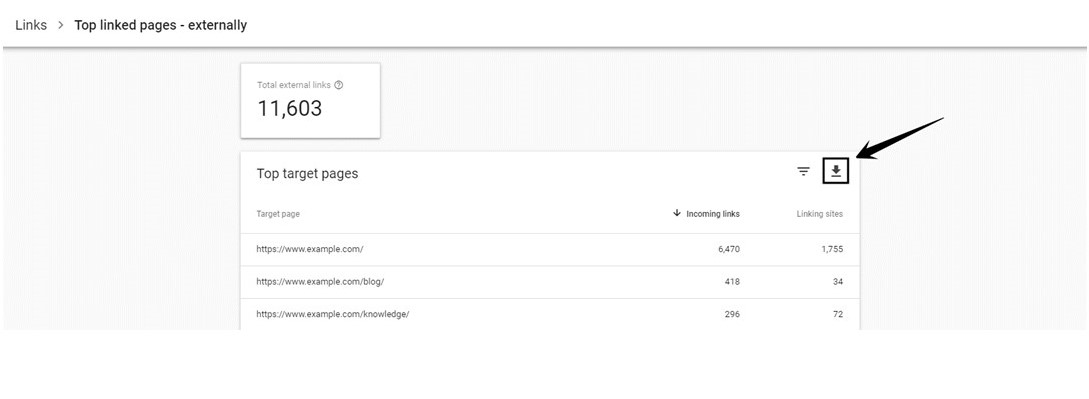
In Google Search Console go to the “Top linked pages – externally” report and click download to get a list of your top target pages with backlinks and linking sites.
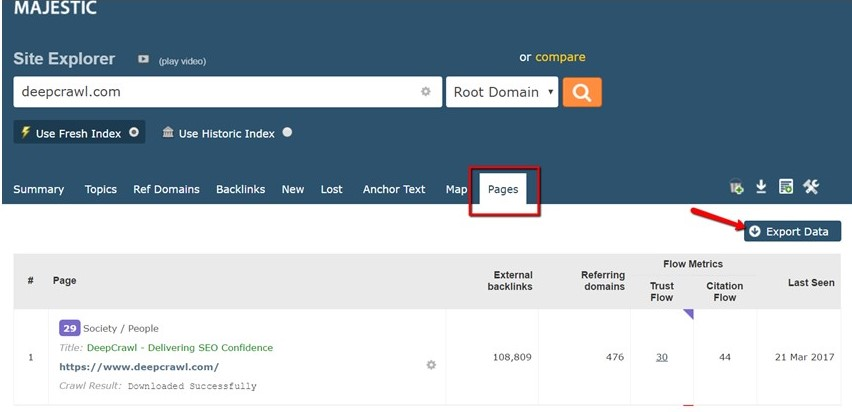
Majestic
Find your website in Majestic, choose the “Pages” report, and export this data to a CSV using the “Export” button.
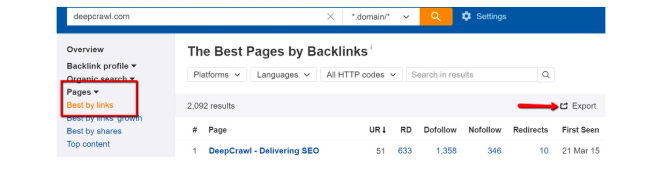
Ahrefs
In Ahrefs, choose the Pages > Best by links report, and export this data to a CSV using the ‘Export’ button. Download the CSV “For Open Office, Libre & other (UTF-8)” and upload this to Lumar.
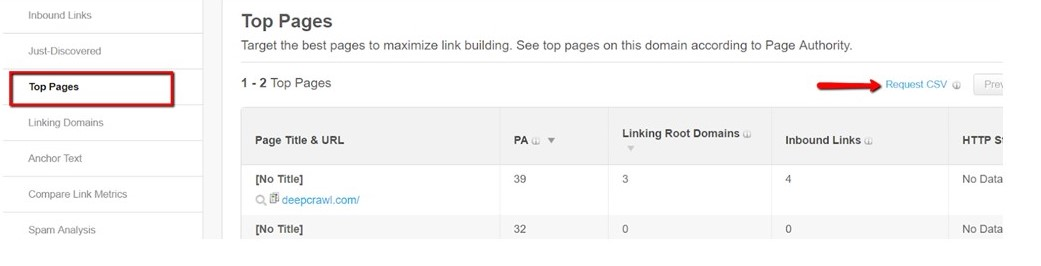
Open Site Explorer
In Open Site Explorer, choose the Top Pages report and export the data to CSV using the “Request CSV” link.
Log Files
Lumar supports a range of exports from your favourite log file analyser. As we are unable to process raw log files; these must be summaries of the number of requests on a URL level.
Log file data can be uploaded to Lumar by dragging and dropping a CSV file (up to 100MB).
When manually uploading a log file, be aware that it needs to follow a specific format for our system to automatically recognise metrics to pull into reports.
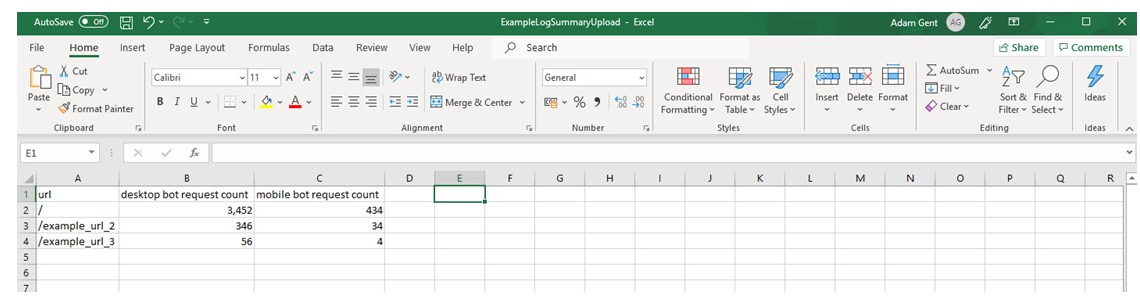
Download an example file with the supported format here.
If an uploaded file is not in the supported format it will not automatically be processed and will prompt the upload settings to appear.
You will need to manually match up the following metrics with the data you have uploaded:
- URL
- Desktop bot request count
- Mobile bot request count
Screaming Frog Log Analyser
Note: The “Screaming Frog Web Crawler” does not process log files. We support exports from the “Screaming Frog Log File Analyser”.
In the Screaming Frog Log Analyser, open the URLs tab, and export the data.
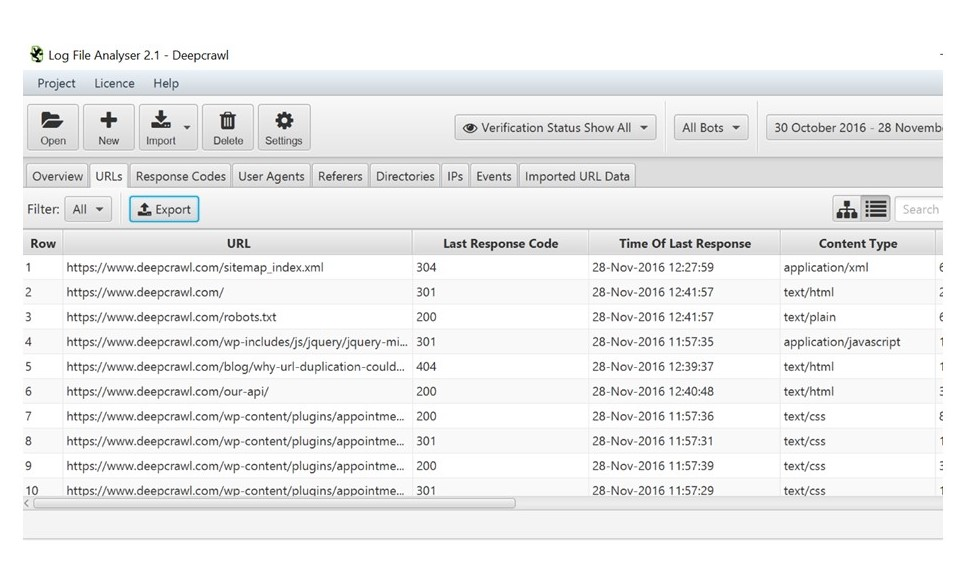
Splunk
Run the following queries to export summary statistics, you will normally need to edit these to match your setup, “host” should be the domain you’re exporting data for, “useragent” is the user agent field, and “uri” is the URL field.
Googlebot:
host=”[YOUR DOMAIN]” | stats count(eval((useragent = “Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)” OR useragent=”Googlebot-Image/1.0″ OR useragent=”Googlebot/2.1 (+https://www.google.com/bot.html)”) )) as “google_desktop_requests”, count(eval((useragent = “Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)” AND NOT useragent=”*deepcrawl*”) )) as “google_smartphone_requests” by uri | rename uri to “splunk_uri” | where google_desktop_requests > 0 OR google_smartphone_requests > 0
Bingbot:
host=”[YOUR DOMAIN]” | stats count(eval((useragent = “Mozilla/5.0 (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm)”))) as “bing_desktop_requests”, count(eval((useragent = “Mozilla/5.0 (iPhone; CPU iPhone OS 7_0 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A465 Safari/9537.53 (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm)” OR useragent = “Mozilla/5.0 (Windows Phone 8.1; ARM; Trident/7.0; Touch; rv:11.0; IEMobile/11.0; NOKIA; Lumia 530) like Gecko (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm)”))) as “bing_smartphone_requests” by uri | rename uri to “splunk_uri” | where bing_desktop_requests > 0 OR bing_smartphone_requests > 0
Please contact our customer support team or your assigned Customer Success Manager for assistance in manually uploading data from Splunk.
Logz.io
In logz.io, open Kibana visualise and create a query using the Metric aggregation “count”, and buckets: Split Rows > Aggregation: Terms, Field: request, Order By: “metric: Count”, Order: Descending, Size: 200.
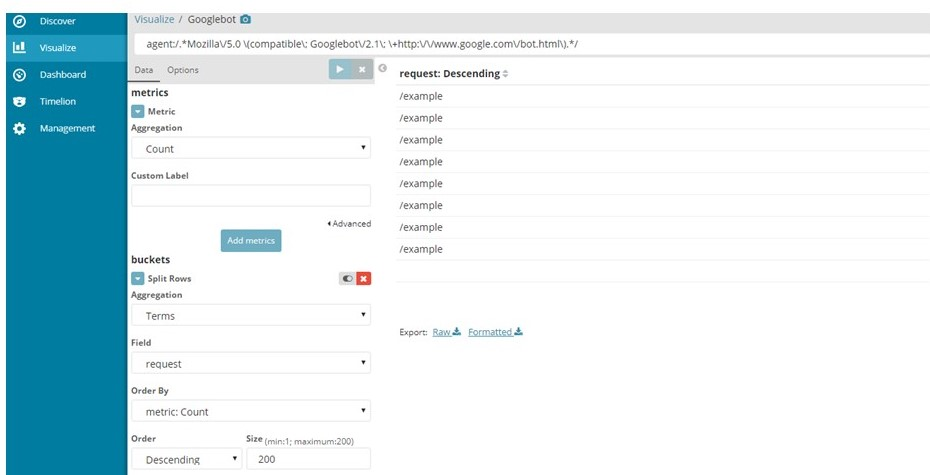
Use the following queries, and export using the “Export Raw” link, then upload this file to Lumar. By default, logz.io will only export the top 200 pages using this method, you should ask your logz.io account manager to increase this limit.
Googlebot Desktop Crawler:
agent:/.*Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html).*/
Googlebot Mobile Crawler:
agent:/.*Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +https://www.google.com/bot.html).*/
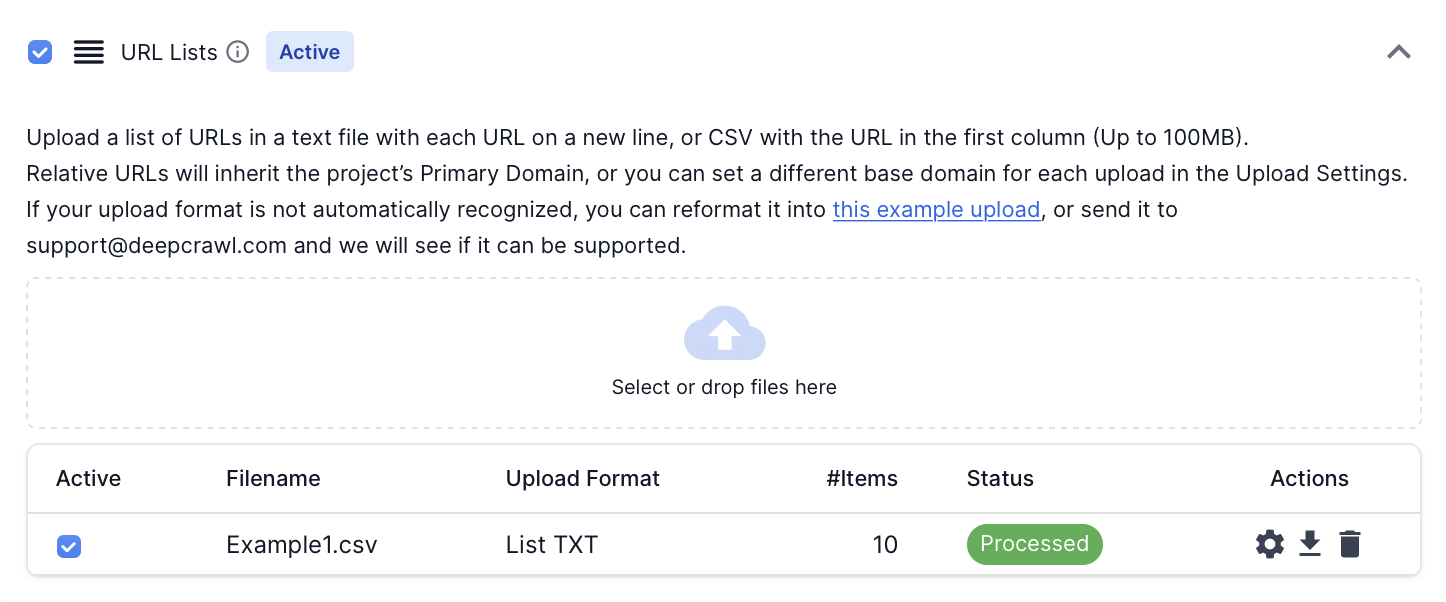
URL Lists
Lumar supports uploading of URL lists to be crawled as a source in the project settings.
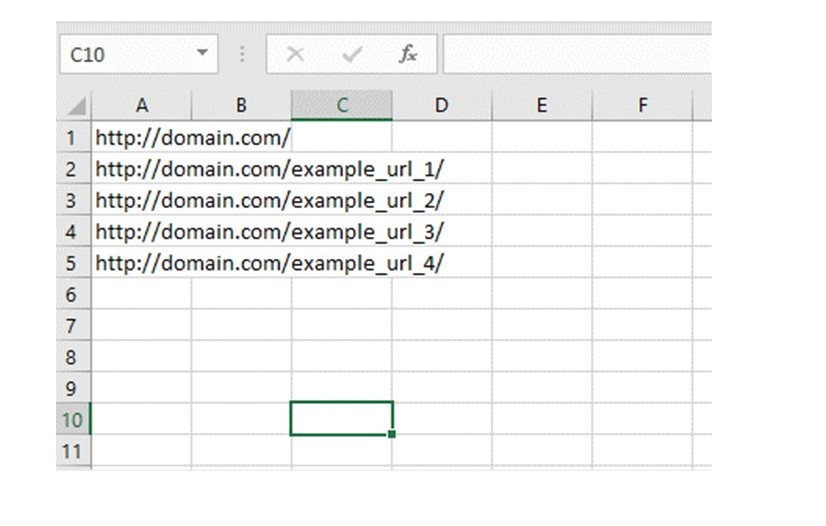
The URL list source supports .txt or .csv file types up to 100MB. Any text files (.txt) uploaded should have URLs on a new line.
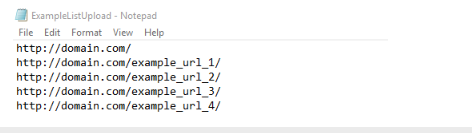
Any comma-separated values (.csv) files uploaded should have URLs listed on each new row in the first column.
Just like all crawl resources, any relative URLs in the supported files will inherit the project’s Primary Domain, alternatively, you can set a different base domain for each upload in the Upload Settings.
Once uploaded it will be marked as processed in the URL Lists crawl source.
Any questions?
If you have any further questions about manual uploading files for different crawl resources in Lumar then don’t hesitate to get in touch.



