

The recent news that Google no longer supports the rel=“next” and rel=“prev” link element has caused many to question how to optimize websites with pagination. This technical SEO guide is aimed at helping website owners and SEO teams to think about how they can optimize and manage pagination on their website.
This guide will discuss:
- What is pagination?
- Google announcement on pagination and SEO
- How Google historically handled pagination
- How Google now handles pagination
- New pagination SEO best practices
- Pagination SEO checklist
Note: This guide is designed to make digital teams think critically about how to handle paginated pages. It should not be considered the guide on pagination. We highly recommend testing and experimenting with the guidance in this guide to see the best results.
Please also read the original research on pagination and infinite scroll on the web which led to this guide as well as the video of Adam’s BrightonSEO talk on the topic.
What is pagination?
Pagination is a process which divides content across a series of pages. It is a common and widely used technique for websites to use pagination to divide lists of articles or products into a digestible format.
Pagination is most commonly found on the following types of websites:
- eCommerce
- News Publishers
- Forums
- Blogs
The main issue with pagination in search is that content is divided across multiple pages, rather than loaded on one page. In the past this issue was overcome using rel=“next” and rel=“prev”, however, Google recently announced that it no longer uses this link element as an indexing signal.
Google announces changes to how it handles pagination
Google has recently updated its official documentation and announced that it no longer uses rel=“next” and rel=“prev” as an indexing signal.

The official announcement was made from the Google Webmasters Twitter account.
Spring cleaning!
As we evaluated our indexing signals, we decided to retire rel=prev/next.
Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search. Know and do what’s best for *your* users! #springiscoming pic.twitter.com/hCODPoKgKp— Google Webmasters (@googlewmc) March 21, 2019
John Mueller, a Webmaster Trends Analyst at Google, also confirmed what this means on Twitter.
We don’t use link-rel-next/prev at all.
— ???? John ???? (@JohnMu) March 21, 2019
To understand the significance of this announcement, we must better understand what affect rel=”next” and rel=”prev” had on pagination in Google’s index.
What is rel=”next” and rel=”prev” and how did Google use it?
Google officially announced rel=”next” rel=”prev” in 2011. The documentation around this link element stated that it helped Google understand the relationship between paginated pages in its index.
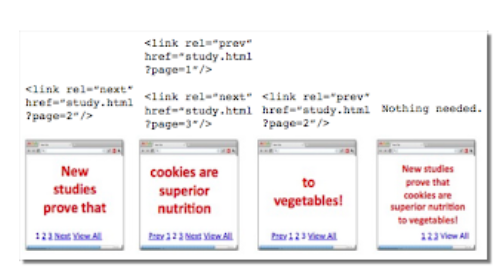
This link element could either be placed in the <head> of a page or in the HTTP header and gave a strong hint to Google that:
- The indexing properties of the paginated pages should be consolidated into one piece of content.
- That most appropriate paginated page should be ranked in Google’s search engine results (usually the first page).
The recent announcement by Google means that the search engine no longer uses this link element as an indexing signal. What this means is that:
- Google no longer uses this link element to consolidate indexing properties.
- Google does not use the link element to identify the most appropriate paginated page to be ranked in search results.
If Google doesn’t use rel=”next” and rel=”prev”, then how does it handle paginated pages in its index?
How Google handles paginated pages without rel=”next” and rel=”prev”
John Mueller has given more insights in a Google Webmaster Hangout into what this announcement means in how Google handles paginated pages in its index.
“We don’t treat pagination differently. We treat them as normal pages.” – John Mueller, Google Webmaster Office-hours Hangout 22 March 2019.
This now means that paginated pages are treated just like any other page on your website in Google’s index. Rather than a series of pages consolidated into one piece of content, they are now treated as individual unique pages.
For example, if an ecommerce website has a category page and 3 paginated pages:
https://www.shopy.com/category-1
https://www.shopy.com/category-1?page=2
https://www.shopy.com/category-1?page=3
https://www.shopy.com/category-1?page=4
Each of these pages is an individual page which needs to stand on its own. That means instead of one category landing page, there are now in fact five individual pages within a category. Now that rel=“next” and rel=“prev” is no longer supported, it is now more important than ever that traditional on-page SEO optimization techniques are employed to manage pagination.
Below we have listed the most important traditional SEO optimization techniques which should now be thought about when optimizing pagination. This list should not be thought of as the list. It is a list which we think are the most important SEO techniques, but this might change from site to site.
Traditional SEO techniques when optimizing paginated pages
In this section we’ll go through some of the considerations SEOs need to think about when optimizing pagination on their website.
Canonicalization and indexing
The first instinct of many SEOs is to canonicalize or noindex paginated pages. This tactic is usually aimed at reducing index bloat which has been found to be effective on improving rankings for websites with low-quality content. However, for pagination this tactic (in theory) might cause a negative impact on rankings on deeper-level pages. Especially if there is not a thorough understanding of the website’s link architecture.
To understand why this might negatively impact your rankings we must first understand (briefly) how canonicalization and indexing theoretically work in Google.
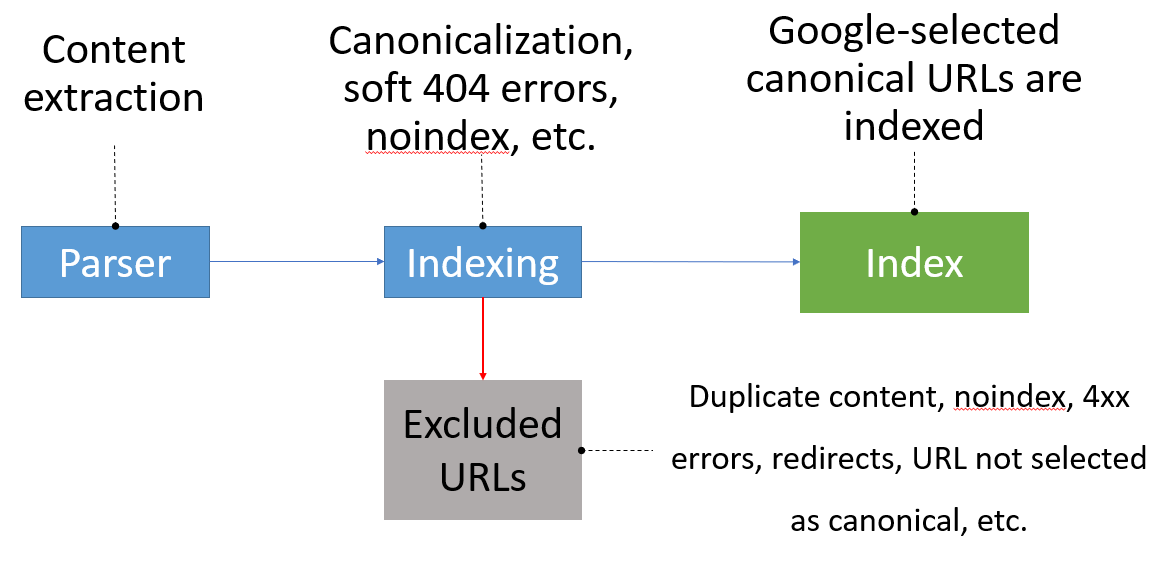
According to Google’s own documentation their system tries to select a canonical for every URL they crawl and process before it is indexed.
“When Googlebot indexes a site, it tries to determine the primary content of each page. If Googlebot finds multiple pages on the same site that seem to be the same, it chooses the page that it thinks is the most complete and useful and marks it as canonical.” – Consolidate duplicate URLs
Every page which is indexed by Google goes through the same process, and many signals are taken into account before it is selected as the Google-canonical page. Any pages which are not selected as the canonical are excluded and the content is not indexed.
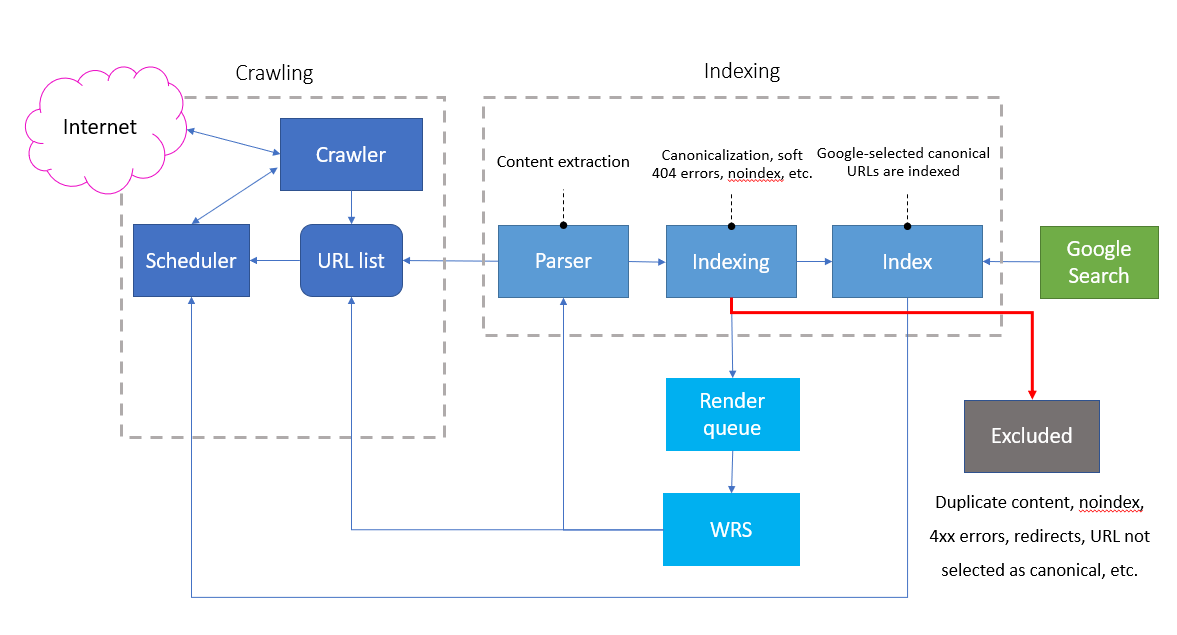
The diagram above is taken from a combination of slides from the Google I/O 2018 conference, and Martin Splitt.
Once Google has selected canonical pages on a website, these are used by the indexing and ranking system as:
- The main source to evaluate page content.
- The main source to evaluate page quality.
- The main page to display in search results.
Any pages not selected as the canonical in the system are:
- Crawled less frequently than the Google-selected canonical page.
- Not used to evaluate page content or content quality.
- Excluded from being indexed and indexing signals (links) are folded into the canonical page.
One of the most interesting comments from Webmaster Trends Analyst John Mueller was around how Google’s systems handles a page which is excluded from the index. He stated in a Google Webmaster Hangout:
“If we see the noindex there for longer than we think this this page really doesn’t want to be used in search so we will remove it completely. And then we won’t follow the links anyway. So, in noindex and follow is essentially kind of the same as a noindex, nofollow.” – John Mueller, Webmaster Trends Analyst at Google, Google Webmaster Hangout 15 Dec 2017
He also mentioned on Twitter in a conversation with other SEOs after this announcement that if a page is dropped from the index, everything is dropped around that page.
Nothing has changed there in a while (at least afaik); if we end up dropping a page from the index, we end up dropping everything from it. Noindex pages are sometimes soft-404s, which are like 404s.
— ???? John ???? (@JohnMu) 28 December 2017
These are interesting comments as they indicate that, over a long period of time, Google’s systems could drop content and outbound signals from a page which is excluded from its index (but fold inbound signals like redirects or external links into the canonical page).
Based on this information, it is critical that important paginated pages are indexed. As the purpose of pagination is to help users and bots navigate to deeper level pages (products, articles, etc.).
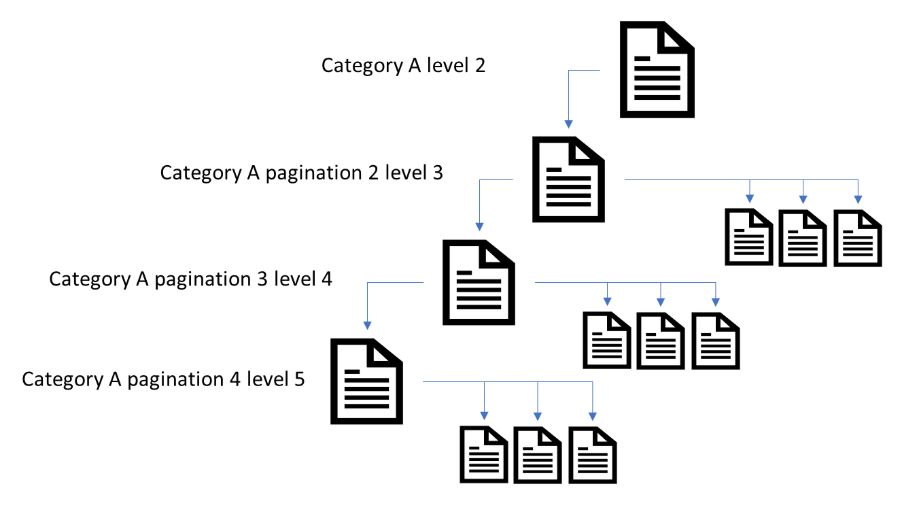
When paginated pages are excluded from Google’s index, then this would drop all signals from those pages. This would include the content which contains internal links to deeper level pages (product URLs, news articles, etc.).
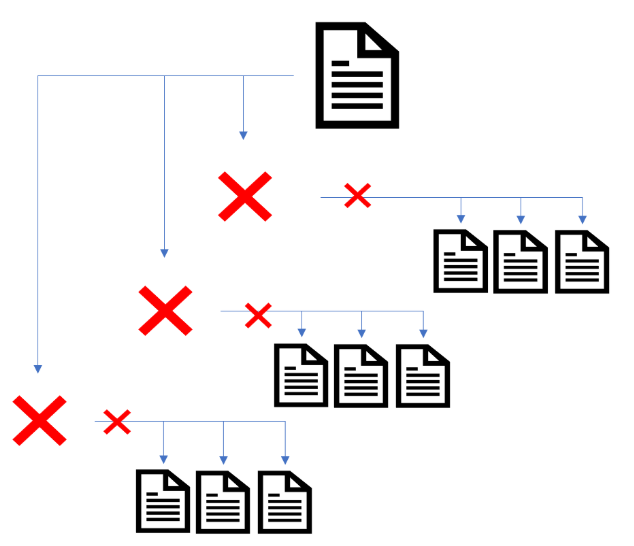
Any relevancy, importance or link authority signals to deeper level pages would be removed. It would also effectively create orphaned pages on your website. The removal of paginated pages, over time, would impact on deeper level pages ability to rank in Google Search.
Our team recommends that any important paginated pages, which help users or bots discover unique content should be indexed.
Tips:
- Make sure important paginated pages are indexed in Google.
- Use the URL Inspection Tool to understand if Google has selected a page as the canonical version.
- Use the Indexation Coverage Status report to understand which paginated pages have been excluded from Google’s index.
- Use third party crawlers to understand how important pagination is within the link architecture of your website. For example, run a full crawl and then another one excluding paginated pages and see which important pages are excluded from the crawl data.
- Use third party crawlers to identify non-indexable paginated pages which have a noindex directive or are canonicalized by using rel=canonical link element.
Link architecture
A website’s navigation should be simple, crawlable and pages should be no more than 3 clicks from the home page. The process of pagination breaks a piece of content into multiple pages, which adds more clicks from the home page. Now that Google no longer consolidates paginated pages into one piece of content, SEOs need to be reliant on traditional website architecture best practices.
In this section we will discuss link architecture best practices that SEOs need to consider when optimizing pagination.
Clicks away from the home page
One of the most important on-page SEO best practices with link architecture is the number of clicks away from the home page. The reason why click depth is important is due to link authority (PageRank) which is passed from one page to another.
The PageRank algorithm is one signal used by Google to understand important pages in search results. It is one of many signals used by Google to determine how well pages rank, to how frequently pages are crawled by Googlebot.
A great explanation of how PageRank works has been recently published by Dixon Jones over at Majestic. In this explanation, he shows that the PageRank calculation has a dampening effect. Which means that as PageRank passes from one page to another a small amount is lost.
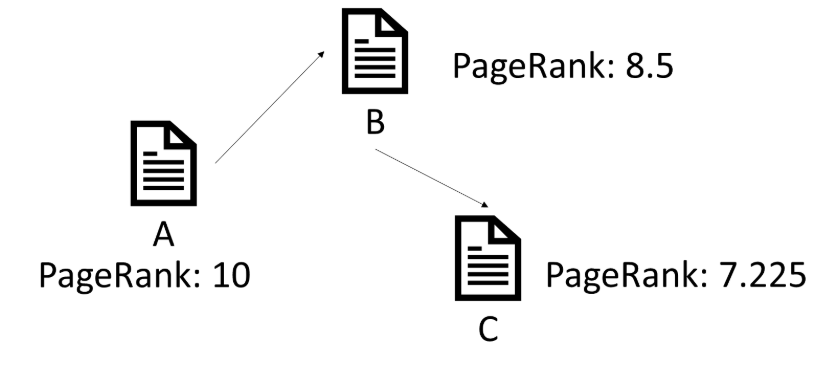
If pagination is too deep, then both paginated pages and any pages linked to from these deeper-level paginated URLs will receive less PageRank than pages higher up in the link architecture.
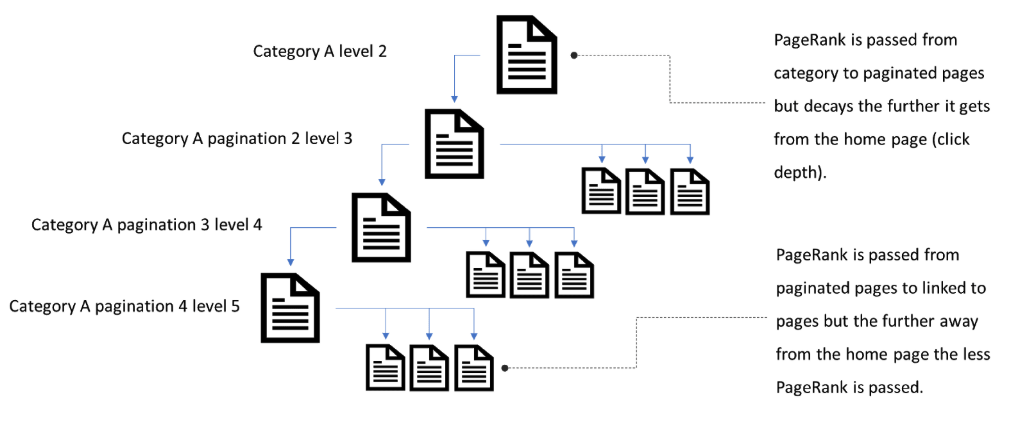
With Google’s recent announcement and change in handling pagination this now means that paginated pages need to be treated just like any other category or page. They need to be no more than 3 clicks from the home page (or as close to the root as possible).
Reducing the click depth will help paginated pages get crawled more frequently. It will also help pages linked to from pagination a better chance at ranking in Google Search for relevant queries.
Although identifying the click depth of paginated pages and deeper-level page is important, internal linking practices need to use to help reduce clicks away from the home page.
Tips:
- Run a crawl of the website and identify the paginated page click depth from the home page.
- Analyse the deeper pages linked to from paginated pages and identify the click depth of pages reliant on paginated pages.
- Use internal linking methods to reduce click depth for paginated pages and deeper level pages (see below).
Pagination and internal linking
A well optimized website should have a simplistic and crawlable internal link structure which allows search engines and users navigate the website. As already mentioned, every important page should be no more than 3 clicks from the home page, that includes paginated pages.
To understand the effect pagination is having on a website’s link architecture you must look at the accessibility points that category pages and product/articles pages can be accessed.
In a basic website architecture model, most websites have a very siloed structure, with category pages accessed from the home page and product pages access from category pages (including pagination).
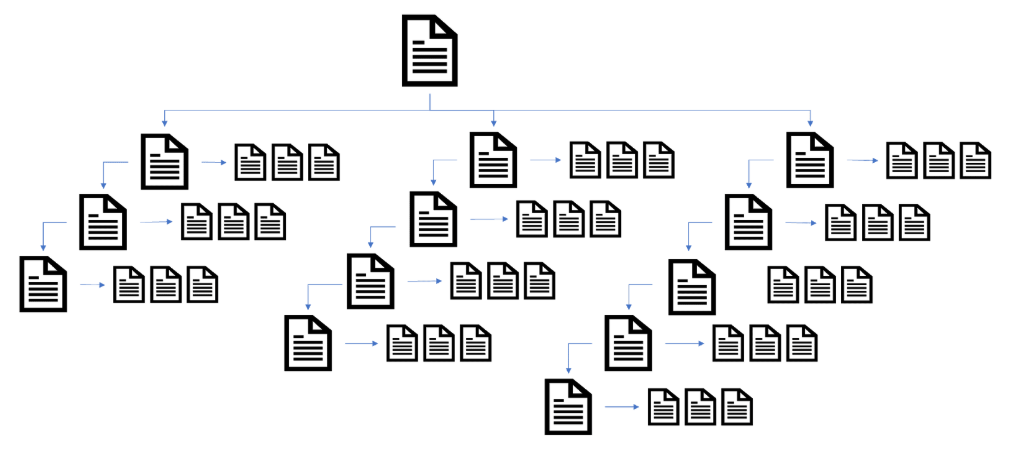
However, using internal linking methods a site owner can improve the internal link structure of their website by linking to deeper-level pages from different access points on the website (not just linear silo structure).
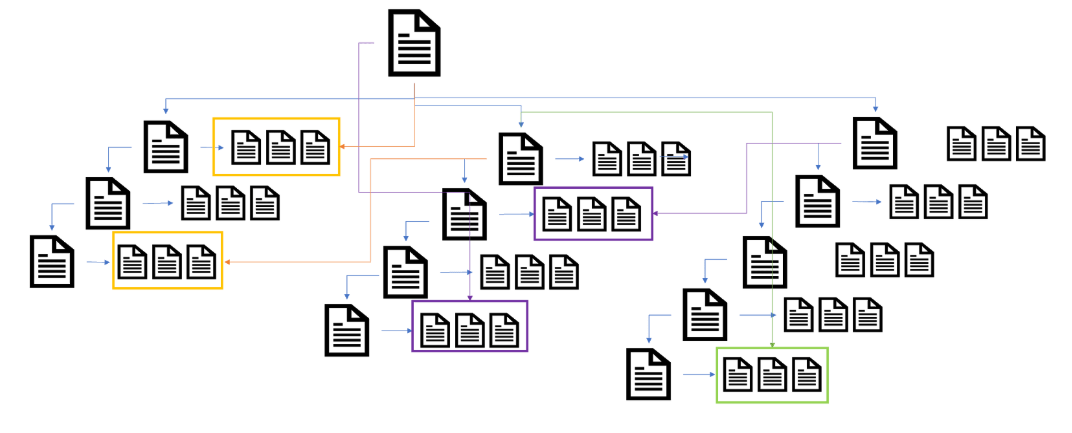
There are a lot of helpful resources in the SEO community which can add further (and A LOT better) advice on how to use internal link methods to help reduce click depth on the website with pagination:
- Read – An SEO’s guide to site architecture by Richard Baxter
- Read – The Ultimate Guide to Site Architecture Optimization by Rachel Costello
- Read – 15 Site Architecture Tips for Performance SEO: Master Guide by Cyrus Shepard
- Read – Internal Link Optimization with TIPR by Kevin Indig
As well as reading internal link resources within the community we also recommend analyzing your website’s link architecture to identify which pages are reliant on pagination. This will help you quickly form a plan of action around which pages need to be improved with your internal link strategy.
For example, our testing on Alexa top websites found that some sites lost 30 – 50% of their pages when excluding paginated pages from being crawled.
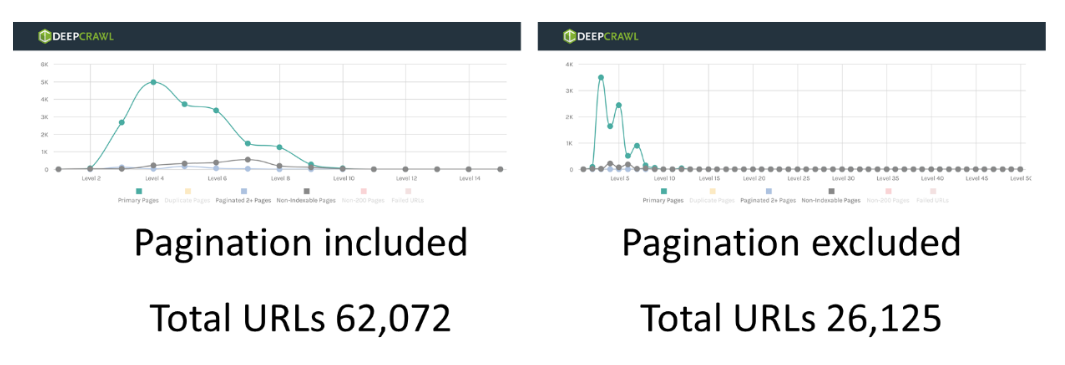
This shows that many websites can be very reliant on pagination for links to be discovered in web crawling. As already discussed in the indexing and canonicalization section, if paginated pages are excluded this could mean that a large part of the link architecture is not being followed by Google.
It is critical that SEO experts understand the role of pagination in the link architecture of their website.
Pagination design and link schemes
As well as using traditional internal linking techniques to reduce the click depth, there is also another way to reduce pagination click depth. A pagination experiment done by Matthew Henry at Portent looked at the effect of pagination links on the click depth of pagination.

The experiments he ran on different pagination link schemes found that the design of internal linking between paginated pages affected click depth.

In his experiment, Matthew found that specific pagination designs were better than others when trying to reduce click depth.
When testing the pagination link schemes on the Alexa website data, our team found similar results to the Portent experiment. For example, the “Next” link scheme was the worst at reducing click depth in pagination.

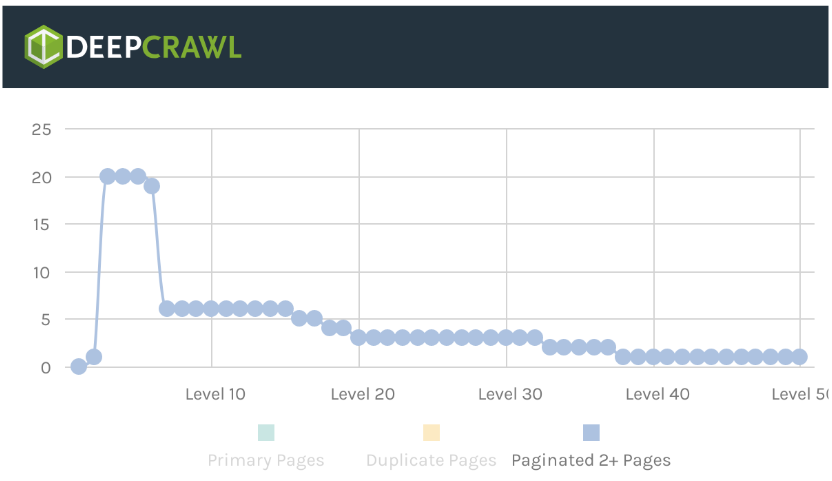
The “Stepping by Two Pages” link scheme in the experiment made pagination improve the pagination click depth for websites that used it (a lot better than ‘Next’).

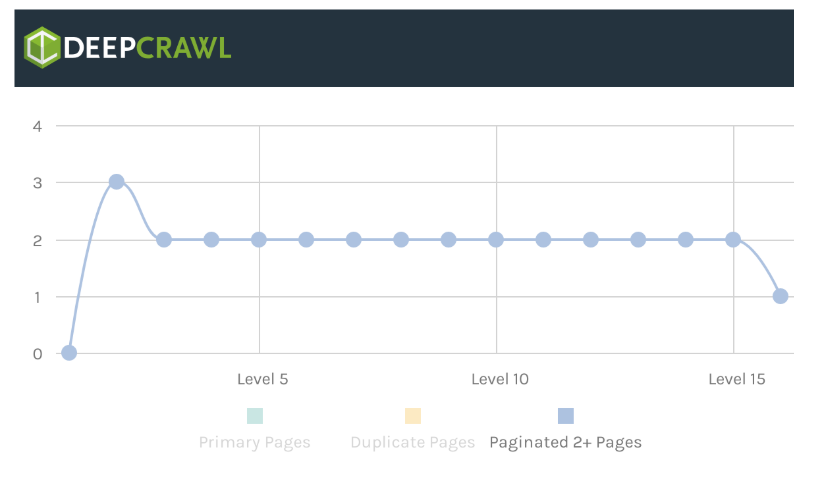
Just like the Portent experiment, our own testing found that there was definitely a link between the design of the pagination link scheme and the click depth of paginated pages.
Adding link schemes to the pagination design can help to reduce click depth. Experiment and test the effect of adding new link schemes to your pagination before implementing on your live website. However, it is important working with designers, product and engineering teams before implementing new pagination designs.
Tips:
- Use third party crawlers to identify the pages which are reliant on paginated pages to be linked to and found in a web crawl.
- Use internal link methods in the resources highlighted in this section to improve click depth on the website.
- Start a crawl on the first page of a paginated series and include only paginated URLs within that series to determine the click depth of paginated pages.
- Review the link scheme of your pagination design and test what effect on click depth adding new links to the pagination link scheme (see Portent article for full details of the experiment).
- Work with design, product and engineering teams to implement a search and user-friendly pagination link scheme.
Pagination and information architecture
Breaking down your website into topics or subtopics is a great way to boost your SEO performance. Doing proper keyword research and intent mapping to different sections of your site can help improve the overall user experience and help stop web pages competing for the same keywords.
However, if a website’s taxonomy is not managed properly, it can harm your SEO performance. This is especially so if categories and sub-categories use pagination and create “deep” silo structures. This can bury important pages within the website architecture and make it difficult for users to find pages.
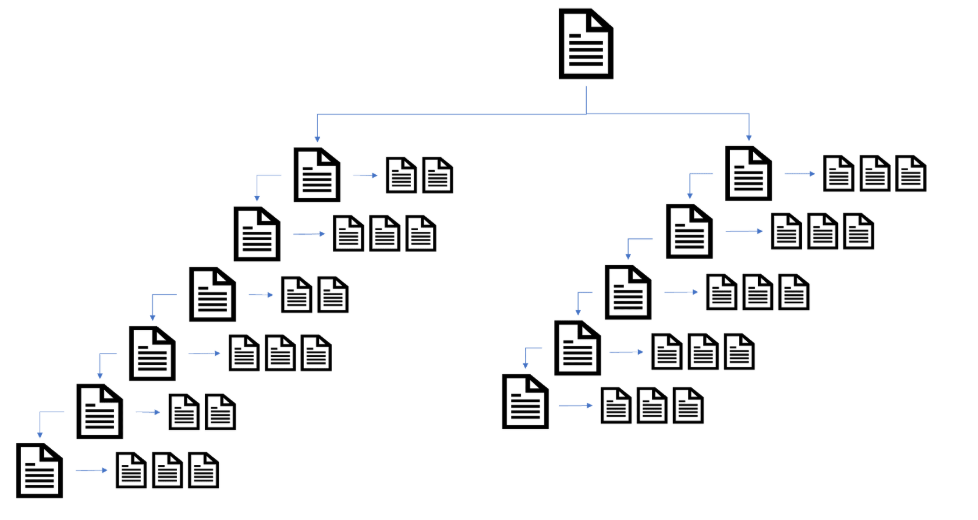
It is now more important than ever to make sure that when mapping out a search friendly website taxonomy that categories and sub-categories are broken down to simplify the website navigation. This will help to reduce the click depth of deeper level pages and help boost SEO performance.
Tips:
- Read the following guides on information architecture to get started on reviewing and improving your website architecture:
- What is Information Architecture (IA)? by Pedro Dias
- Structuring Your Site for Success with Jamie Alberico and Jon Myers
- Building a Themed Website by Bruce Clay
- Use a web crawler to understand the click depth of your category or subcategory pages and identify how easy it is for search engine crawlers and users to reach the deepest page.
Facet navigation and pagination
The efficiency of crawling is an important part of making a website search friendly. Facet navigation (also called faceted search) on many websites, particularly eCommerce sites, can be an enormous challenge to manage — as facets and filters can create thousands of duplicate or similar pages.
This issue is made even more complex when you add paginated pages, which are treated as like any page on your website, as facets and filters can create 10x more duplicate or similar web pages due to additional pages on the website.
https://www.example.com/product-category/ – individual page
https://www.example.com/product-category?page=1 – paginated page
https://www.example.com/product-category?page=1&filter=165 – duplicate 1 of paginated page
https://www.example.com/product-category?page=1&sort=75 – duplicate 2 of paginated page
It is important to make sure that facets and filters are being managed just like any other category page on the website. Our team recommends the following guides on how to manage facet navigation:
- Faceted navigation best (and 5 of the worst) practices by Maile Ohye and Mehmet Aktuna
- Faceted navigation for SEO best practices by Maria Camanes
Managing facet navigation on pagination can be complicated, especially if the pagination on the website also uses parameter (query string) URLs. It is important to make sure that pagination is not caught up in being blocked or canonicalized along with other parameter URLs. As discussed in the indexing section of this post, Google might drop paginated pages from its index and stop following links to deeper level pages.
Tips:
- Use web crawlers to check if paginated pages are accidently canonicalized or blocked by robots.txt.
- Use web crawlers to identify query string URLs (parameters) that are being generated due to facets or filters on the website.
- Implement the same facet navigation best practices (see resources above) on paginated pages as you would on category pages on your website.
- Monitor how Google is crawling and indexing query string URLs using the Index Coverage Status report.
High-quality content
Google is focused on providing high-quality content to its users in search results. Its algorithms are designed to improve rankings for websites whose content meets this ‘high-quality’ threshold. On the flip side, its algorithms are also designed to decrease the visibility of low-quality websites in search results.
“One other specific piece of guidance we’ve offered is that low-quality content on some parts of a website can impact the whole site’s rankings, and thus removing low quality pages, merging or improving the content of individual shallow pages into more useful pages, or moving low quality pages to a different domain could eventually help the rankings of your higher-quality content.” – https://webmasters.googleblog.com/2011/05/more-guidance-on-building-high-quality.html
The recent announcement by Google, that paginated pages are treated like any other page, raises questions around pagination content quality and how this should be handled. The first step in understanding how to improve the quality of the page is to understand its purpose.
The main purpose of paginated pages is usually:
- To allow users to scroll through products or services
- To sell products or services
- To allow users to scroll through posts or news articles
At first, many would consider a paginated page to be lower quality than the category or first page, but according to the Google Quality Rater Guidelines:
“As long as the page is created to help users, we will not consider any particular page purpose or type to be higher quality than another. For example, encyclopedia pages are not necessarily higher quality than humor pages.” – Google Quality Rater Guidelines, page 8
Although understanding the purpose of the page is the first step in making it high quality, what other factors need to be considered? John Mueller provides guidance on what site owners should do:
“I’d also recommend making sure the pagination pages can kind of stand on their own. So similar to two category pages where if users were to go to those pages directly there would be something useful for the user to see there. So it’s not just like a list of text items that go from zero to 100 and links to different products. It’s actually something useful kind of like a category page where someone is looking for a specific type of a product they can go there, and they get that information.” – John Mueller, Google Webmaster English Hangouts
Just like any other category or landing page on the website, users should be thinking about improving the user experience on paginated pages to help achieve its purpose. This includes (but not limited to):
- Mobile friendly web pages.
- Site speed.
- Facets and filters to help narrow down products.
- PushState and History API.
- Product or post item layout on pagination.
Any pagination which is indexed should focus on improving the user experience and design of pagination, as it will help to achieve its purpose. If a paginated page is helping users, then it shouldn’t be considered low quality by Google.
Tips:
- Read UX and design resources to create a seamless experience on paginated pages.
- Read Google’s Ecommerce Playbook to learn practice ways to improve UX (if you’re an e-commerce site).
Unique content on paginated components
Making sure landing pages contain unique and relevant content is a critical part of making websites high-quality. It is also an important part of getting pages indexed in Google. As already discussed, Google extracts content from every web page and identifies a Google-selected canonical page.
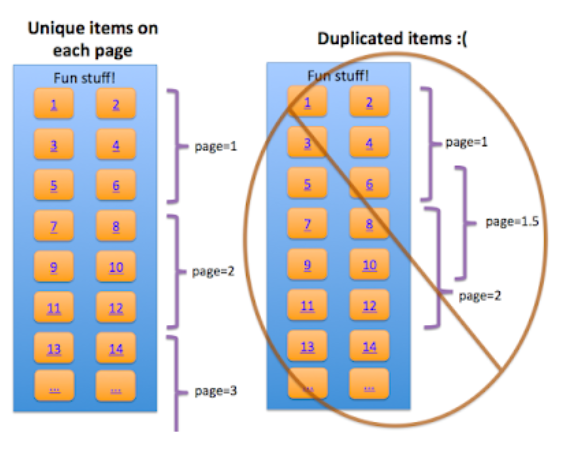
If a web page is not unique (duplicate or similar) then it will be excluded from Google’s index during the indexing process. As already discussed in the canonicalization section, this may mean that Google will eventually stop following any links on pagination. So, it is important to make sure that each paginated component is unique.
This doesn’t mean that each category page needs added text content to make it unique. It means that the posts or products which are listed on the paginated pages should not be duplicated across each paginated component.
Tips:
- Use third-party web crawlers to detect duplicate paginated pages.
- Use third party tools to check how similar paginated pages are.
- Use the Index Coverage report to identify if paginated pages are valid and indexed.
Prioritize items on paginated pages
As well as ensuring that paginated pages are high quality and unique, it is also important to make sure that products or items listed are sorted in order of priority on paginated pages.
There are a number of reasons why posts or products should be prioritized:
- Users can easily find popular posts or products easily.
- Popular posts or products are few clicks from the home page.
Sorting the posts or products by priority can help boost SEO performance and drive on-site engagement.
Tips:
- Sort articles or products by priority, with the most important on the first page, in a paginated series (if possible).
- Test the grid layout of products or articles to improve both user-experience and include internal links to priority landing pages on the first page.
- Use third party crawlers to identify if important pages are being linked from the first page of a paginated series.
- Remember to provide clear product or article information on all paginated pages.
Keyword cannibalization
Google’s change to how it handles pagination means that it now stands on its own. Paginated pages are individual pages and no longer consolidated into one piece of content in Google’s index.
Unfortunately, due to the content on paginated pages they are similar page types split across multiple pages. This means that rather than having one category page targeting one topic (set of keywords), a website could now have two or more individual pages per category which can potentially rank for the same topic (set of keywords).
In the past rel=“next” and rel=“prev” were used to indicate the first page in the series and Google would rank it appropriately. However, this link element is no longer supported. So, traditional internal linking methods now need to be used to give strong signals to search engines about which page is related to which topic or set of keywords.
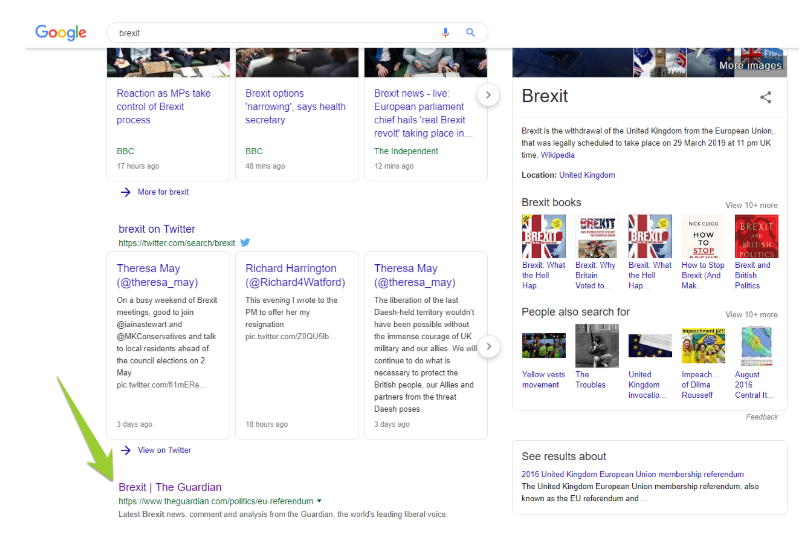
An industry that is used to managing a large volume of content around the same topic is publishing. News search engine experts within this industry employ internal link schemes to manage keywords to stop Google getting confused around which page should rank for a specific topic or keyword. For example, take theguardian.com.

The site links is using specific keyword anchor text in news articles back to top-level pages. This gives clear signals to search engines that the top-level page is about the broad topic (for example the ‘Brexit’ page is about ‘Brexit’). This may seem too simplistic, but to search engines, this gives a clear signal for which page should rank for which keyword (if there is confusion about which page to rank).
The guardian.com also uses other internal linking techniques to continue to give clear signals to Google for the top-level category page. For example, the site consistently uses the same anchor text in the ‘Topics’ widget to link back to the top-level ‘Brexit’ page.

Using a simple navigation and giving clear internal link signals allows news publishers to rank top-level category pages or specific news articles for certain sets of keywords. It also stops Google from getting confused around which page should rank for which keyword.
Websites that are finding that the first page in pagination is not ranking for the appropriate topic or keyword, should handle keyword cannibalization in the same way as news publishers. Use internal link and anchor text to give strong signals to search engines so that the first page in a pagination series ranks for the relevant sets of keywords (as well as using on-page SEO optimization techniques).
Tips:
- Use Google Search Console Performance report or third party ranking tools like Pi Datametrics to identify paginated URLs competing for the same keywords.
- If page 2+ are ranking for important keywords, use third party crawlers to identify the anchor text used for internal links pointing back to the first page in a paginated series.
- Improve internal linking and anchor text to make sure Google is given strong relevancy signals around which page should rank for keywords.
Pagination SEO checklist
Using both old and new SEO considerations, we have provided a technical SEO checklist on how to optimize pagination.
Create unique URLs for paginated components
Each pagination component that is generated in a content management system (CMS) or web app, should have a unique URL. Google requires URLs to discover, crawl, and index content.
If a paginated page is not crawled and indexed, then the likelihood of Google discovering pages linked to from pagination is unlikely through web crawling unless linked to from another page.
Pro-tip: Use parameter URLs for the paginated pages as it is easier for Google to pick up the pattern for crawling purposes.
Avoid: Using fragment identifiers (#) in the URL, as Google will ignore any content which is after the # (for example /#page=2).
Use crawlable links to paginated pages
It is not just creating URLs for paginated components, as a website also needs to have crawlable links for Google to be able to discover, crawl and index paginated pages. Make sure the paginated pages are linked to using anchor links and have an ahref attribute pointing to the URL of paginated page.
Can follow:
- <a href=”https://example.com/product-category?page=2″>
Can’t follow:
- <a routerLink=” /product-category?page=2″>
- <span href=” https://example.com/product-category?page=2″>
- <a onclick=”goto(‘https://example.com/product-category?page=2’)”>
Also, just like any other page on your website, Googlebot should not be blocked from crawling paginated URLs using the robots.txt file or rel=”nofollow”.
Pro tip: Use third party crawlers to check if links are crawlable and can be found. If they can’t, then inspect the pagination links using View Page Source or Inspect Element on paginated pages.
Avoid: Accidently blocking paginated pages using the /robots.txt file. Use the Google Search Console robots.txt Tester when blocking query string URLs (parameters) to make sure paginated URLs are not being blocked.
Make sure Google selects paginated pages as the canonical
As already mentioned in this article, it is important that Google indexes paginated pages on the website. This will make sure that any deeper level pages linked to from paginated pages are discovered and crawled through web crawling (not just XML Sitemap discovery).
Use the right signals to indicate to Google that paginated pages are canonical URLs and should be indexed.
Also, make sure content on paginated pages is unique and not duplicated. Google will pick up the duplicate content and pick a canonical version of the page.
Pro tip: Use self-referencing rel=canonical link tag method on important paginated pages you want Google to index and make sure paginated pages can be found through internal links.
Avoid: If you want important paginated pages indexed, avoid canonicalizing paginated pages so that paginated pages rel=canonical link tags point to the first page in the paginated series.
Allow paginated pages to be indexed
Make sure that paginated pages can be indexed by Google, once canonicalization signals have been configured. This is especially important for pagination which provides the only way for users and bots to navigate to deeper-level pages.
Read more on canonicalization and indexing in this article to find out why important paginated pages should be indexed.
Pro tip: Use third-party web crawlers to identify if important paginated pages are non-indexable (noindex, canonicalization, 4xx HTTP status code, etc.) and monitor pagination status over time.
Avoid: Noindexing o canonicalizing important paginated pages to reduce index bloat.
Pagination and link architecture
Reducing the amount of clicks from the home page to deeper level pages will help pass PageRank to these pages. This will help to boost the SEO performance of deeper level pages.
Try to make sure that paginated pages and deeper level pages linked to from pagination are no more than three clicks to the home page. To do this, use the following resources to better understand how to implement internal linking techniques:
- Read – An SEO’s guide to site architecture by Richard Baxter
- Read – The Ultimate Guide to Site Architecture Optimization by Rachel Costello
- Read – 15 Site Architecture Tips for Performance SEO: Master Guide by Cyrus Shepard
- Read – Internal Link Optimization with TIPR by Kevin Indig
Pro tip: Use third party crawlers to identify the click depth of your website and use crawl data to understand which paginated pages and deeper level pages need to be optimized.
Avoid: Trying to add internal links to deeper level pages on irrelevant pages or in ways that don’t help the user.
Pagination design and link schemes
As well as looking at traditional techniques, experiment with your pagination design and link schemes to reduce click depth. An experiment by the Portent agency and our own data has shown that this can affect the click depth of pagination.
Pro tip: Experiment, test and use third party crawlers to measure the reduction in click depth when adding links to your website’s pagination design.
Avoid: Working in isolation and just implementing a crazy pagination link scheme without testing.
Pagination and information architecture
The website’s information architecture should take into consideration pagination when mapping out pages to user intent. Try to reduce the amount of large generic category pages and create relevant subcategory pages to reduce the amount of content which needs to be split out into paginated components. This can help to reduce click depth for deeper level pages and paginated pages.
Read the following guides to get started on improving information architecture on your website:
- What is Information Architecture (IA)? by Pedro Dias
- Structuring Your Site for Success with Jamie Alberico and Jon Myers
- Building a Themed Website by Bruce Clay
Pro tip: Use the Lumar Site Explorer to better understand how your pages are grouped on the website and pages can be found within this group.
Avoid: Generic top-level category pages with too many paginated pages, as this can increase click depth and make finding products or articles hard for users.
Manage facet navigation on paginated pages
It is important to manage facets or filters which create new query string URLs (parameters) on paginated pages, just like any category page on the website. If not properly configured, then this might leave hundreds or thousands of duplicate pages.
We recommend reading the following guides on how to manage facet navigation and choose the best option for your website:
- Faceted navigation best (and 5 of the worst) practices by Maile Ohye and Mehmet Aktuna
- Faceted navigation for SEO best practices by Maria Camanes
Pro tip: Use third party crawlers to identify query string URLs and use the Index Coverage Status report in Google Search Console to monitor their status in the index once configured.
Avoid: Excluding paginated pages from the index with the rel=canonical link tag or the noindex tag. Use third party crawlers to monitor the indexability status of important paginated pages and make sure paginated parameter URLs are configured.
Create unique and useful content on pagination pages
High-quality content is important if paginated pages are going to be indexed, as Google uses canonical pages to evaluate content and quality.
Creating a high-quality paginated page is not about adding more text content to the page, but making sure that the page achieves its purpose.
The general purpose of pagination is to allow users to scroll and find articles or products on most websites. Focus on improving the user-experience and information on these pages, this includes (but is not limited to):
- Mobile friendly web pages
- Site speed
- Facets and filters to help narrow down products
- PushState and History API
- Product or post item layout on pagination
Not only do you need to improve UX, but also make sure that content on these paginated pages is unique. Any article or product lists should not be overlapping as this will cause the pages to be similar. Google may exclude any similar or duplicate pages from its index.
Finally, make sure that priority or popular items (products or articles) are sorted so that they are found on the first page. This will help users quickly find the most popular items and help deeper level pages reduce the number of clicks from the home page.
Pro tip: Use third party crawlers and tools to identify duplicate or similar paginated pages. Use UX and design resources to improve the quality of the page.
Avoid: Adding a load of unique text content to each page as this might confuse Google over which page should rank for particular keywords.
Manage pagination keyword cannibalization
As well as making each paginated page unique and high-quality, you also need to make sure that the paginated pages past the first page are not competing for the first page in search results. This is a balance between making the pages useful but not optimizing them to rank for relevant keywords.
Use relevant internal linking and anchor text around the first paginated page to provide strong signals to search engines around which page should rank for certain keywords or topics. As well as adding internal link signals, de-optimize 2+ paginated pages by altering title tags and removing any ‘SEO content’.
Pro tip: Use third party crawlers to review internal linking and anchor text distribution for first pages.
Avoid: Removing or altering paginated pages too much as this might impact its ability to be indexed. Your aim is to slightly tweak and remove on-page SEO signals so that it helps the first paginated page rank for the relevant keywords.
Summary
Google has changed the way it handles paginated pages within its index. It no longer consolidates paginated pages into one piece of content but instead treats each page separately. This has changed how website owners and SEO experts need to treat a set of paginated pages. They need to optimize and manage paginated URLs just like any other page on their website but remember that these are important access points for deeper level pages.
What is interesting is that a lot of the traditional SEO techniques which were used to manage other pages, are now applicable to pagination. This includes:
- Allowing paginated pages to be crawled and indexed.
- Setting clear canonical signals so Google indexes (important) paginated pages.
- Creating high-quality and useful paginated pages.
- Creating simple and clear navigation on a website.
- Provide clear internal link signals for paginated pages.
- De-optimize 2+ pages so paginated pages do not compete for the same keyword.
Hopefully, this guide has helped point those who are looking for actionable advice in the right direction.





