

In the previous guide, we took you through what a robots.txt file is and how to use it. Now we’ll take a look at a couple of different ways that you can apply robots directives at a page level to instruct search engine bots with rules about how they should treat the pages on your site.
What are URL-level robots directives?
Robots directives are sections of code that give instructions to website crawlers about how a page’s content should be crawled or indexed. Robots meta tags allow a granular approach to controlling how specific pages are indexed and shown in search engine results pages.
Where do they exist?
Robots directives can either exist in the HTTP response header or HTML head. If they are included within a page, they must be located in the <head> section in order to be read and understood by search engines.
X-Robots-Tags are placed in the HTTP response header and are useful for controlling the indexing of non-html content, such as PDF files, video or word documents where it isn’t possible to add robots directives in the HTML head.
Here are a few considerations around X-Robots-Tags:
- It is worth noting that implementing X-Robots-Tags won’t stop crawl budget being wasted because search engine bots are still required to access the page in order to find the directive, unlike with the robots.txt file.
- Serving multiple X-Robots-Tags in a HTTP response header will form more sophisticated instructions to bots e.g. a noarchive X-Robots-Tag can be combined with an unavailable_after X-Robots-Tag.
- If there is any conflict between directives, search engine bots will take the conservative approach and apply the most restrictive directive e.g.a x-robots noindex and meta index means the page will be noindexed.
How do they apply?
Search engines need to crawl a page to see these directives. They can only be followed and understood if crawlers have access to the page, so adding a noindex tag then disallowing the page in the robots.txt file will mean that search engines will not see the noindex meta tag.
You can also create combined robots directives by separating them with commas. For example, you can use the following combination to instruct crawlers not to index a page, but to follow all the links on a page:
- In an HTML meta tag: <meta name=”robots” content=”noindex, follow”>
- In the HTTP header: X-Robots-Tag: noindex, follow
How do you set instructions for specific user agents?
You can address specific user agents and instruct them on how to index a particular page by including a different name=“” attribute. For example, you can tell Bing not to index a page with the meta tag:
<meta name=“bingbot” content=“noindex” />
If you want to address different user agents and provide them with different instructions, you can use multiple robots directives in separate meta tags.
Noindex
In this section of the guide, we’ll explain what the noindex tag is and how it should be used for SEO.
What does noindex do?
A noindex indicates to search engines to crawl a page, but not to include it in their indices. It effectively stops a page from appearing in the search engine results pages (SERPs). It is useful for keeping irrelevant, unnecessary pages from being indexed which can create index bloat.
Google will still crawl noindex pages, but less frequently than indexable pages, so it can help improve the use of your crawl budget.
Noindex gives a direct instruction around how to handle a page, as opposed to ‘Index’ which does nothing as that is the default state for search engines.
What does noindex look like?
This is how the noindex meta tag appears in the HTML head:
<head>
<meta name=”robots” content=”noindex” />
(…)
</head>
This is how the noindex X-Robots-Tag appears in the HTTP header:
HTTP/1.1 200 OK
Date: Fri, 21 July 2017 21:00:00 GMT
(…)
X-Robots-Tag: noindex
Why might you use noindex?
There are a number of different reasons why you might want to use a noindex tag for particular pages on your site, which might include:
- Preventing low quality or thin pages that don’t provide any useful content to users from being indexed.
- Keeping content that isn’t ready yet from being included in the SERPs.
- Stopping unnecessary internal search query pages from being indexed.
- Making sure paginated pages aren’t being shown to users. If you are experiencing issues with paginated pages receiving organic traffic and creating a poor user experience, it may be worthwhile utilising a “noindex, follow” on pages 2 and beyond to ensure page authority passes through the series of pages but the pages themselves don’t show.
- Excluding marketing pages not intended for organic search from the SERPs, such as dedicated email or PPC campaign landing pages.
When shouldn’t you use noindex?
Noindex can be a useful solution for helping reduce index bloat, but it isn’t the answer for everything. Here are some examples where you shouldn’t use noindex:
- For faceted navigation pages – Search engines will still use up crawl budget by visiting these pages. Noindexing all pages in a large section of a site is poor practice as these pages must still be crawled.
- For canonicalised pages – Link equity may not be attributed to the main version if you noindex a canonicalised page. This means that existing signals and authority built on the page will be lost and won’t be passed on. If the canonical tag is ignored by Google, they might end up selecting the noindex version of the page as the canonical, then obey the noindex directive.
- For images – Images that appear on a noindexed page may still be indexed because the image tag is seen more as a link than a directive. Noindex can be implemented in the HTTP header of an image file instead, or you can use “noimageindex”, which we’ll cover later in this guide.
Nofollow
Now let’s look at the nofollow tag, what it is used for and how to use it properly.
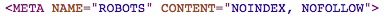
How does nofollow work?
Nofollow tells a crawler not to follow any links on a page or on a specific link (depending on the implementation), meaning that no link equity will be passed on to the target URL. To restrict crawling and improve crawler efficiency, you can use nofollow to prevent URLs that you don’t want equity to be passed to from being crawled.
Using ‘follow’ won’t do anything as this is the default attribute for search engines so it is not required. Nofollow is a command as it goes against the default and gives an instruction.
It’s important to note that nofollowed link targets will still be crawled if they are linked to elsewhere without the nofollow tag, so you need to make sure it is used consistently. Also, if you have two links on a page to the same target, but one is nofollowed, then Google will just crawl the followable link.
Google respects the nofollow directive and won’t pass PageRank across those links. Bing also responds to nofollow, however, for Google and Bing, a page that is nofollowed may still appear in their indices if it is linked to without nofollow either internally or externally. Nofollow also works for Baidu, and link weight won’t be counted with this directive in place. Yandex doesn’t support nofollow, and recommends using noindex instead.
How do you implement nofollow?
If you want to implement nofollow at a page level, this would prevent all links on that page from being crawled, including <a> links, canonicals and rel alternates. In this instance you would include this code snippet in the <head> section:
<head>
<meta name=”robots” content=”nofollow”>
(…)
</head>
When implementing nofollow at an individual link level, you would include this code snippet where you would place the link in the HTML:
<a href=”example.html” rel=’nofollow”>here</a>
The strictest rule wins with nofollow and the most restrictive directive is applied, so this means that the page level meta nofollow will override a link level follow, for example.
Why might you use nofollow?
There are various reasons why you might use nofollow for particular pages or links on your site. Here are some examples where you might use nofollow:
- Paid links – prevent paid product placement links on blogs, for example, from passing link equity, which follows Google best practice around handling non-organic links.
- Affiliate links – Similar to paid links, if search engines believe you are only adding links to generate money which add no real benefit for the user, your site could be penalised if you don’t add nofollow to your links.
- UGC (user-generated content) – Make sure your site isn’t “vouching” for low quality content that you don’t have sufficient control over.
- Faceted navigation – Crawler efficiency can be significantly improved for larger ecommerce websites by nofollowing non-useful facets that are being linked to.
- Embeds – Content embedded from other websites can be nofollowed if you don’t want to be seen as endorsing them.
- Focus the crawler – Direct it to the URLs you want actually want to be visited.
- Links to noindex pages – Nofollowing these would save crawl budget as these links would be followed to pages that wouldn’t be indexed anyway.
Other Robots Directives
There are a number of other directives you can use to communicate with search engines around how to handle the pages on your site. Here are some examples and how each of them works.
None
<meta name=”robots” content=”none”>
This directive is equivalent to “noindex, nofollow.” It basically instructs search engines that the page should be ignored.
Noarchive
<meta name=”robots” content=”noarchive”>
This directive instructs search engines not to show a cached link in search results. It can also be used to prevent competitors scraping your content, which is especially useful on ecommerce sites where prices update frequently.
It’s important to note that this directive prevents users from being able to view a cached version of the page when your site is down or inaccessible, however.
Nosnippet
<meta name=”robots” content=”nosnippet”>
This directive instructs search engines not to show a snippet for this page in the search results. Nosnippet is useful if you want to have more control over what to display to users about the content of the site which could lead to increased CTR depending on the search query.
Notranslate
<meta name=”robots” content=”notranslate”>
This directive instructs search engines not to offer a translation of the page in the results pages. This can be useful as you may not want the content on your page to be able to be translated, because sometimes the automatic translation is not accurate.
You can also specify sections of your page not to be translated using a class:
<div class=”notranslate”><…></div>
Noimageindex
<meta name=”robots” content=”noimageindex”>
This directive instructs search engines not to index images on the page. It is useful if you don’t want others republishing your images as their own, especially if they’re copyrighted. However, if images are linked to elsewhere on a site, search engines will still index them so the x-robots tag may be a better option.
Unavailable_after
<meta name=”robots” content=”unavailable_after: Monday, 11-June-18 12:00:00 UTC”>
This directive instructs search engines not to show the page in the results pages after a specified date or time. This is useful for pages that are relevant for a specific timeframe, such as event registration pages or promotional landing pages (e.g. Black Friday.) The content will be deindexed after the event has finished and you no longer require the page to appear.
For pages with a limited useful time window, using “unavailable_after” is more convenient than putting a noindex on the page at a later date.
Noodp
<meta name=”robots” content=”noodp”>
This directive instructs search engines not to use metadata from the Open Directory project for titles or snippets shown for this page. This has recently depreciated, however, and DMOZ ceases to exist.











