

Is your website as crawlable as you think it is? If search engines cannot crawl your website then your pages can’t rank in the search results. Today we’re going to explore five reasons why your website might not crawlable by search engines (or indeed, your own crawlers) and explain how you can solve these issues.
Crawlability issues are multifaceted, with a melange of potential culprits ranging from on-site tags to off-site settings in webmaster tools. Read on to find out what might be causing your site’s crawlability issues.

This post is part of Lumar’s series on Website Health. In this series, we deep-dive into the core elements of website health that an SEO strategy needs to address in order to give your website content its best chance of ranking well in the search engine results pages (SERPs). Crawlability is a foundational element of website health and contributes to the creation of healthy, high-performing websites.
Crawlability Issue #1: Search engines blocked in robots.txt
Search engines will struggle to crawl your website if you have search engine robots blocked from crawling your pages.
It’s worth noting that the robots exclusion standard (robots.txt) isn’t an effective mechanism for keeping a web page out of Google. As mentioned in the robots.txt guidelines in Google Search Central, search engines can still index pages that are blocked by robots.txt for many reasons — for example, if the URL is linked to by an external source.
Exclusions in robots.txt can, however, direct search engine robots not to crawl certain areas of your website. This won’t stop pages from being indexed, but it could be causing crawlability issues if you are attempting to crawl the site yourself with SEO intelligence tools, leading to poorer insights into your website’s health.
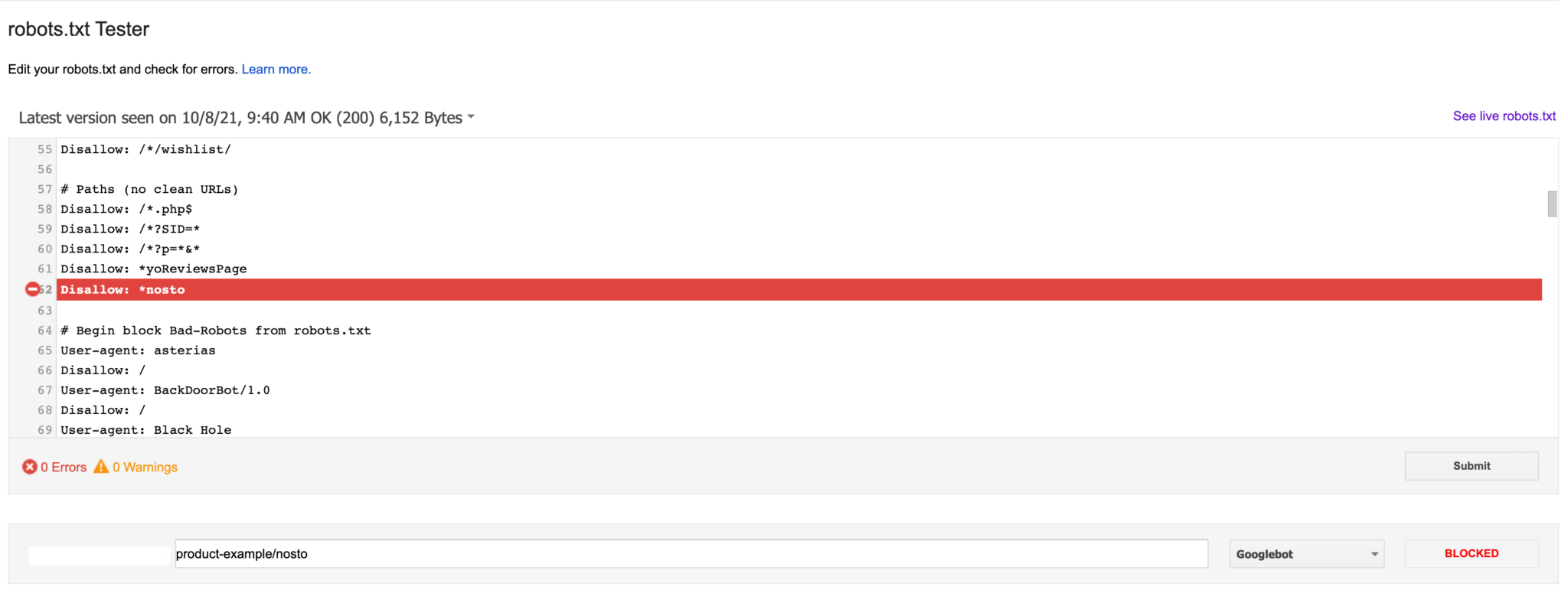
We recommend reviewing your robots.txt file within the Google Search Console robots.txt testing tool to see if this issue is blocking any key areas of your website, or if any of your pages not blocked by robots.txt are only internally linked to by pages that are blocked within the robots.txt, as then they will not be discovered by search engine crawlers:
Alternatively, you can use the Bing Webmaster Tools robots.txt tester:
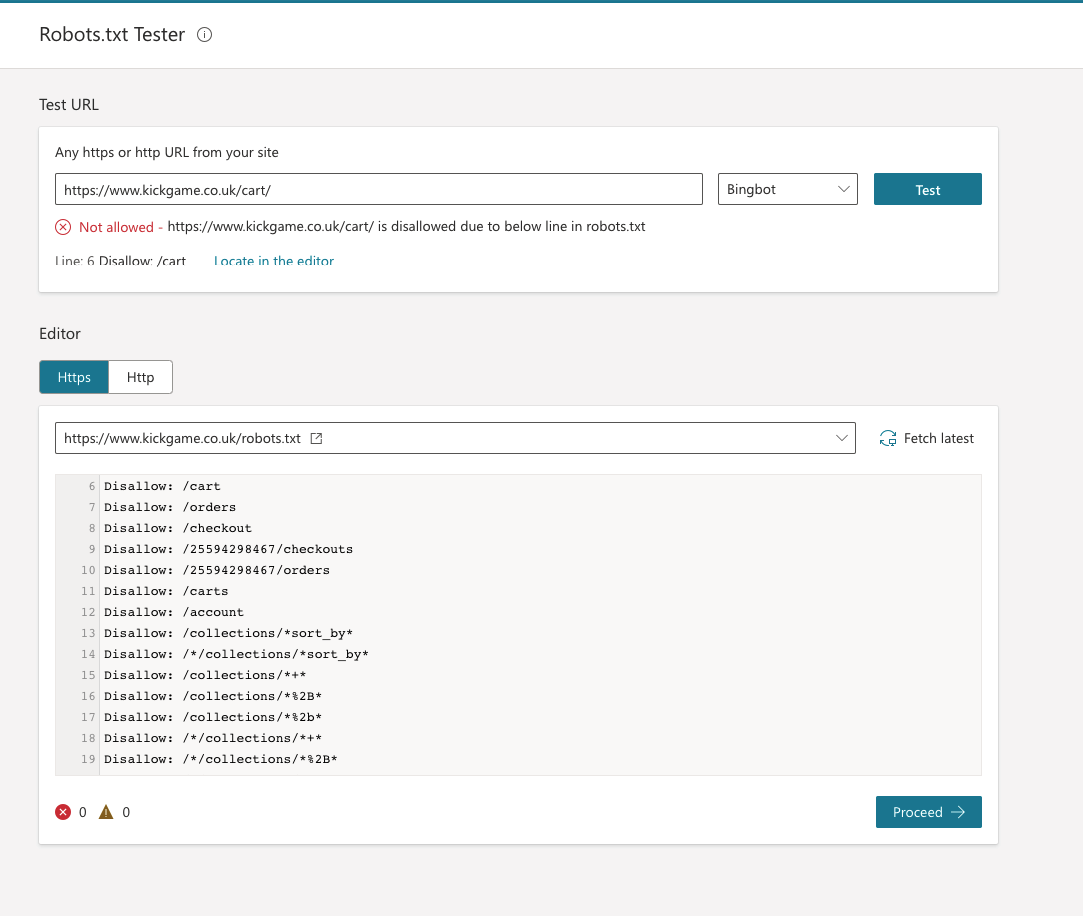
We recommend auditing the URLs blocked within robots.txt to determine what should and should not be blocked and make sure you aren’t inadvertently blocking any key pages or directories from being crawled by search engines. You can use Lumar’s robots.txt overwrite feature to test how your robots.txt file might be affecting how your site is crawled, then update your robots.txt accordingly.
We also recommend double-checking which crawlers are being blocked within your robots.txt file, as certain CMS will block some crawlers by default.
Crawlability Issue #2: JavaScript links / dynamically inserted links
JavaScript links can be a big issue for many websites and, depending on whether you are struggling to crawl the site yourself or if search engines are struggling to crawl your site, these JavaScript issues could be what is impeding your progress.
If your site is JavaScript-heavy, it’s worth confirming that your site is running on Server-Side Rendering (SSR), and not Client Side Rendering (CSR). Search engines are unable to properly crawl your site if it is fully CSR and must render before the search engines can crawl the site. This is very resource-intensive, so it may stop the whole site from being regularly crawled and updated. Shopify sites utilising JavaScript apps to load in products can be problematic, as it means that search engines aren’t able to properly crawl your product URLs and assign value to them.
If you are a fast-moving e-commerce site with products coming in and out of stock regularly and want this to be reflected in your organic search engine results, we’d recommend ensuring that you have Server-Side Rendering enabled for JavaScript-heavy pages. We also recommend ensuring that your XML sitemap is up to date, so even if search engines are slowly rendering your pages, they will have a full list of URLs to crawl through.
A fantastic Chrome plugin for testing the difference between your rendered and unrendered pages is View Rendered Source.
Crawlability Issue #3: URLs blocked in webmaster tools
Although often overlooked, some URLs can actually be blocked from within your webmaster tools.
Bing Webmaster has its own URL blocking tool, so it’s worth double-checking that you haven’t blocked any integral URLs from this list. Similarly, the Google Search Console URL Parameter tool should be reviewed to ensure you aren’t actively directing search engine robots to not crawl any areas of your site that are key to your organic success:

Crawlability Issue #4: Broken or nofollowed navigation links
One of the more obvious issues, perhaps, would be navigation links that are broken or nofollowed. This will affect how search engines and crawlers understand your website.
Search engines primarily discover URLs via internal links, so if a link is nofollowed or broken (5xx server errors or 4xx error codes), then search engine crawlers will not follow that link to discover the additional pages. This is particularly important within the website’s primary navigation, as these pages will be the first port of call for search engines to discover more of your URLs.
Running a crawl on your website with Lumar can help to identify these errors and help your team and address them to prevent further crawlability issues. Without a tool like Lumar, it’s a manual job of reviewing each link within the HTML, determining whether it has a ‘nofollow’ status, and then reviewing the status code of the individual URL by visiting it and utilizing chrome plugins such as Redirect Path. For a site with hundreds or thousands of URLs within its navigation, we’d strongly recommend running this through a crawler tool to save time and effort.
If your site is struggling to be crawled by a crawling tool (like Lumar), you can also try changing your user agent, as some sites might be set to block crawlers outside of regular search engine crawlers. Sometimes, fixing crawlability issues can be as simple as that!
Crawlability Issue #5: Noindex tags
Common blockers preventing your site from being crawled and indexed are often as simple as a meta tag. More often than not, when our clients are unable to get traction to a certain area of their site, it’s due to the presence of a meta name=”robots” content =”noindex” tag (within the HTTP header).
This can be confirmed by looking in Google Search Console’s URL inspection tool:
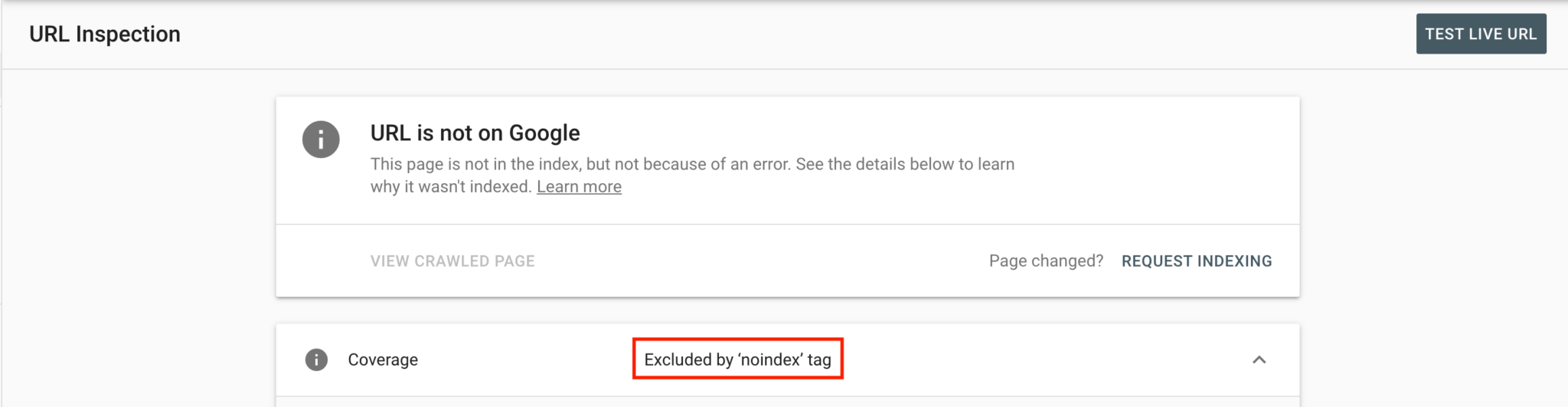
These tag issues can be resolved by removing the noindex tag from the URLs in question, if required, or by removing the X-Robots-Tag: noindex from the HTTP header. Depending on your CMS, there might be a simple tick box that has been missed!
It’s worth noting that John Mueller, the Senior Webmaster Trends Analyst at Google, stated in this office-hours webmasters hangout that long-term noindex and follow links are treated the same as nofollow noindex links, so if you have a link on a noindex page it will eventually be nofollowed by Google. Eventually, this issue can become a problem for crawling, but it is mostly an issue with indexing.



