

Canonical Tags are an Essential Part of Every Site’s Architecture: Here’s Why
Canonical tags are a powerful way to tell Google and other search engines which URLs you want them to index.
They can prevent duplicate content issues if you have different versions of the same page: for example, an original and print version of the same page, session IDs or color variations of the same product.
What is a canonical URL?
The canonical URL is the primary version of your content. It is the URL that you want to appear in Google’s search results.
The full set of canonical URLs on your site are created using a set of rules to ensure they are consistent. For example, you might decide that your canonical URLs should always end with trailing slash. Or you might decide the canonical URLs should not include any URL parameters.
What is a canonicalized URL?
A canonicalized URL is a page with a canonical tag and a different URL inside its canonical tag (the canonical URL).
By including a different URL in the canonical tag on a page, you are instructing Google to index the canonical URL instead of the page’s URL.
Authority signals collected on the canonicalized URLs are also consolidated to favor the canonical URL.
Where and how do I add a canonical tag?
Insert the following tag into the page you want to canonicalize.
<link rel=”canonical” href=”https://www.example.com/a-different-page” />
Alternatively, you can include them in the HTTP headers.
Link: <https://www.example.com/a-different-page>; rel=”canonical”
Adding canonical tags: the rules
In order for canonical tags to work properly, they must be used correctly and consistently:
-
Use absolute URLs, including the full domain.
-
Be consistent in whether you use a slash or no slash at the end of the URL.
-
Don’t mix your cases: use upper case characters consistently, or don’t use them at all.
- Use Google Webmaster Tools to specify how Google should handle parameters
and exclude those that don’t return unique content. Strip all the same parameters from your canonical URLs. -
Use character codes (ampersands etc) consistently, or don’t use them at all.
What’s the difference between canonicals and 301 redirects?
A canonical tag is only visible to search engines so it allows the user to remain on the URL, whereas a 301 will redirect users and search engines.
A redirected URL won’t be stored in your analytics, whereas a canonicalized URL will be tracked.
If you want a URL to be accessible to users then you should use canonical tags, otherwise you can redirect.
What can go wrong with canonical tags?
Search engines will ignore your canonical tags in the following situations:
Content different on canonical and canonicalized URL:
Google may choose to ignore canonical tags if the canonical URL and the canonicalized URL are different.
Page missing a canonical tag:
All pages should contain a canonical tag to prevent any possible duplication, including on the canonical page.
Canonicalising to the wrong URL:
If the canonical URL is not similar enough to the canonicalized one, then Google will probably ignore it.
Multiple canonical tags:
If the canonical tags on the same page are different, then Google will ignore both.
Canonical loop:
A page canonicalizes to a page that canonicalizes back.
Unlinked canonical pages:
Most canonical URLs would probably be linked internally at least once because they are usually an important part of the site.
If a canonical URL is not linked directly it may indicate the canonical URL is wrong.
Redirecting canonical URL:
If the canonical URL redirects to another URL, then it can’t be a true canonical URL.
Broken canonical URL:
If the canonical URL isn’t a valid URL then Google will probably just ignore it but it will still waste time, which reduces crawling efficiency.
Empty canonical tag:
Canonical tag does not include a URL.
Using canonical tags for mobile
If you have a mobile website on separate URLs, Google recommends that you canonicalize your mobile site to your desktop site to complement a rel-alternate.
Canonical tags for pagination
If you have implemented pagination with a view-all page (typically used for articles broken up into many pages), then Google recommends canonicalizing all the paginated parts to the full version.
Keep track of your canonical tags with Lumar
Lumar’s three canonical tag reports will show you all of your canonicalized pages, pages without a canonical tag, and unlinked canonical pages.
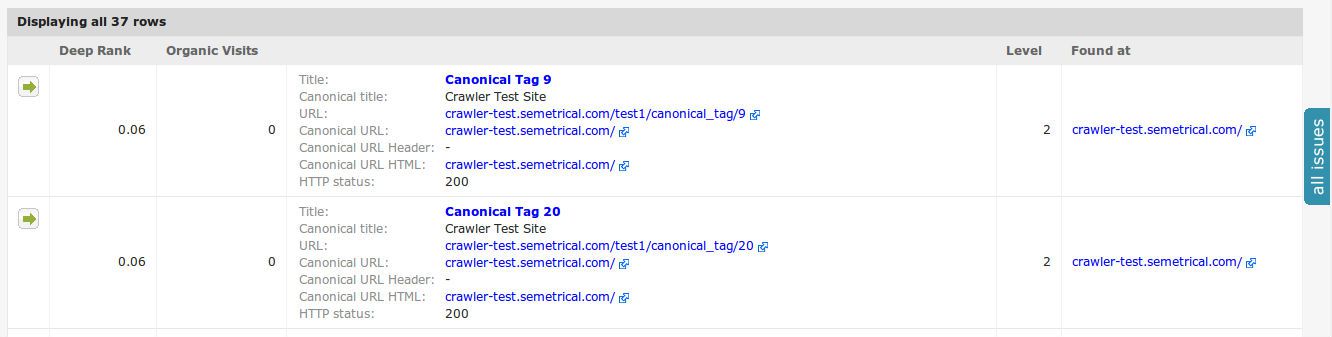
1. Find canonicalized pages
This report will find all pages with URLs that are different to the canonical URL specified in the canonical tag, in either the HTML or HTTP header.
Go to: Indexation > Canonicalized pages.
You will then see a list of all your canonicalized pages, plus their location and the canonical URL:
2. Identify pages without a canonical tag
Go to Validation > Pages without Canonical Tag
This view will show an at-a-glance view all of your pages that are missing a canonical tag.

3. Find unlinked canonical pages
Go to Validation > Unlinked Canonical Pages
Here you will find a list of all pages found in canonical tags that are not linked:

Lumar will always follow any canonical URL, so if any of these are broken then you can find them in the other error reports.



