

The rapid rise in malicious bots crawling the web have caused hosting companies, content delivery networks (CDN) and server admins to block bots they do not recognize in log file data. Unfortunately, this means that Lumar can be accidentally blocked by a client’s website.
In this guide, we will help you identify indicators that a crawl is being blocked and provide solutions to unblock Lumar and allow you to crawl your site.
How to identify that a crawl is being blocked
The most common indicators of a crawl being blocked are listed below.
Unauthorized and Forbidden crawl errors
If a server is blocking Lumar from accessing a website, then reports will display a lot of URLs with HTTP 401 unauthorized and 403 forbidden header responses.
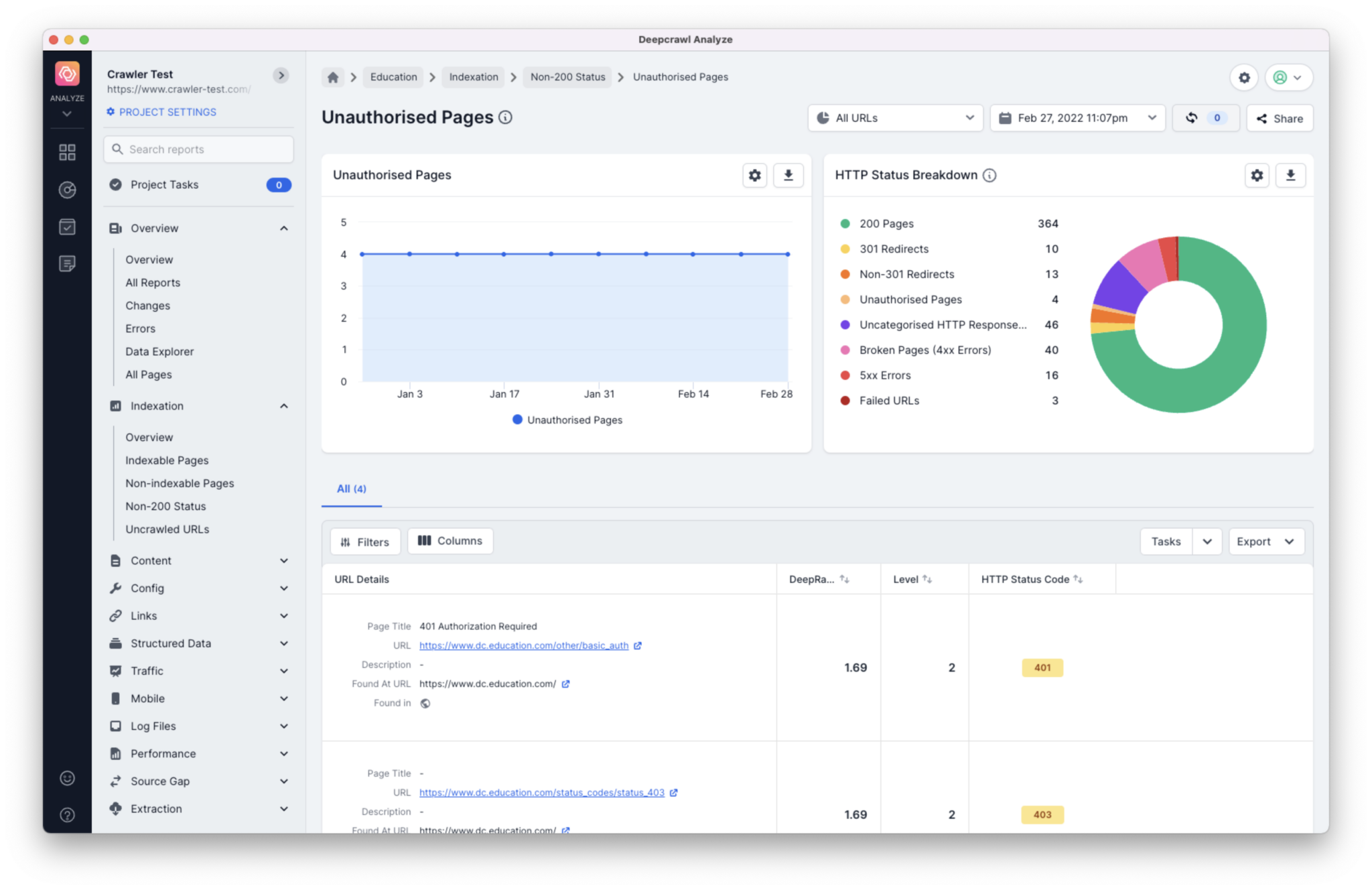
To find URLs with these errors navigate to the Unauthorized Pages report.
Too Many Requests
If Lumar is exceeding the number of requests your site is able to receive, then reports will display a lot of URLs with HTTP 429 Too Many Requests header responses.
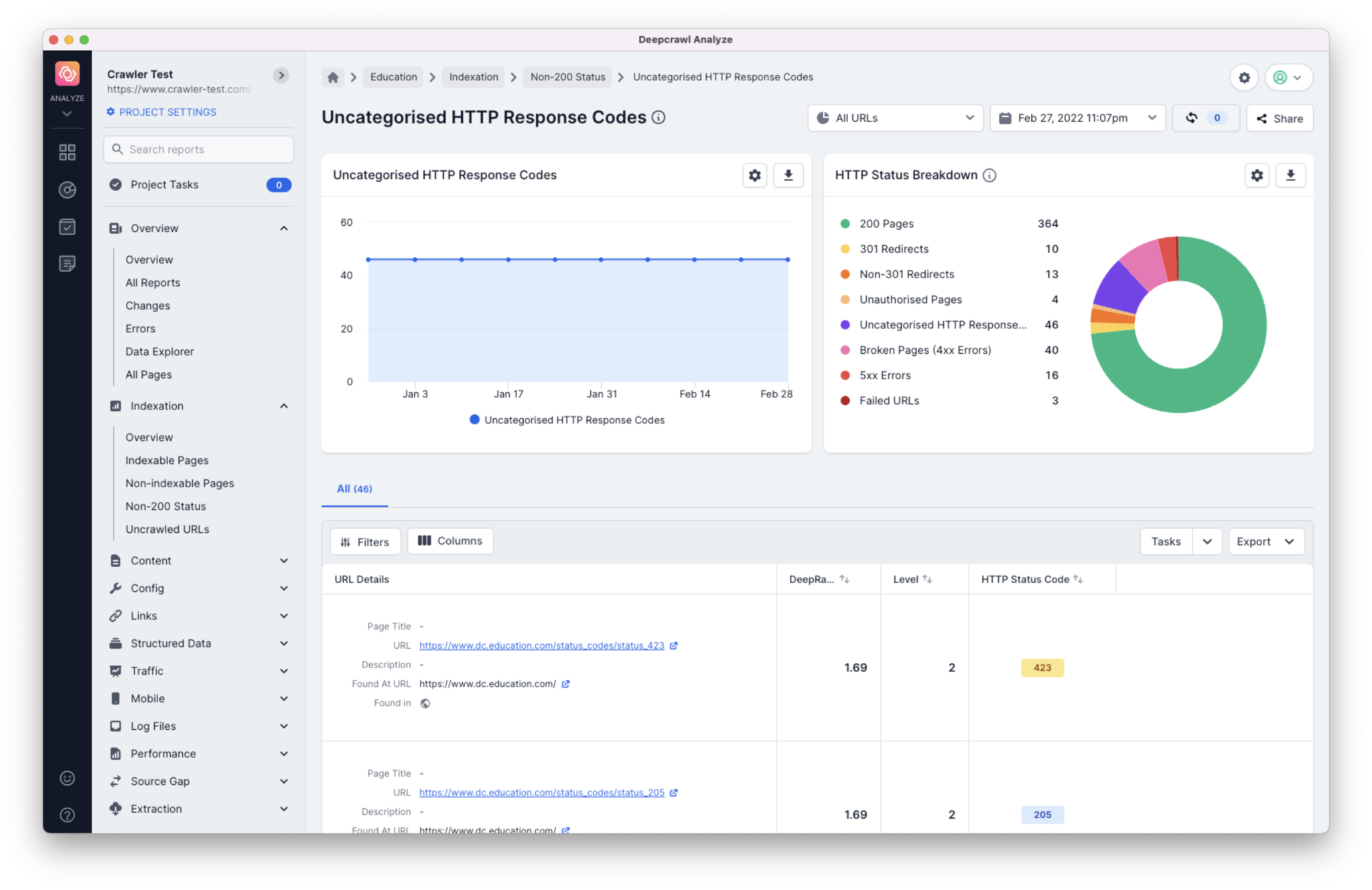
To find URLs with these errors navigate to the Uncategorized HTTP Response Codes report.
Slow crawl and connection timeout errors
This will cause your crawl to be successful initially but it will begin to slow down progressively and eventually appear to stop running completely.
Any URLs crawled and displayed in Lumar will show up with connection timeout errors in reports.
Why does Lumar get blocked?
The reason for your crawl being blocked is most likely due to one of the following:
- Lumar uses Amazon Web Services which may be blocked by default as they are also often used by scrapers.
- An automated system is in place on the server or CDN which detects and blocks suspicious activity. For example, if a certain number of requests exceed a set limit Cloudflare starts blocking requests.
- A manual block has been implemented by a server administrator, based on manual inspection of server activity, possibly triggered by a high load caused by the crawl, or a large number of crawl errors.
- The use of a Googlebot user agent having led to the failure of a reverse DNS lookup, appearing to be a scraper which is spoofing Googlebot.
How can I remove the block and crawl my website?
Our team recommends the following solutions if you suspect that Lumar is being blocked.
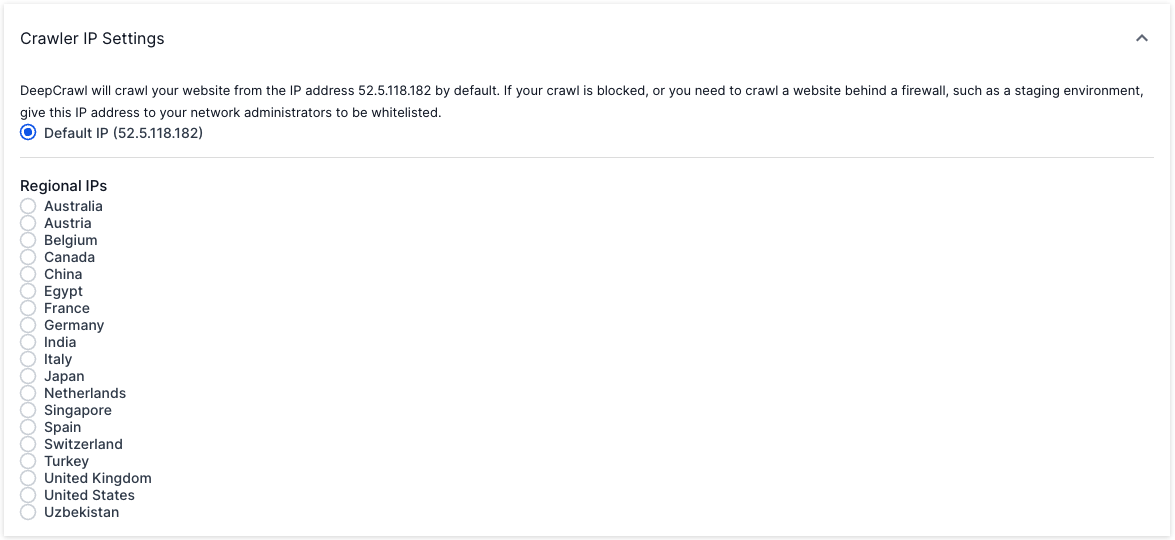
Whitelist our IP
Providing you know the site, you can ask server administrators to whitelist the IP addresses that Lumar uses to crawl. Please ensure they whitelist both 52.5.118.182 and 52.86.188.211.
Change user-agent in project settings
Some websites will block requests which come from a Googlebot user-agent (Lumar’s default user-agent) but do not originate from a Google IP address. In this scenario, selecting a different user agent in a crawl’s advanced project settings often makes the crawl succeed.

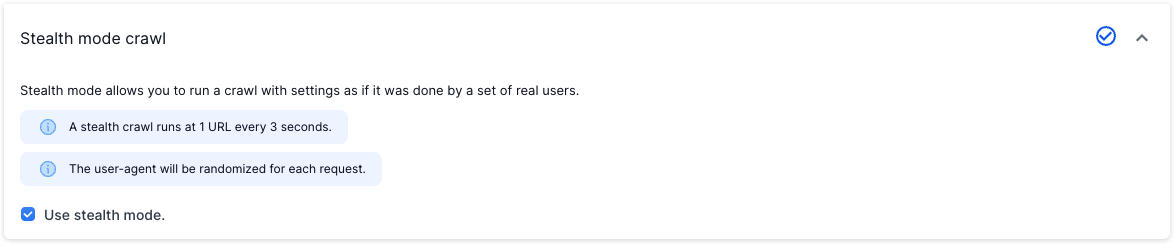
Stealth Mode
Use Lumar’s ‘Stealth Mode’ feature, which can be found in a crawl’s advanced project settings. Stealth mode crawls a website slowly using a large pool of IP addresses and user agents. This typically avoids many types of bot detection.
Enable JavaScript rendering
Certain websites attempt to use JavaScript to block crawlers that do not execute the page. This type of block can normally be circumvented by enabling our JavaScript Renderer.
Frequently asked questions
Do I need to implement more than one solution?
Although one solution can help unblock Lumar, sometimes it is necessary to try another method. For example, as well as whitelisting Lumar’s IP it might also require changing the user-agent of the project.
Why can I still not crawl my website?
If you still can’t crawl your website (after trying multiple solutions) then we recommend reading the how to fix failed website crawls guide for more tips to debug failed crawls.
How do I find out if my website is using a CDN?
If you are unsure whether a website is using a CDN then read the following guide on how to identify what CDN (if any) a website is using.
How can I identify Lumar in my log files?
Lumar will always identify itself by including ‘Lumar’ within the user agent string.
e.g. Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html) https://deepcrawl.com/bot
Any further questions?
If your crawls are still getting blocked, even with implementing the solutions suggested above, then please don’t hesitate to get in touch.



