
You may want to check or analyze a specific section of your website, instead of crawling your full site.
This can be useful after a new website channel addition, to filter out script based URLs and subdomains, or to ensure your URL credits are used for specific sections of a website.
It’s also handy for international websites, where you may only want to analyze a specific country.
You can restrict a crawl to any set of pages, using a mixture of inclusion and exclusion rules found in the Advanced Settings, in step 4 of the crawl setup.
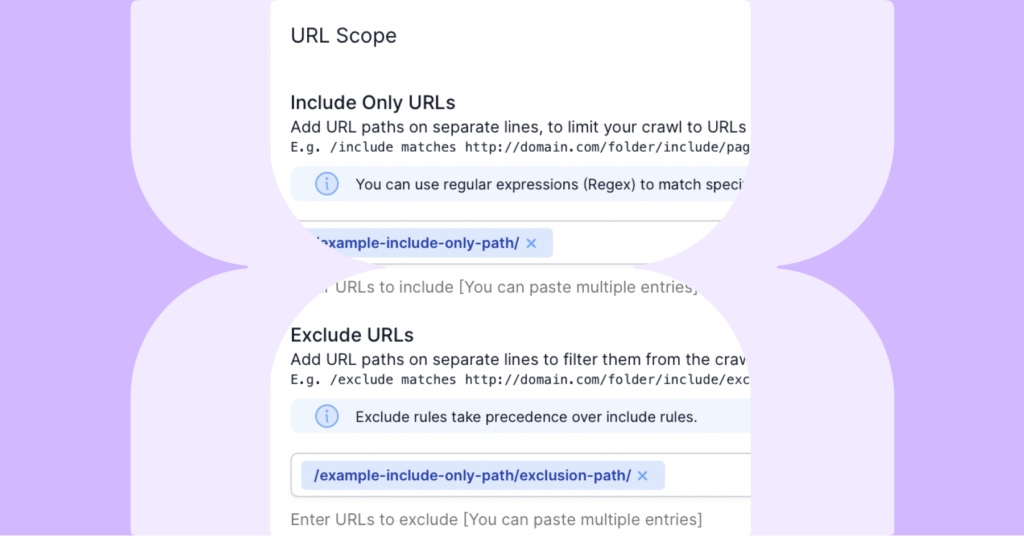
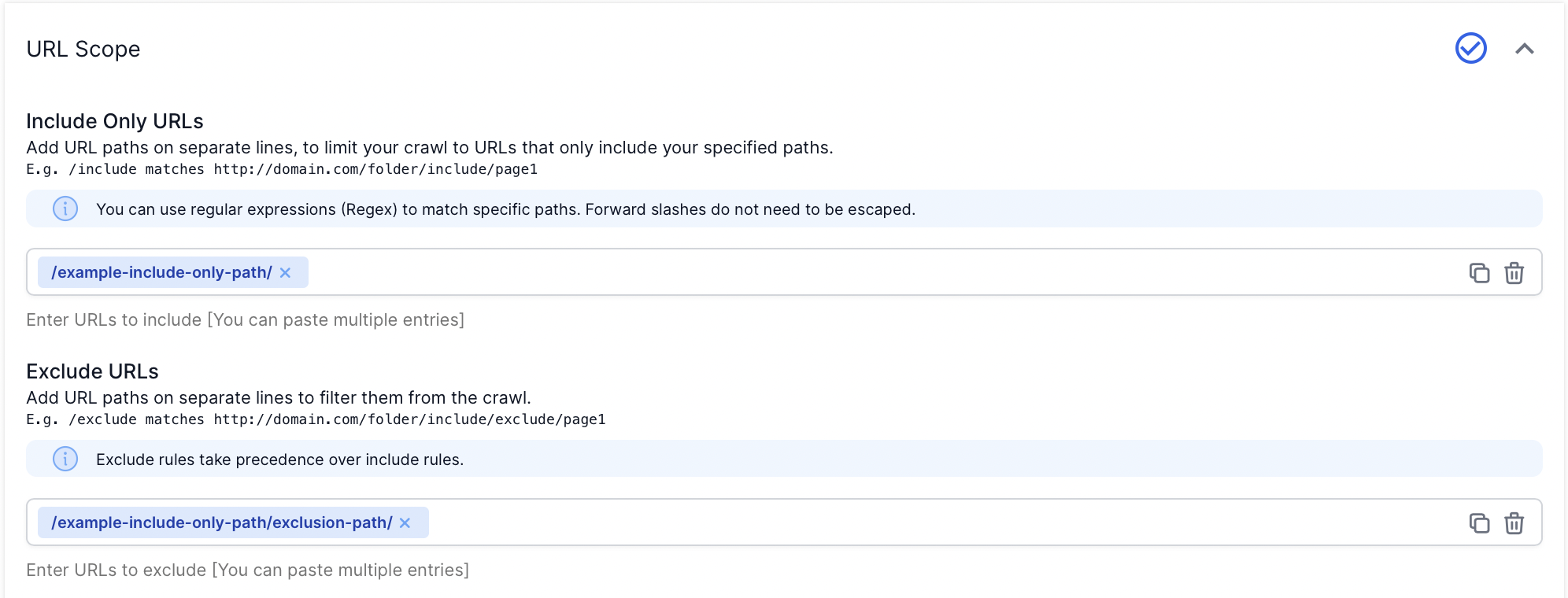
Included Only URLs (Positive Restriction)
Use the ‘Included Only URLs’ field in Advanced Settings to crawl a single path only.
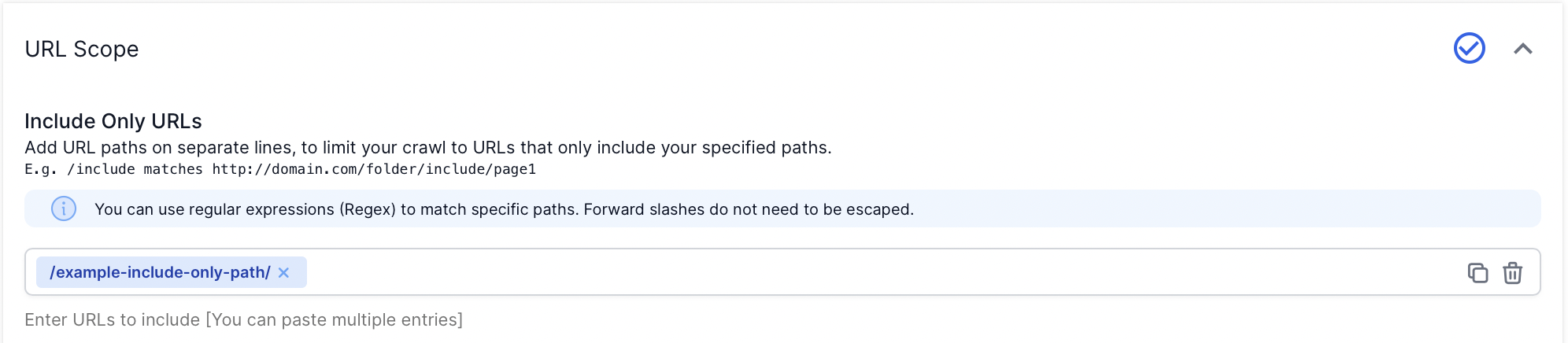
Add your URL paths on separate lines, to limit your crawl to URLs that only include your specified paths.
Please Note:
Regular expression matching syntax is used by default. Forward slashes do not need to be escaped.
Excluded URLs (Negative Restriction)
Use the ‘Excluded URLs’ field in Advanced Settings, to exclude pages or channels you don’t need to see in your reports.
The include/exclude filters also work on full URLs, including hostnames and protocols.
For example, here’s how you would prevent your HTTPS site from being crawled.

Please note:
Exclude rules will take precedence over include rules.
All matching rules use Ruby regular expressions, forward slashes don’t need to be escaped.
All paths automatically start and end with a wildcard, so no need to add it in.
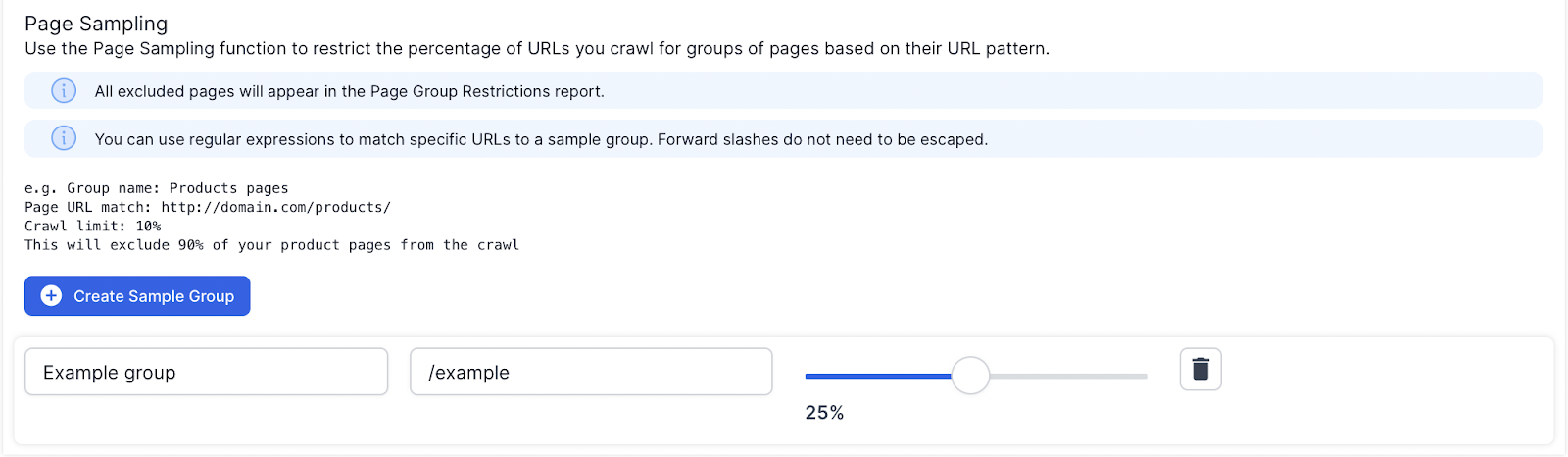
Page Sampling
The Page Sampling fields also enable you to limit the % of URLs crawled for groups of pages based on their URL patterns.
Add a name, a regular expression or directory and a maximum % of matching URLs to crawl.
Any URLs matching the group will be counted. When the limit is reached, any new matching URLs will not be crawled, but will be included in the Page Group Restricted URLs report.
e.g.