

Many of us are guilty of not getting the most out of our SEO tools, and, therefore, our data. This is especially true when you have an extensive toolset and a large workload. You may not have time to explore the capabilities of certain tools, and may fall into the habit of using a few select reports from each one; getting into a strict routine for monitoring your site’s performance.
Your tool checking routine may feel time-efficient, but you may find that you are only skimming the surface with the tools that you pay for and their capabilities. This can be true for DeepCrawl (now Lumar). Our crawler is so much more than a dashboard where standard crawls are scheduled and observed for changes every now and again.
What is Custom Extraction & Why is it so Useful?
One of the best ways of making an SEO tool, particularly a website crawler, work for you is through utilising custom extraction. This feature allows you to get right to the heart of your website and scrape the most important information from the HTML that will be most useful. Custom extraction sifts through the mass of code on your site and returns the data you want in a neat, orderly manner. When you know how to use this feature, DeepCrawl (now Lumar) becomes far more flexible and produces more granular data.

We already provide a high level of detail on site health and performance in our reports, but if you’d like to go beyond our reports and uncover even more detail about your site, then a line of regex may be all you need. Custom extraction is something that needs to be tailored to the requirements of each site so we can’t provide a blanket service that suits everyone for this, but working out the strings of regex that work best for your site will be well worth it.
What is Regex?
If you’re not entirely familiar with what regex actually is and does, it stands for regular expression and is a means of creating a search pattern. You use a regex string in order to match and locate certain sections of your website’s code. Regex can basically be used as a much more sophisticated Ctrl+F (or Cmd+F) function!
As well as being used for extraction, regex also has many other use cases within DeepCrawl such as matching URLs for inclusion and exclusion within crawls. Google Analytics also support regex matches, which is a very powerful way to filter reports within the tool.
There are many different regular expression languages, but at DeepCrawl we use Ruby.
The search patterns you create can be teamed up with SEO tools which present the snippets of code you find in a meaningful, digestible way. If you create a custom extraction query using regex within DeepCrawl to search for product prices that are coded into your site, for example, then you’ll get a handy list of pages with their prices listed for you.
How to Use Regex
Before we dive into our list of recommended custom extraction use cases, it’s worth having a refresher course on using regex. Understanding and writing regex can be quite daunting at first, but once you’ve got the basics of the different characters and their functions then you’ll get to grips with it in no time. Take a look at this guide on the basics of regular expression to get started.
The key to using regex correctly is establishing patterns that appear within your source code. Every website is coded differently, so there will never be a ‘one size fits all’ guide to custom extraction. The only universal strings are the ones that will always appear in the same way on any website, such as the Google Analytics code tag.
The best way to identify the patterns of code that are unique to your site is to get some examples of each of the templates, ‘Inspect’ element or open ‘View Page Source’ and dive in!
Rubular is a great tool for trying and testing the regex strings you create off the back of the findings from your template analysis. This tool also supports Ruby testing so it’s perfect for trialling anything you want to include in within DeepCrawl.
Custom Extraction Use Cases
There are so many great things you can do with custom extraction. We want to make sure everyone gets the most out of DeepCrawl, so we’ve put together a list of examples that we recommend to further explore your site’s technical health. So let’s shed some light on the data you could be finding within your crawls.

Here are the custom extraction use case examples we’ll be exploring:
Log into your DeepCrawl account or sign up for an account, then create a project to try out these examples for your own site. You can configure custom extractions within the advanced settings in the 4th step of the crawl setup section.
If you get stuck writing your own regex then we will be happy to assist you, just get in touch and let us know what you need!
To give an example of the process around creating a custom extraction which will give you an idea of how to create regex strings for the other examples mentioned below, we’ll walk you through exactly how to write a regex string to help you identify soft 404 errors on your site.
Soft 404 Errors
DeepCrawl reports on the status codes it comes across when you run a website crawl. However, custom extraction is a way of going beyond the server responses and digging into the detail of what your pages are showing when they are being accessed by users and search engines alike.
An example of needing further exploration is in the case of soft 404 errors. This occurs when a page cannot be found or the page’s copy indicates there is no content, but the server responds with a 200 ‘OK’ status code.
For common, on-page error messages such as “The page you requested could not be found.”, the HTML markup might look something like:
<div class=”error-msg”>The page you requested could not be found.</div>
This simple regex can be used to capture the complete message, without the HTML:
>([^<]*?could not be found[^<]*)<
Here’s how it works:
- The first two characters, ‘>(’, look for the opening bracket of an HTML tag such as <span> or <div>, then starts capturing from there.
- ‘[^<]*?’ captures 0 or more characters that are not an opening bracket of an HTML tag. In other words, any text that may precede the target string.
- ‘could not be found’ looks for that specific target string.
- ‘[^<]*)<’ continues to capture any remaining text that follows the target string, until the next closing bracket is encountered.
If the site displays various different error messages such as “That URL no longer exists” or “Item is currently out of stock”, you can simply add additional target strings, each separated using the “|” symbol and alternative target strings enclosed between ‘(?:’ and ‘)”, which is a non-capturing group:
>([^<]*?(?:could not be found|no longer exists|out of stock)[^<]*)<
Obviously, there are many possibilities, even with variations in writing styles. For example, rather than saying “could not be found”, what if a site uses contractions and says “couldn’t be found”? For that matter, what about “can’t be found”, “cannot be found”, or even “can not be found”? With some creative regex, you can detect all of the above variations using syntax such as this:
>([^<]*?(?:(?:can|could) ?(?:’t|n’t|not) be found|no longer exists|out of stock)[^<]*)<
Breaking down the first target string of “(?:can|could) ?(?:’t|n’t|not) be found”:
- ‘(?:can|could)’ – finds either word, “can” or “could”.
- ‘ ?’ – looks for an optional space character.
- ‘(?:’t|n’t|not)’ – the next characters must be either “’t” or “n’t” or “not”.
- ‘ be found’ – follow the above matches with the exact string of “ be found”.
If you really need to cover your bases, don’t forget that certain characters are sometimes encoded as HTML entities. This means that a character such as a single quotation mark (apostrophe) might be represented internally as “'”, so you might want to allow for that (hint: step 3 above would become “(?:’t|n’t|'t|n't|not)”).
Now you have a solid understanding of how regex and custom extraction works, let’s look at further possibilities of how you can be utilising them and the insights you could be gaining for your site.
Ecommerce Product Information
With what can seem like countless numbers of products and various teams having access to the CMS, it might feel like it’s impossible to keep track of your site’s ever-changing ecommerce product data. To help build a more accurate picture of the products on your website in an automated way, you can use custom extraction to scrape the data you really need. The best way to do so is to look at a few product pages and their metadata or schema layout as examples to find wider patterns of code.
For example, on a particular product page when you click ‘Inspect’ on a particular element or when you look in the source code, you can zero in on the code you need to work into the regex string you want to create.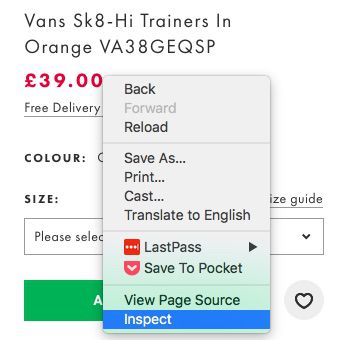

Here are some examples of the details you can collect from your products.
Product Stock Status
One of the most frustrating things that a user can come across during the customer journey is an out of stock product page.

With custom extraction, you can track the volume of out of stock products on your site as well as the URLs where they are found so you know which ones to leave out of your offsite promotions. By integrating with Google Search Console and Google Analytics data you can even map impressions and visits to see which of these are landing on out of stock products.

When you use a crawler to help you keep tabs on your discontinued product pages, you can even find orphaned pages that aren’t internally linked to anymore. The data gathered can help you assess your current approach to handling out of stock products, such as using redirects, noindex or adding a section to the page which features relevant products which are available.
Category Page Product Counts
Thin content category pages are a common issue for ecommerce sites; this is unavoidable considering the changing nature of stock statuses. An ecommerce category page is only as strong as its product offering, and all it takes is a handful of products to sell out or be removed from the site due to seasonality for a category page to be left looking very bare.
You can use custom extraction to monitor the number of empty category pages on your site, as well as the current behaviours around dealing with these pages – whether they’re noindexed or redirected, for example.
Additional Product Details
This is a selection of some of the other product details you can pull using custom extraction:
- Product Price
- Product Serial Numbers / SKUs
- Category Codes
- Product Dimensions & Sizes
- Delivery Estimates
Content
Whether you need to extract data from your articles to help you compile a content audit, or if you need to update certain sections of your content, regex is a great way to scrape the text you want from the pages across your site.
Combining the data collected from multiple custom extractions helps you to collect more useful data for auditing purposes. For example, if you gather data on the sections or categories your content sits in as well as the authors, and then combine this view with other data sources such as Google Analytics to see traffic metrics, you can pivot all this data together to see the success of content. This is just scraping the surface of how custom extraction can be used for content management and analysis.
Wording & Phrasing
With custom extraction you can locate instances where particular words and CTAs are that need updating, such as “Black Friday 2017”, for example. In the same way you can also update brand tone of voice across the site by locating pages which feature certain words in your old brand tone of voice document to be updated, or even find misspellings of your brand name.
You don’t even need to just find particular instances of text, you can extract entire sections of text if you wanted to analyse your content in its fuller form. We do provide detailed reporting on duplicated and missing content though, if you wanted to do any wider content analysis.
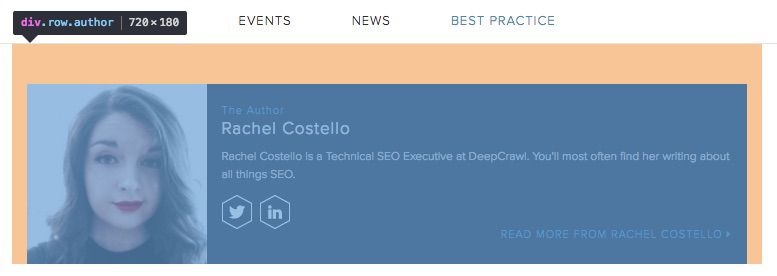
Author Bylines
Custom extraction can be used to find author bylines to keep track of which pieces of content were produced by which writer. You can compare how many pieces of content have been produced by the different content writers within your team, and you can also overlay data from other sources such as Google Analytics traffic data to see which writers are producing the most engaging, highest performing content.
Content Categories
You can use custom extraction to pull the categorisation of your content, whether you differentiate posts by tags or by category subfolders underneath your blog’s URL, for example. By extracting this information you can measure the volumes of articles being published within each of the categories and assess the highest performing content categories you have on your site by integrating analytics and search behaviour data from other tools. You can also combine this information with published dates to effectively map out content production and consumption trends.
Published Dates
If you want to get an idea of article publishing volumes over time, custom extraction can be used to pull out an article’s published date. This data can be used to map out the seasonality of your content, and can be combined with Google Analytics traffic metrics to look at reader engagement over time as well.
Last Updated Dates
Last updated dates are useful for highlighting pages which are due for a content refresh, such as old evergreen articles which are driving traffic but haven’t been touched in a while. You can also use the last updated date and overlay this with traffic metrics to find old pages that aren’t benefiting your site.
There are two different ways to use custom extraction to get the last updated date of a page. On news sites, last update dates are sometimes manually added in when an article has been updated with a quote or comment from different source. In this instance you’d write a string to find the text pattern before the date, whether this is “Last updated:”, “Revised on” etc. On the other hand, the last published date may be automatically generated by the CMS, so in this case you’d click ‘Inspect’ on the date to find the string of code you need to write your regex around.
Contact Details
You might need to scrape contact details from a site for a number of different reasons. You may have a large number of physical shop locations and corresponding pages which list their individual contact details, and need to check through the entire list to make sure they’re accurate perhaps. Instead, you may be doing some influencer research by analysing the sites of your blogger circle and want to find their contact details in order to update your outreach lists, for example.
Images
Image search can be a powerful source of search traffic to tap into, but this can only be properly utilised if your images are optimised in the correct way. Using custom extraction allows you to zero in on the images on your site and run image audits in an automated way.
Image Alt Tags
Search engines use image alt tags to try and better understand an image, and therefore when it is relevant to show it in image search results. This means that having an idea of image alt tags is fundamental for making sure a site is optimised to bring in traffic through image search. Conveniently, we already provide ‘Missing Image Alt Tags’ as a preset custom extraction which is ready to be used, with no work to write any regex on your end!
Image Sizes
Custom extraction can help you find images with specific dimensions, such as banners or header images. This is useful for when you are updating campaign messaging which you have added to banner images, or if a page template style has been updated which makes current images of a certain size not fit correctly anymore.
For ecommerce sites, product images usually need to be uploaded in a consistent size so by writing a regex string to find images with this specific information, you’re able to compile a list of all your product images and combine this with other custom extractions such as finding alt tags.
Markup
Markup and structured data have so many benefits, including feeding into the creation of rich snippets which make your SERP snippets stand out from the competition, informing answer boxes and voice search results, and helping Google have a better understanding of your website. With all these things considered, it’s vital to have an overview of the markup on your site so you can check it has been implemented correctly. in order to best take advantage of Google’s SERPs.
With custom extraction you can identify which pages have been marked up, and you can even pull the information that has been marked up, so you can see the different properties you have as well as the different types that you’ve categorised the properties into.
Schema
You can find a list of the different schemas here, where you’ll be able to find the correct structure for organization schema, product schema and more. In these guides you’ll be able to see the official wording of the different properties which will help you build your regex query. For example, if you’re looking to examine the different product brands, you know you’ll need to extract the code around the “brand” property.
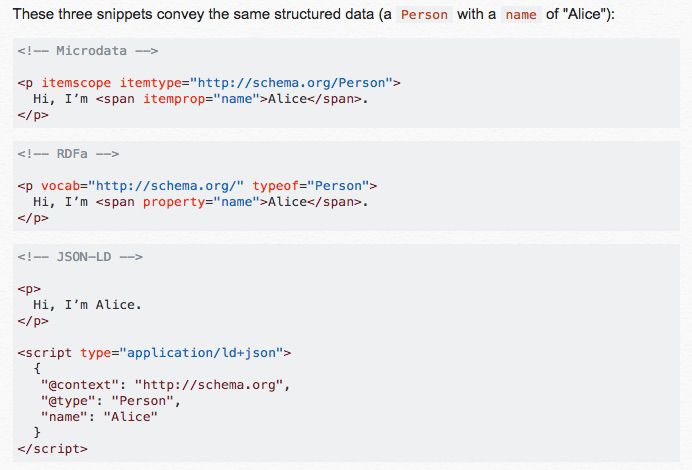
It’s worth bearing in mind that schema can be added to a site in different ways, such as with microdata or JSON-LD, as demonstrated below. Be sure to check the source code of your site and see how your website’s schema is being implemented, as this will affect the regex string you need to create.
Breadcrumbs
They may fundamentally seem like a way of helping users navigate your site, but you can glean many interesting insights from the breadcrumbs on your site. They will feed into any website taxonomy analysis you want to perform, as well as helping to you split your site into distinct sections so you can perform audits at scale.
Ideally, you should markup breadcrumbs. If you do so using Schema.org guidelines you’ll know to find the defined properties such as “itemListElement” to include in your regex query.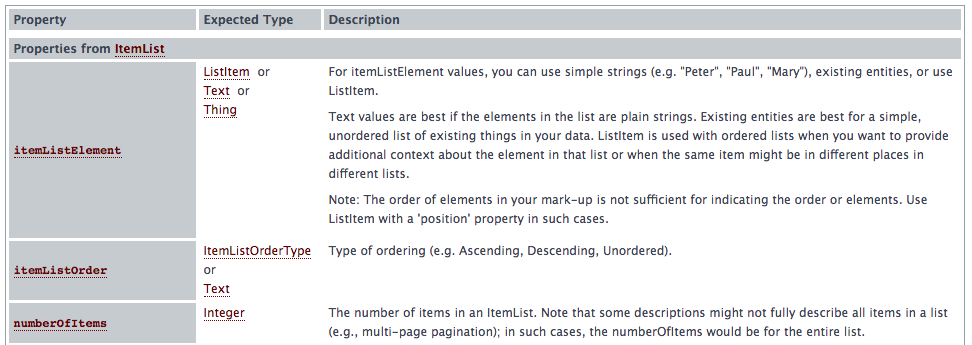
Reviews
Custom extraction can be used to pull out review schema so you can assess individual or aggregate reviews, in order to get a better understanding of the popularity of your products. With this view you’ll be able to cross-reference products that you know are best-selling but don’t have any reviews, or products getting poor reviews so you can assess which areas of your site’s offering need improving.
You can use schema.org to find product markup guidelines. If you’re looking to collect the different review ratings for each of your products, you know you’ll need to extract the code for the “reviewRating” property, for example.
Tracking & Event Tags
Having tracking and event codes on your site provides invaluable insights into conversion behaviour and allows for user experience testing. If you’re running crucial tests or monitoring which will tell you the best way you should be serving your customers with your onsite experiences, then it is vital to make sure the codes and tags you’ve implemented are actually in place and working correctly.
Some of these tags are added into the HTML manually, however, some of them are injected using JavaScript. This means you will need to use rendered crawling in order for custom extraction to work this way.
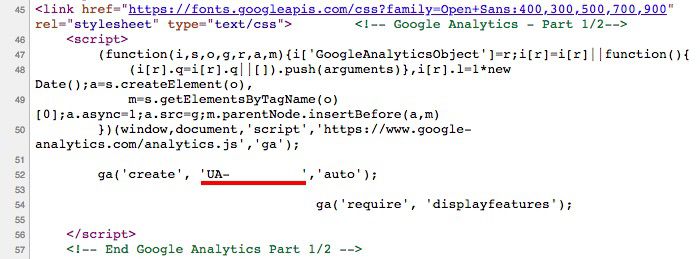
Google Analytics Code
Google Analytics (GA) tracking is so common on sites that we have it included as one of our preset custom extraction rules. By running a full site crawl with this enabled, you can make sure your unique GA code is present on every single page so you can rest assured that your website traffic and customer onsite browsing behaviour is being tracked.![]()
Event Tracking
You can use custom extraction for Google Analytics analysis beyond just making sure the UA code is there. It can also be used to extract GA events that you may be tracking on your site and check that they have been implemented correctly, such as newsletter sign ups, contact us form submissions, etc.
Google Tag Manager
With custom extraction, you can check your Google Tag Manager implementation across your site. This is also one of our preset custom extraction rules so it is very straightforward to set up for your next crawl.![]()
Omniture Tags
Not everyone focuses on Google Analytics tracking, so we are open to any and all tracking solutions that you use. You can use custom extraction to check that your Omniture tracking tags are correctly in place.
Things to Remember
The key to using custom extraction in the best possible way is to test it on a few pages to make sure you’re getting the results you want first. After you’ve done that you can scale up and run a full crawl using the regex you’ve set up.
Custom extraction is incredibly useful. However, something to bear in mind is that you can get false positives when extracting certain text or information. For example, you’ll need to be conscious of any user-generated content on your site such as comments and reviews where customers may be quoting certain prices or messaging they’ve received on other pages, like your soft 404 error message.
We can achieve so much with data, but it’s important to do your own spot checks and validation of the data you collect to make the most meaningful conclusions.
Have you seen something in this list that you’re dying to try out in your next crawl, but aren’t fully comfortable with regex? Get in touch and we’ll be happy to help you write the best custom extraction string that suits your website, as well as answering any questions you have around this feature.
How do you use custom extraction within DeepCrawl and your other SEO tools? Do you have your own hacks or tips? Tweet us about them, we’d love to know!
Changes to Our System
You may have noticed that we’ve updated our reporting system for faster data handling than ever. With this update we’ve made some changes to the way our crawler handles regex. For more information on this, take a look at our guide.
The above custom extraction examples are just some of the ways you can use regex to dig deeper into the health and setup of your site. Try out DeepCrawl (now Lumar) for yourself, we have a flexible range of packages tailored to suit your needs.



