


Knowledge, networking and the all-important conference swag were in abundance for this September’s edition of BrightonSEO. It’s always fantastic to have so many so many SEOs all in one place sharing their experiences and advice, and the DeepCrawl team always learns so much from being there.
So grateful to have attended #brightonseo! My mind is ticking with #seo ideas, I met some incredible people, and just spent the day with a huge smile on my face. And, I can’t say I’m not pleased with all the awesome swag. Well done to all the speakers and organisers! pic.twitter.com/zAgK3eAeE8
— WordsUntangled (@WordsUntangled) September 15, 2019
We’ve already kicked things off with part 1 of our September 2019 BrightonSEO recap, but there were so many great talks during the course of the day that one post just won’t cut it.
My day was spent tracking down all the technical SEO talks I could find, and part 2 of our recap includes the key takeaways from talks by Roxana Stingu, Serena Pearson, Ashley Berman Hale, Fili Wiese, Jan-Willem Bobbink, Jamie Alberico, Rory Truesdale, Dan Taylor and Aysun Akarsu.
Roxana Stingu – How I learned to stop worrying and love the .htaccess file
Talk summary
Roxana from Alamy explained why SEOs don’t need to be afraid of the .htaccess file, and how it can be used to simplify and automate some of our day-to-day tasks such as implementing redirects and site migrations.
Key takeaways
The importance of the .htaccess file for SEOs
The .htaccess file isn’t as complicated as you may think, so there’s no need to be afraid of it. You don’t have to be a developer to be able to use it.
By using the .htaccess file, SEOs are able to simplify and automate a lot of their day-to-day tasks. Just by adding simple mod rewrites, you are able to implement a number of different changes on the server. The .htaccess file can help with crawling, indexing, improving page speed, and much more.
You can add more complex rules in your .htaccess file than you might be able to implement within a CMS, which can help you be more efficient. For example, you can use no case flags in a redirect rule to apply to both the upper and lower case version of a URL, so you have one rule rather than separate ones for each version.
Using the .htaccess file for SEO tasks
Here are some examples of the different SEO tasks that can be performed by using the .htaccess file:
- Implementing redirects
- Domain migrations
- Subdomain to folder migrations
- Changing folder names
- Modifying HTTP headers
- Adding canonical tags
- Implementing gzip compression modules
How the .htaccess file works
.htaccess stands for hypertext access, and allows you to write specific rules for specific folders on your server. .htaccess files use directives in a similar manner to a robots.txt file, and their rules are executed in order from top to bottom.
Regex is used to implement and shorten rules, so make sure you brush up on this with our introductory guide to regex.
Curious how many .htaccess records before performance degradation? @RoxanaStingu‘s got you #BrightonSEO pic.twitter.com/aSjI1ScY0Q
— Jamie Alberico (@Jammer_Volts) September 13, 2019
Things to bear in mind
Unlike the httpd.conf file which only loads once with every server restart, the .htaccess file loads with every request. This reduces the risks that come with restarting the server, which is especially useful for sites on a shared host or sites that need to make frequent changes. However, the server needs to take time to go through the file and test all the rules every time for each request, which can increase TTFB.
Make sure you go into your .htaccess file and check that all the rules are up-to-date and necessary and that they apply to final destination URLs, as this will help conserve crawl budget and reduce server response time.
It’s important to remember to always keep a backup of your file for any changes you want to make to it, as even a small syntax error can result in a server malfunction.
Learn more about the .htaccess file
To learn more about this topic, Roxana recommended going away and reading Daniel Morell’s useful guide to .htaccess for SEO. As a developer, Daniel has covered some of the key things that both developers and SEOs should know about bridging the knowledge gap around using the .htaccess file.
Serena Pearson – Don’t F*ck Up Your Site Migration
Talk summary
Serena from Kaizen walked us through her experiences with site migrations and shared her tried-and-tested tips on pre-migration checklists, auditing processes, performance benchmarking, and much more.
Key takeaways
Important pre-migration considerations
Before undertaking any migration work, you need to understand the purpose of the migration itself from the offset. For example, are you doing a rebrand? Are you targeting new markets? This information will help you focus your efforts more effectively.
You should have a thorough pre-migration checklist which includes the following:
- Review the staging environment
- Plan redirect mapping
- Run a full SEO audit
- Prioritise key pages for the migration and for testing
- Review your analytics setup
- Perform thorough benchmarking
Make sure you have access to the staging environment well in advance of the migration. Some of the key elements to test within your staging environment are URL mapping, status codes, indexability and load speed.
Keep all of your old crawls and speed test results from before the migration, as this will allow you to easily compare performance from before and after the migration.
It’s important to take on more of a project management role when planning a site migration, so take the time to build out your ultimate roadmap for all of the different teams, as the results of the migration will affect everyone else.
So excited for @exceldaddy to blow our minds by walking us through her experience with site migrations 🙌 Go on Serena!! 👏 #brightonSEO pic.twitter.com/FYgyRjYdKD
— Rachel Costello (@rachellcostello) September 13, 2019
Post-migration checks to make
Make it clear to everyone involved that the migration process isn’t over once the redirects have been implemented. There are so many important considerations and tests to be done to continue monitoring performance after the migration has been rolled out.
For example, these are some of the key questions to ask: Have all the pages moved over? Are the redirects working? Is all the on-page content there?
Here are some of the areas of investigation to guide your post-migration checks:
- Look at the code for a few key pages to assess JavaScript rendering and content accessibility, to determine how much content remains in the source code for search engines to access.
- Check the blocked resources report and Inspect URL Tool within Google Search Console to assess issues.
- Correctly configure URL parameters in the Parameter Handling Tool in Google Search Console for the new site.
- Run another full site audit, and use the code found in your old crawls to fill in any missing gaps on the new site. For example, in an emergency you can use the meta tags found in the crawl of the old site and upload those to the new site if they are missing.
- Review the performance benchmarks you set in the pre-migration phase and compare them to the performance of the new site.
Make sure you prioritise all of your key recommendations from your post-migration auditing to allow for lack of resource. It’s rare that everything on your list will be able to be implemented.
Reviewing the results of the migration
Once the migration rolls out, monitor performance on a daily basis at first, and then keep reviewing performance on a monthly basis.
Utilise clear, automated dashboards for reporting on performance to keep stakeholders up to date, as their sign off is critical for you to get the resource you need to implement fixes.
Traffic will always change after a migration, so don’t panic if this happens for your site. However, if things don’t settle down and you don’t start to see performance improvements after about a month, then something has probably gone wrong.
While traffic is naturally dropping in the early stages post-migration, focus on bounce rate and engagement metrics in your reporting instead to see how users are experiencing the new site.
One of the most important things to remember is that things never go to plan with migrations. Create templates and automate what you can, and also be patient with everyone you’re working with.
Ashley Berman Hale – Accessibility for people and bots: Compassion-led technical SEO
Talk summary
Ashley from DeepCrawl explained why we need to be more compassionate marketers, and how we can make sure that our websites are accessible and navigable for every person by implementing some key accessibility techniques.
Key takeaways
Why should SEOs care about accessibility?
Around 10-15% of people in the US have some kind of disability that affects how they use the internet. On top of this, so many of us also benefit from assistive technologies in some way. For example, think about whether or not you use closed captions when watching a TV show, or if you wear glasses or contact lenses to help you see better.
We should want to be good people and ensure that there are no barriers on our sites that impact how users access or interact with their content. Having equal access to the information on a site is a basic human right.
The added benefit of making our sites more accessible is that you will win over the hearts and minds of a new audience who will want to spend their money with you, so there can be a positive revenue impact.
Optimising for accessibility can also help you avoid legal implications, which are being more widely enforced.
The amazing @BermanHale is rocking the stage with a super important topic: accessibility #brightonseo 👌👏👀 pic.twitter.com/lh21q45NJV
— Aleyda Solis (@aleyda) September 13, 2019
How to incorporate accessibility into our workflows
SEOs have historically been taught that we have to take what someone else has built and make sure it’s crawlable, indexable and well-ranked. Our goal is basically to take a developer’s work and make sure it gets seen.
However, we should add another layer to this process to make sure that we are optimising for search engine visibility as well as human usability. Here’s what that new process should look like:
- Crawlable for search engines and accessible for users
- Indexable for search engines and navigable for users
- Well-ranked by search engines and shareable for users
Key considerations for website accessibility
Here are some of the key guidelines for making sure your website is more accessible to users with visual impairments:
- Have a contrast ratio of 4.5:1 as standard on your site, which you can test with the Contrast Ratio tool.
- Use safe fonts.
- Don’t use colour to convey meaning, such as using red for wrong and and green for right.
- Use descriptive links and alt text.
- Make sure the colours and size are configurable on your site to make them more accessible for screen readers.
- Make tables more user-friendly by using headers and providing summaries.
- Check how the site works when using a screen magnifier.
- Have audio-described versions of videos.
- Let users skip long menus so the screen reader doesn’t have to go through every element in a mega menu, for example.
- Don’t use iframes for core content.
Here are some of the main considerations for making sure your website is more accessible to users with auditory impairments:
- Some people find it harder to understand a male or female voice in particular, so look into the concept of Q, which is the first genderless voice.
- Add subtitles, closed captions or transcripts to your videos. This isn’t just important for accessibility, but for marketing as well because over 80% of people watch Facebook videos on mute, for example.
Here are some of the key considerations for making sure your website is more accessible to users with motor impairments:
- Don’t have elements that require a mouse to use them, such as onclick events or hover events.
- Use large link targets.
- Don’t auto play videos or audio.
- Don’t use shortcut keys as these are rarely compatible with screen readers.
- Extend session timeouts for people who are slower to navigate sites.
Fili Wiese – I keep thinking: My website can be faster!
Talk summary
Fili from Search Brothers shared his experiences of speeding up his own website, including the key challenges he faced along the way, as well as the methods he used to reduce load speed as much as possible.
Key takeaways
Where to host your website
When determining where to host his site, there were a few factors that influenced Fili’s decision. He wanted it to be reachable worldwide without having to be dependent on a single data centre. He also wanted to host it so that it could be close to where Googlebot crawls from in the US.
WordPress wasn’t the best option here as it comes with too much overhead and often adds more than you actually need to your site. Fili decided that he wanted to use connections within the Google network to make the site easier for Googlebot to access, so he hosted it within the cloud. He used Google App Engine in combination with Python to do this. By using this serverless approach, you are able to avoid additional server maintenance as well.
The biggest factors that impacted site speed
Some of the biggest challenges that Fili faced when optimising his own site were cookies, web fonts and the time taken for layout rendering. The number of requests on the site was at a good level, but load speed was still slow due to cookies which were validating user activity server-side without going through the CDN which was delaying page load.
To get around this, you can add some vanilla JavaScript to your site for managing cookies and make the file cacheable. You can also tie cookies to the JavaScript by using the noscript tag so that you aren’t served cookies if you don’t have JavaScript enabled. Despite missing out on tracking a small number of users, this can cause a significant decrease in load time.
Implementation tips for speeding up websites
It’s our responsibility to make sites faster for our users, and we need to keep optimising and testing our sites on a continual basis. You’ll always find that there is more that you can do to improve page load speed, which is what Fili found for his site.
Here are some of the different things you should look into for speeding up your own site:
- Maintain a mobile-friendly and mobile-focused mindset.
- Make sure your site adheres to the concept of progressive enhancement, so that JavaScript isn’t necessary for the end-user’s experience.
- Use HTTP/2 which allows you to serve content over a single connection.
- Utilise resource hints to give more instructions to the browser on what to load as a priority.
- Use instant.page to implement custom prefetching of internal links, so the HTML of a destination page will be fetched when a link to it is hovered over.
- Look into increasing server resources, as more server power can improve the average response time.
- Use a resource budgeting approach and check your site against the Google Chrome team’s ‘Never-Slow Mode’ list, which sets ideal budgets for resource file sizes of images, scripts, connection times, and more.
- If you’re using Python, then look into frameworks and libraries like Flask-Cache which utilises caching to save elements of the page in the memory of the server so full page rendering isn’t required with each page load.
You can also use uSWGI which can connect to Flask-Cache.
Best talk of the day from @filiwiese with practical tips that aren’t the same old advice #BrightonSEO pic.twitter.com/M7JqF3haqx
— Lauren Keeling (@lauren_keeling) September 13, 2019
Jan-Willem Bobbink – What I learned about SEO from building websites with the 10 most used JS frameworks
Talk summary
Jan-Willem from Notprovided.eu spoke about how the web is rapidly evolving towards using more and more Single Page Applications and JavaScript driven websites. Instead of depending on clients’ issues with SEO and debugging those, Jan-Willem used the 10 most popular JavaScript frameworks himself to setup 10 websites and share the expected and unexpected things that happened.
Key takeaways
JavaScript is the future, as more developers are continuing to adopt it and use it to build websites with. Over the last 3 years, the web stacks of Jan-Willem’s clients that included JavaScript frameworks increased from 28% to 65%.
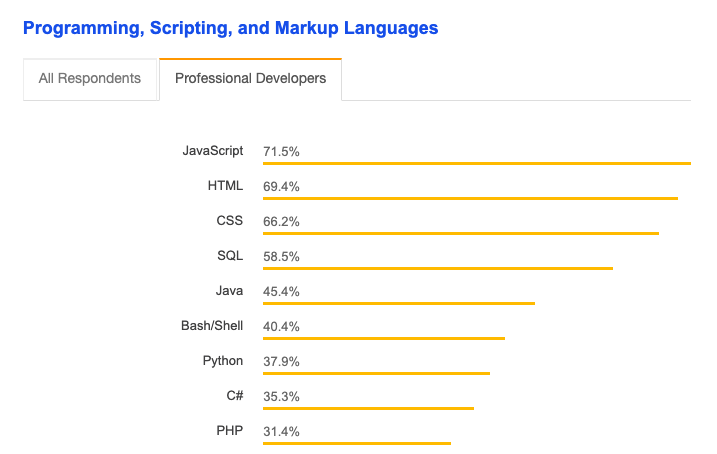
Source: Stack Overflow
The key challenges of JavaScript
Here are some of the main issues that Jan-Willem has encountered in his work with JavaScript:
- Googlebot is not a real user and always starts with a clean browser with no history, as it can’t use cookies, local storage or session data after the first visit to help improve load times.
- Full client-side rendering should always be avoided as it impacts performance for both users and search engines. This is why you should implement server-side rendering.
- However, server-side rendering can skew analytics data and double log page views, so watch out for this.
- When using third-party rendering tools to implement server-side rendering, dynamic rendering or hybrid rendering, these can easily break so set up monitoring to make sure your site is always being rendered correctly. Make sure the correct 503 HTTP response is being sent when the server is experiencing issues.

Source: Google Developers
Tools for testing JavaScript
These are the main tools that Jan-Willem recommended using to test rendering performance:
- Use the URL Inspection Tool for owned domains.
- Use the Rich Results Testing Tool for domains you don’t own.
- Use the View Rendered Source plugin.
- Use Chrome DevTools to select the Googlebot user agent to see how it is able to render and what content it can access.
- Use log files to check that search engines are able to access all the JavaScript files that are required to render a page’s full content.
- Use SEORadar to render a page once with Googlebot desktop and once with Googlebot smartphone to show the differences between what was fetched for each user agent.
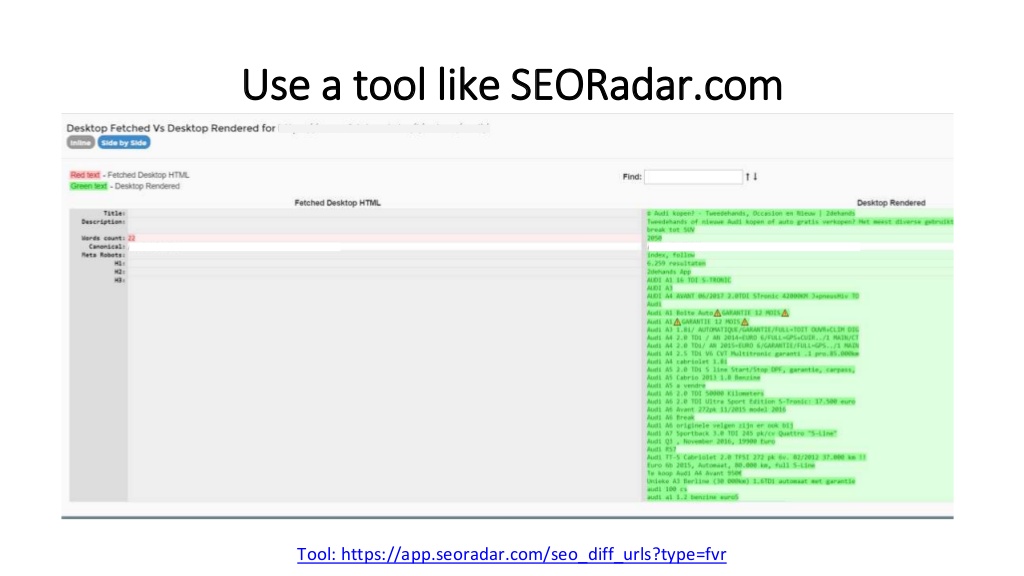
JavaScript optimisation tips
Here are some tips on optimising the JavaScript on your site and making sure that it doesn’t impact performance:
- Key content like page titles, meta descriptions, heading tags, canonicals and structured data need to be included in the HTML, rather than being rendered using JavaScript.
- Reduce the amount of JavaScript on a page where possible to increase performance, as the scripts are often heavy and difficult to process and execute.
- Using tree shaking to remove the JavaScript you’re not using on specific pages.
- Caching is really important as server-side rendering can be expensive to implement.
Jamie Alberico – Think like a bot, rank like a boss: How Googlebot renders
Talk Summary
Jamie took us on a journey to experience site content as Googlebot. In this session, we learnt how the web crawler builds a page, ways to improve the search engine’s understanding, and tactics to navigate the divide between the HTML and DOM.
Key takeaways
It’s our responsibility as SEOs to protect our site visibility by making sure our content gets delivered to Google’s index. Rendering can put this goal at risk, because if Googlebot can’t render our content, visibility and performance will suffer.
Due to Google’s two waves of indexing, where there is a delay between indexing HTML pages and JavaScript pages, pages that need to be rendered can get stuck in the rendering queue meaning that fresh content won’t be able to be indexed immediately.
How Google’s Web Rendering Service (WRS) works
Google’s WRS performs actions by using multiple threads which are made up of different requests. This makes up crawl budget, which refers to the number of connections Google makes when crawling through a site.
How the process of rendering works for Google:
- A URL is pulled from the crawling queue.
- The URL is requested and the HTML is downloaded.
- The HTML is parsed to extract links which are added back into the crawling queue.
- If the page needs to be rendered to be able to extract content, the page is added to the separate rendering queue.
- When resources become available, Chromium is used to render the page.
- The rendered HTML is parsed to extract links which are added into the crawling queue.
- The rendered content is indexed.
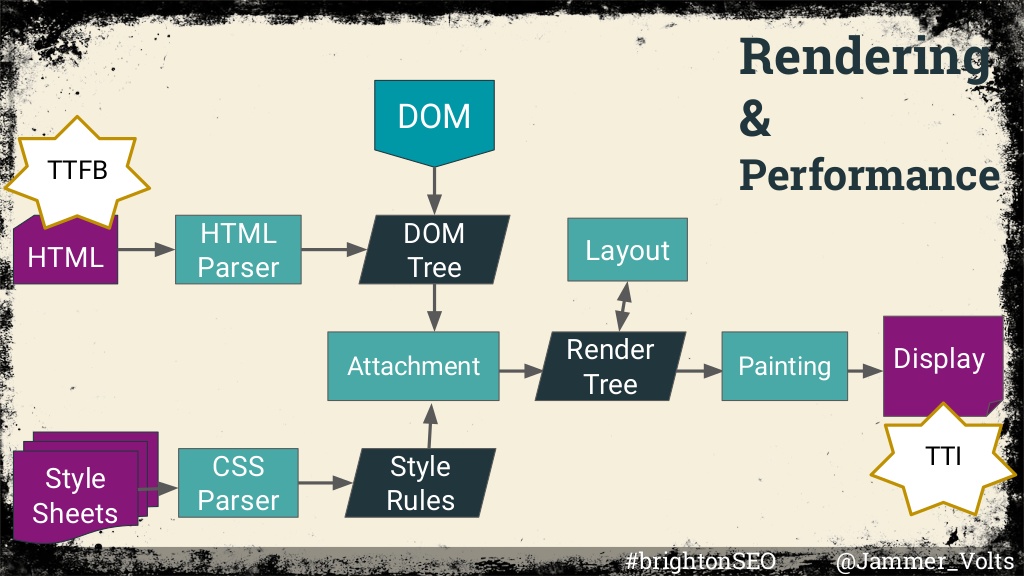
The WRS is also stateless, meaning that it doesn’t retain any cookies or local storage. It also uses the rendering engine, Blink, the JavaScript engine, V8, and Chromium for rendering, which is a headless browser, so it doesn’t have any UI or visual elements.
Googlebot wants to be polite and aims to be “a good citizen of the web,” and bases its crawl rate on server stability. It will pull back on crawling if it sees server errors to avoid overloading your site.
How to optimise JavaScript-powered sites for Googlebot
Here are some of the things you can do to ensure Googlebot is able to access and understand your JavaScript content:
- Parse the hero content that is critical to the end-user within the initial HTML.
- Focus on loading crucial content sooner with progressive enhancement.
- Use async defer to delay the loading of non-essential scripts.
- Use clean and consistent signals and don’t contradict yourself between the HTML code and rendered content.
- Maintain consistency in content across desktop and mobile.
- Cut down the number of resources being used and requests being made where possible, as this increases page size and increases load time.
- Perform testing to check for rendering traps.

One of the most important things you can do is to make friends with developers. That way you can strengthen your team and make more informed decisions around handling the JavaScript on your website and mitigating any risks.
Rory Truesdale – Mining the SERPs: How to make the SERPs a powerful weapon in your SEO armoury
Talk summary
Rory from Conductor explained how the language of the SERPs can be deconstructed and analysed using Python to get clues on what Google thinks your customers want, and how these insights can be used to improve the performance of your SEO campaigns.
Key takeaways
Based on a study run by Conductor, Google rewrites 84% of SERP-displayed meta descriptions; meaning the meta description shown in a SERP often differs from the one defined in the HTML of the ranking page.
This process of algorithmic rewriting makes sense. Google has a huge amount of data available to it to help it understand exactly what a user wants when they search for a query. In its effort to deliver the best quality search results, Google will cherry pick the content from landing pages that it thinks best meet the needs of the searcher.
By employing Python scripts within Jupyter Notebook, which were made accessible via this Dropbox link, we can take content that has been scraped from the SERPs or pulled via an API and analyse linguistic trends. This can provide us with valuable insights into how Google is interpreting intent and query context, which can be applied to improve on page content performance.

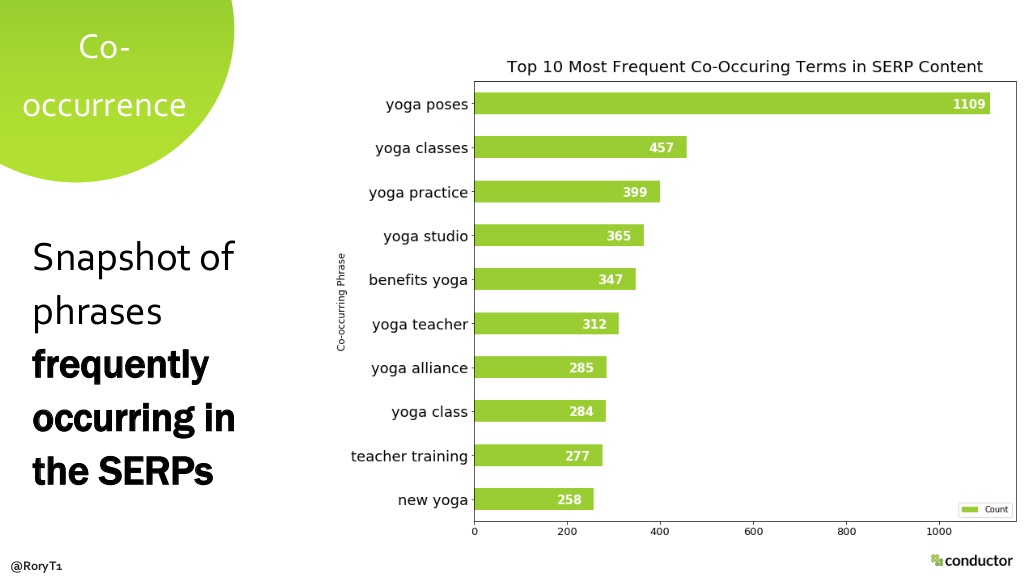
N-gram co-occurrence
The first analysis used n-gram co-occurrence; this is a count of the most frequently occurring words or combinations of words in a SERP. The output of this analysis is a snapshot of the most common terms in the SERPs for a target set of keywords.
This can help demonstrate topical content gaps on important landing pages and also the words or phrases that Google might see as semantically or contextually relevant to a target keywords.
The analysis can be used to help structure on-page optimisation and to help provide data to reinforce an argument to design or product teams about how landing pages should be structured.
Part of speech tagging
Part of Speech (PoS) tagging is an extension of co-occurrence analysis, but means that you can drill into these trends for specific types of words (nouns, verbs, adjectives etc.) These linguistic trends can provide interesting insights into the type of language that might resonate with a searcher and Google is interpreting intent.
- Nouns: A drilldown of the most common nouns in a SERP can provide more insight into the topics or entities that top ranking competitors are writing about on their top performing landing pages.
- Verbs: Can be analysed to help provide insight into how Google is interpreting searcher intent, or more specifically, the specific motivation they have when they search for a query on Google.
- Adjectives: These descriptive words can be used to identify the type of language that might resonate with an online audience and can be used to inform landing page CTAs.
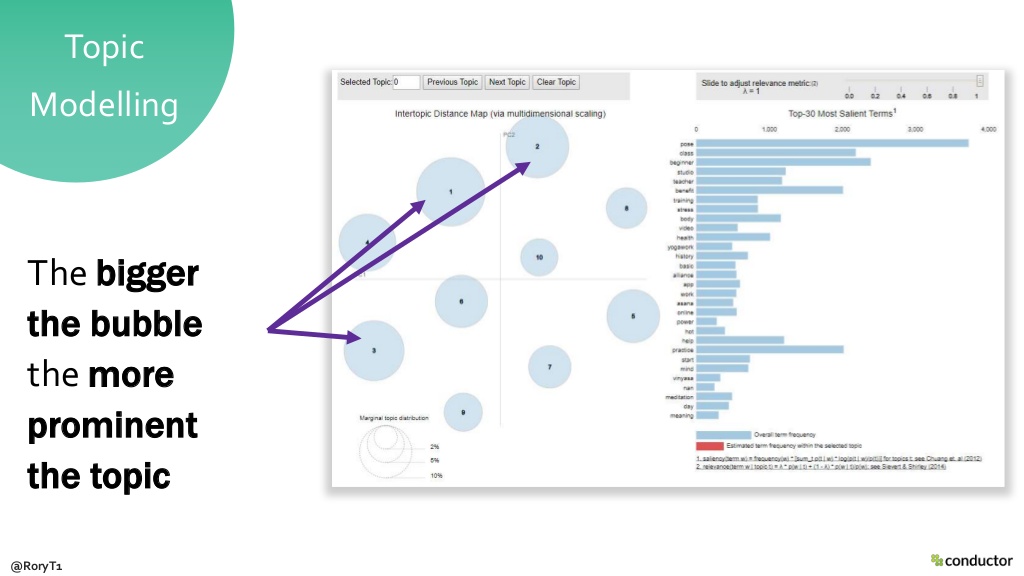
Topic modelling
Topic modelling is the process of using natural language processing (NLP) to identify topical groups within a corpus of text (in this case the SERPs). This process means you can rely on Google’s search algorithm to identify trends into the topics it thinks are of interest to the audience you are trying to reach through organic search.
The output is an interactive visual that represents topics as bubbles and lists the top 30 most salient/important keywords within a topical grouping. This analysis can be useful for content ideation, defining the pillars of a content strategy and to inform internal linking and content recommendations across a website.
Other uses for scripts
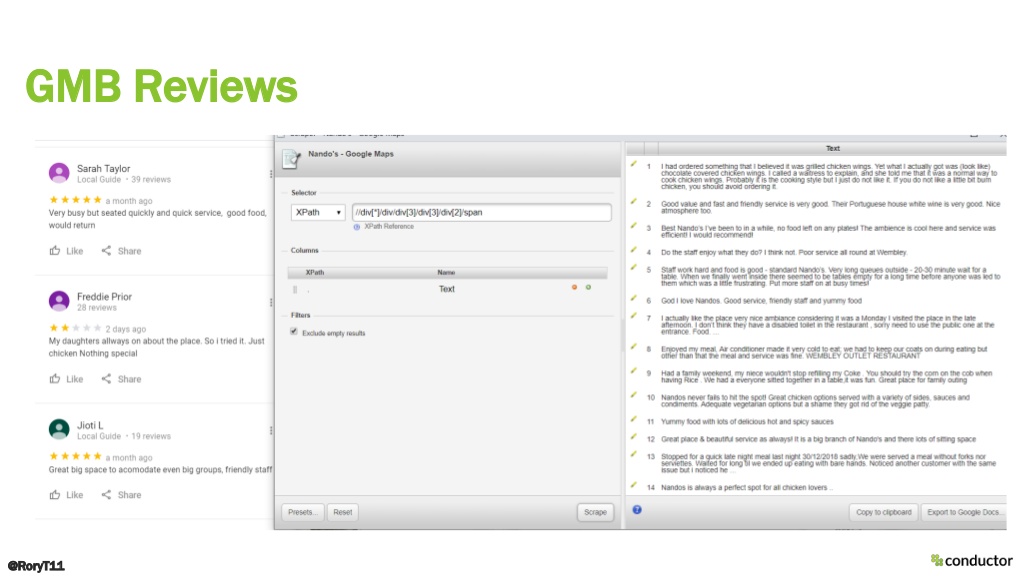
The talk finished by demonstrating that the scripts can be used to perform the same analysis on a range of user-centric content sources that have been created for your audience or by your audience.
These included product reviews, GMB reviews, Reddit, YouTube captions and top ranking landing pages. This can be used to generate valuable insights that can provide useful business insights that can be owned by the SEO.
Dan Taylor – How serverless technologies can help SEOs overcome legacy (and modern) tech obstacles
Talk Summary
Dan from SALT Agency talked through “edge SEO” and how we can implement technical fixes through the CDN without affecting the underlying codebase and tech stack. This method can enable SEOs to overcome insurmountable obstacles, or apply temporary fixes whilst the end-goal solutions work through a congested development queue.
Key takeaways
The importance of edge SEO
The concept of edge SEO has taken off within the industry because of its ability to help you get around platform restrictions, congested development queues, and a lack of buy in for SEO fixes to help your actions get prioritised and implemented.
Edge SEO means using edge computing technologies to create new SEO implementation methods, testing and research processes outside of the current parameters in which we operate.
By using edge SEO methods, SEOs can regain a level of control over implementing fixes, and have access to a one-click deployment and rollback system which doesn’t require DevOps resource.
What you can do with edge SEO
Here are just a few of the things you can implement with edge SEO:
- Collecting log files
- Implementing redirects
- Overwriting hardcoded metadata
- Pre-rendering JavaScript
- Implementing hreflang tags
- Solving cold caching issues
- Performing A/B testing
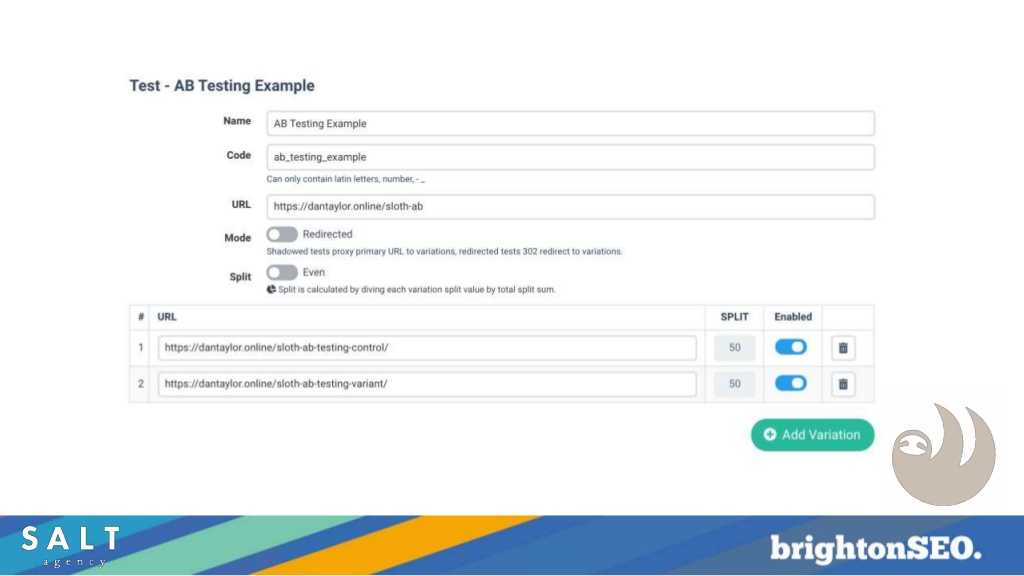
Edge SEO tools
These are some of the different tools you can use to implement edge SEO for your site:
- Cloudflare
- Akamai
- Fastly
- Sloth
- Spark
- Logflare
- Distilled ODN
Implementing new processes
New technologies need new processes to mitigate risks. For example, most developers don’t know enough about serverless technologies, and SEOs don’t know enough about how the changes they’re making via edge SEO can impact the code already being pushed via the server.
These are some of the new processes that should be followed to ensure consistent website performance and smooth releases, as well as adding accountability and responsibility:
- Development and release management
- A debugging process to minimise front-end bugs
- Performance monitoring to avoid latency
- Security and compliance checks
Make sure access to your CDN is restricted to only those who know exactly what they are doing. Misusing Cloudflare can bring an entire site down so always use it with caution.
To hear Dan go into more depth on this topic, then take a look at the recap of our webinar on edge SEO that we held with him earlier this year.
Aysun Akarsu – Web server logs as a technical SEO key data source
Talk Summary
Aysun’s talk covered everything about how server logs can assist with technical SEO tasks. This informative session provided answers to questions about how to analyse web server logs and explained concepts such as crawl distribution.
Key takeaways
With more than 10 years of experience in technical SEO, Aysun works as a freelancer who excels in SEO data analysis.
The importance of web server logs
There are many data sources in technical SEO but two are essential:
- Web server logs
- Crawl data
However, if Aysun had to choose one data source it would be server logs because a crawl of a website is like a photo we take of a moment in life. It doesn’t tell you enough about the past of a website. Server logs are the life of the website, including its past, present and future.
What are web servers?
A web server is simply a computer that provides data to other computers. There are different clients, mobile and desktop, which send HTTP requests and servers answer these requests with an HTTP response.
According to Netcraft, the market share of web servers is split between Apache, nginx, Google and Microsoft. Often you can identify web servers using cURL and live HTTP on Chrome but sometimes this information may be hidden. There are also some cool apps that identify servers, such as Wappalyzer. Netcraft can also tell you about historical usage of servers on a site.
What is a log file
A log file simply tracks HTTP requests and HTTP responses on a server. A log file entry includes:
- Client’s IP address
- Time the server finished processing the request
- Request line from the client
- Certificate
- Size of the object returned to the client
- Referrer
- User agent
Log files can show you the trends and seasonality of a site. They can also help us to make predictions as to how trends might change in the future.
Make sure the amount of data you have goes back far enough to account for large sites with crawling issues which may need more than a month of data. From experience, Aysun recommends having at least 4 months worth of data when analysing historic data and at least 24 months worth of data when making predictions about future trends.
Collecting, parsing, storing and visualising server logs
Aysun recommends sending new clients a questionnaire asking them about how far back their server logs go and if they have changed the format of their server logs. It is also a good idea to request the required fields of the elements of the log files that you are expecting, receive a sample, and check that the sample includes your required data.
At this stage you should specify the number of month’s worth of data you require and collect them. When you collect the server logs you need to verify if all of them have been collected by looking at all the active pages in log files vs Google Analytics to see if all of the important pages are included.
You can parse web server logs using command line or Python. You can use this Python library to help you parse apache logs. You can then store these logs in any number of places including BigQuery, Redshift, Haddop or PostgreSQL.
With analysis of past server log data you can visualise trends, seasonality and repeated cycles. We can use this information to inform questions around when it is best to go ahead with a migration, for example.
It is worth analysing data distributions to see how these vary across different areas of your website such as categories.
Read the final part of our BrightonSEO recap
If you’ve enjoyed reading part 1 and part 2 of our recaps, the fun doesn’t stop here. We have a final recap post in store for you which covers even more of the excellent talks that were given during the September 2019 edition of the conference.



